前回に引き続き、Google Colaboratoryを使いますが、今回はKerasによるConvolutionやMaxPoolingのレイヤーパラメータの詳細な設定方法がかなり分かってきたので、CNN(畳み込みニューラルネットワーク)を独自に組んで機械学習させてみます。
そして、私自身の解釈で理解したレイヤーパラメータの設定方法を紹介したいと思います。
改めて、今回の記事を書いていて思った事は、TensorFlowやKerasというものはビギナー向けでは無く、ある程度の中堅者~熟練者向けのディープラーニングツールだと思いました。
各層のパラメータ設定が難解でした。
TensorFlowやKerasの情報は、ネット上ではかなり沢山あり、公式ドキュメントもありますが、どうもあまり理解できなくて、自分の予測値と実行結果とが異なることが多かったのです。
特に、パディング(Padding)設定がどうしても意図した結果にならず悩んでいました。
Kerasを使い始めた最初の頃、私は公式ドキュメントをサラっと読んで理解した気になっていましたが、しばらく使っていると誤って解釈していたことが多々ありました。
そして、いろいろ調べていくうちに、Kerasのドキュメントで解決できない場合は、TensorFlowの公式ドキュメントも参照すると、解決できたということがありました。
結局のところ、最終的にたどり着いた解決方法は公式ドキュメントだったということです。
Paddingについては、ネット上の情報では殆どがゼロパディングされると書いてありますが、実際は違っていて、ゼロパディングとは限らないことが判明しました。
また、TwitterなどのSNSもひとつの解決ツールでしたね。
公式ドキュメントをいくら読んでも分からなかったものの一つに、data_formatという設定がありました。
後で詳しく述べていますが、Twitterで何気に疑問点をつぶやいていたら、答えを教えてくれる方がいらっしゃったんです。一発で解決です。
改めてTwitterってスゲーなと思いました。
けりさん、その節はありがとうございました。
m(_ _)m
それに、今回、このブログを書いている途中でいろいろな発見がありました。
ただ単にGoogle Colaboratoryを自己満足で使っただけでは恐らくスルーしてしまうことも、ブログを書くという行為で、ちょっとだけ深く知ることが出来たのは大きな収穫でした。
ということで、私の個人的解釈で、Kerasのレイヤーについていろいろ述べてみたいと思います。
何しろTensorFlowやKerasは初心者ですので、間違えていたらコメント投稿で教えて頂けると助かります。
- まずはSONY Neural Network Console でCNNを組んで確認しておく
- Google ColaboratoryのKerasで独自のCNNを組んでみる
- レイヤー単独で出力結果を確認する方法
- テンソル(Tensor)とNumPy配列の違い
- レイヤー引数パラメータについて(個人的見解を含む)
- パディング(padding)の謎
- 学習済みモデルをHDF5形式でGoogle Driveに保存する
- Googleドライブに保存したHDF5形式の学習済みモデルを読み込む
- まとめ
【目次】
事前準備
前回の記事を参照して、事前にGoogle Colaboratoryのセットアップを完了させて、使える状態にしておきます。
1.まずはSONY Neural Network Console でCNNを組んで確認しておく
SONY Neural Network Consoleというものは、直感的なニューラルネットワーク構築が簡単にできるツールなので、Kerasと共に使い分けるといろいろと設計の幅が広がるような気がします。
まず、以前のこちらの記事にあるようにSONY Neural Network Consoleで作ったCNN(畳み込みニューラルネットワーク)をおさらいします。
これは、我ながら良くできたCNNだと思っています。
2000 epochsで学習させた結果、98%の正答率を叩き出したCNNです。
(図01_01)

右側にある数字は、出力した配列のshape(要素数)です。
これはchannels_firstで表示されています。
Google ColaboratoryのKerasの場合は、出力ニューロン(ノード)のことをチャンネルと呼びます。
それが最初に表示されるという事です。
第1層目のConvolutionの左側に(5, 25, 25)とあるのは、チャンネル(ニューロン)が5個、出力が25×25という意味です。
では、コスト(重みとバイアスの総数)を見てみると、以下です。
(図01_02)

コストの総数、つまり、重みとバイアスデータの総数は650個です。
各レイヤー(層)のパラメータについては以下です。
(図01_03)
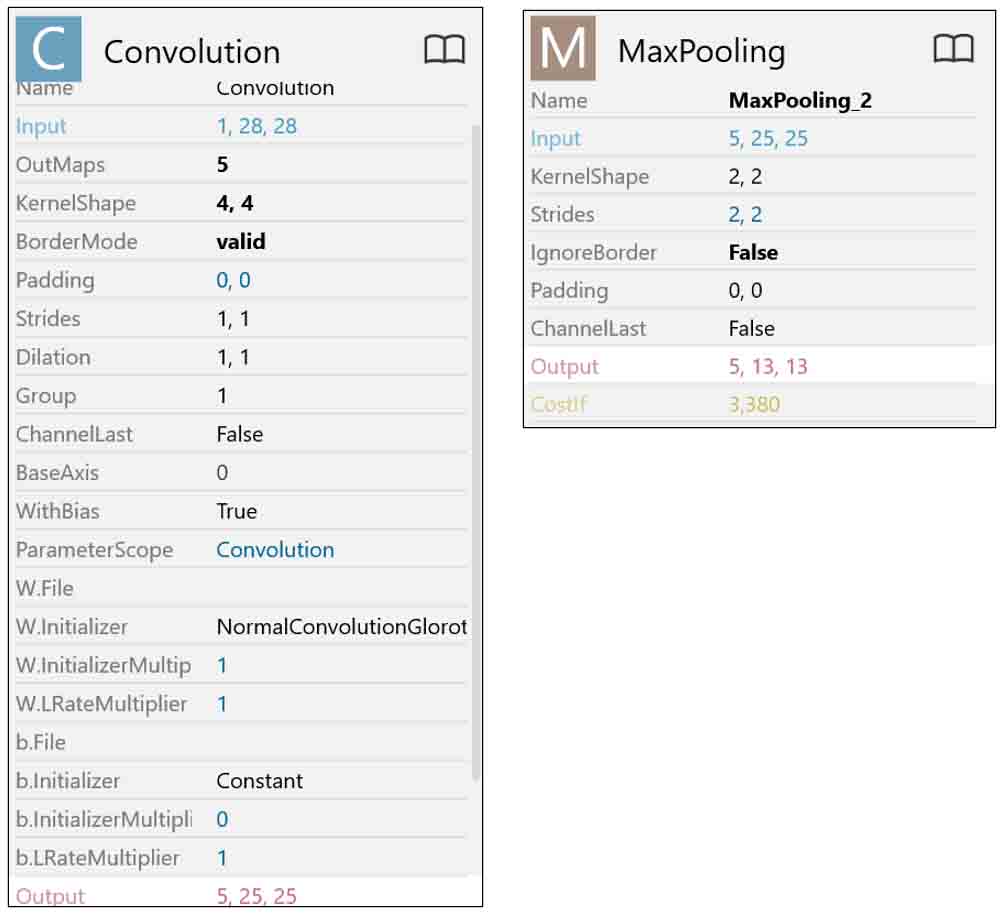
(図01_04)
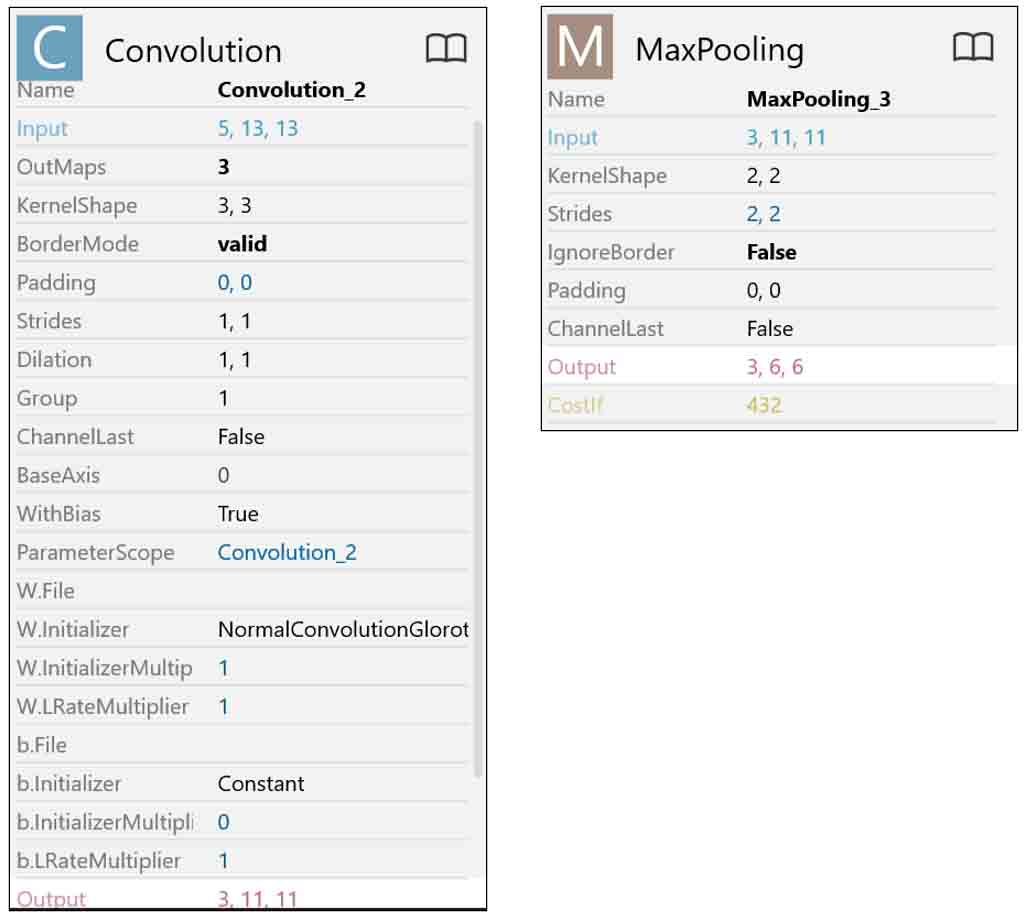
(図01_05)
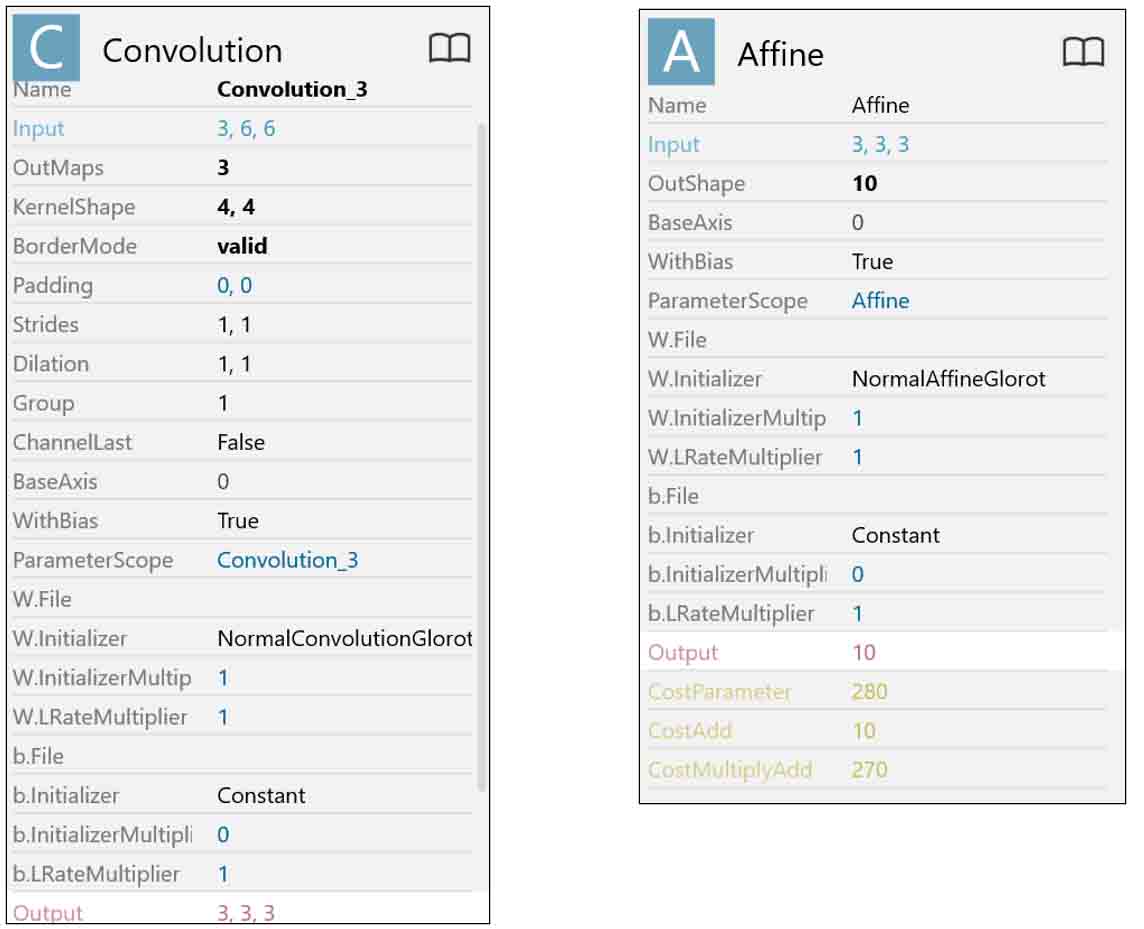
このパラメータはGoogle ColaboratoryのKerasとは互換性が無いものがあり、注意が必要です。
では、これを基にGoogle ColaboratoryでCNN(畳み込みニューラルネットワーク)を組んでみます。
2.Google Colaboratory のKerasで独自のCNNを組んでみる
では、Keras公式ドキュメントを参考にしながら、先のCNN(畳み込みニューラルネットワーク)をGoogle Colaboratoryで組んでみます。
2-01. 手書き数字MNISTデータセットを読み込んで、プロット表示させてみる
まずは、Google ColaboratoryのKerasで手書き数字データセットを読み込み、ちゃんと読み込まれているか確認するために、実行セルにプロットして画像表示させてみます。
# TensorFlowとKerasのインポート
import tensorflow as tf
import keras
# 手書き数字MNISTデータセットのインポート
from keras.datasets import mnist
from matplotlib import pyplot
# kerasのバージョン確認
print('keras version ',keras.__version__)
# 手書き数字MNISTデータを読み込み
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
# 画像データの次元確認
print('train_images shape =', train_images.shape)
# 画像データ16件をキャンバスに2行8列で白黒で出力
for i in range(0, 16):
pyplot.subplot(2, 8, i + 1)
pyplot.imshow(train_images[i], cmap='gray')
pyplot.show()
このセルを実行するとこうなります。
これは、60000件の画像データのうち、一部のみプロットしています。
(図02_01_01)
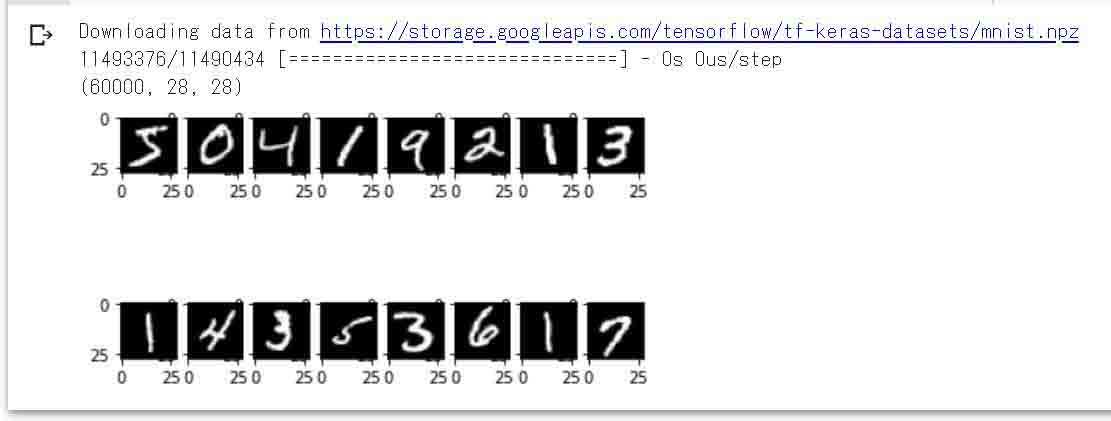
from keras.datasets import mnistで手書き数字データセットをインポートし、mnist.load_data()だけで、学習用画像データとラベルデータ、評価用画像データとラベルデータのそれぞれの配列に変換してくれます。
あとは、matplotlibで画像データをプロットして、データがちゃんと読み込まれているか確認しています。
2-02. 正解ラベルデータをone-hotベクトルに変換する
次に、正解が記述されているラベルデータをone-hotベクトルに変換して表示させてみます。
one-hotベクトルとは、たぶんビギナーには意味不明だと思います。
以前、Excelでディープラーニングのお勉強の記事その2、その3で扱ったように、最終的に出力された確率的なデータから、正解データと平方誤差を取って、誤差の最も少ない数値を判定結果としました。
その時と同じように、予め入力画像の正解ラベルが5と設定されていた場合、以下のような配列に置き換えます。
5 → [0, 0, 0, 0, 0, 1, 0, 0, 0, 0]
つまり、配列の5番目の要素を1とするわけです。
正解ラベルが0の場合は以下のように配列の0番目の要素を1とすれば良いわけです。
0 → [1, 0, 0, 0, 0, 0, 0, 0, 0, 0]
これが理解できれば、以下のコードを組むだけで正解ラベルデータをone-hotベクトルに変換できます。
変換したone-hotベクトルは最初の3つだけ表示させています。
(※ネット上の情報ではnp_utilsを使う例が多いのですが、現在、APIが変わったのでnp_utilsは使わない方が良いです。)
# ラベルデータをone-hotベクトルに変換
# np_utilsはAPIが変わったので使わない事
# https://keras.io/ja/utils/#to_categorical
train_labels = keras.utils.to_categorical(train_labels.astype('int32'), 10)
test_labels = keras.utils.to_categorical(test_labels.astype('int32'), 10)
# ラベルデータの要素確認
print('train_labels shape =', train_labels.shape)
# ラベルデータ3件だけ表示
for i in range(0, 3):
print(train_labels[i])
このセル単独で実行する時は要注意です。
なぜか、下図のように
shape=(60000, 10, 10)
となってしまって、次元が1つ増えています。
(図02_02_01)

これだと、意図した結果にならず、意味不明です。
改めて、「全てのセルを実行」させると、以下のように
shape=(60000, 10)
となって、正しく表示されました。
(図02_02_02)

この原因はいくら調べてもわかりませんでした。
これはGoogle Colaboratoryビギナーにとっては悩ましい問題ですね。
こういうもんだと思うしかないです。
2-03. 画像データの整数配列を0~1.0までのfloat型配列に正規化する
次に、KerasのCNN(畳み込みニューラルネットワーク)モデルに画像データを入力する前に、正規化という前処理を行います。
まず、Kerasのレイヤーの仕様に合わせるために、画像データの次元を1つ増やす作業をします。
元のMNIST画像データは3次元配列で、shape(要素数)は
(60000, 28, 28)
です。
これを4次元配列にして、
(60000, 28, 28, 1)
とします。
これは白黒画像の場合です。
RGBのフルカラー画像の場合は、
(60000, 28, 28, 3)
となります。
そして、重要なのが、Kerasの場合、デフォルト設定ではチャンネルラスト(channels_last)になっていることに注意が必要です。
個人的な普通の感覚ならば、RGB3色で28×28 pixelの画像の場合、shapeは
(3, 28, 28)
となると思いますが、その3チャンネル(ニューロンまたはノード)が最後の要素になっていることです。
channels_lastというデフォルト設定では、私自身が混乱するので、後でchannels_firstに設定し直しますが、この段階ではまだchannels_lastのままで進めていきます。
次に、画像データは0~255の整数データなので、0.0~1.0のfloat型に変換します。
なぜそうするかと言うと、Excelでディープラーニングのお勉強その1、その2、その3を見てもらえれば分かると思うのですが、最終判定する時は確率で判定しています。
そうすると、0.0~1.0の範囲に収めた方が、都合が良いのです。
データを0.0~1.0の範囲に変換することを正規化というらしいです。
標準化と言っているところもあるようですが、どちらが正しいのか私には解りません。
ということで、画像データ配列の次元を1つ増やし、値を正規化すると、以下の感じになります。
# shapeが(60000, 28, 28)を(60000, 28, 28, 1)に次元を増やす。
# KerasでCNN演算行う場合、デフォルトがchannels_lastになっていることに注意。
# 因みにRGBカラー画像だと、(60000, 28, 28, 3)となる。
# train_images.shape[0] = 60000
train_images = train_images.reshape(train_images.shape[0], 28, 28, 1)
test_images = test_images.reshape(test_images.shape[0], 28, 28, 1)
# 次元の確認
print(train_images.shape)
# 整数型の画像データをfloat型に変換
train_images = train_images.astype('float32')
test_images = test_images.astype('float32')
# 学習のために0~255の整数値を0~1.0の範囲に収めるために、全要素を255で割る
train_images = train_images / 255.0
test_images = test_images / 255.0
train_images.shape[0]という小難しい値を使っていますが、ネット上にそういう情報があったので使ってみました。
ただ単に、
train_images.shape[0] = 60000
という意味です。
ここで、NumPy配列の威力を感じることが出来ると思います。
train_images = train_images / 255.0
というようにC言語では有り得ない配列計算が一括でできてしまいます。
60000件の画像データを一括で正規化できるのは便利ですね。
これで、手書き数字MNISTデータの前処理終了で、CNNモデルへインプットするデータが整いました。
2-04. CNNレイヤーモデル構築
では、入力データの前処理が済んだところで、いよいよCNNモデルを組んでいきます。
CNNモデルは途中で分割して結果を見ることが難しく、Jupyter Notebook 1セルにCNNモデルを組み上げていきますので、少々長いコードになります。
また、ネット上の多くの簡単なサンプルコードでは、各レイヤー(層)のパラメータがデフォルト値で省略されていますが、ここでは、前節のSONY Neural Network Consoleで組んだパラメータと揃えるために、あえて引数パラメータを全て表記しています。
ですから、見た目が長いコードになっています。
# MNIST CNNモデル構築
from keras.models import Sequential # Sequentialモデルとはモデルを積み重ねたもの
from keras.layers import Conv2D, MaxPooling2D
from keras.layers import Dense, Flatten, Activation
import numpy as np # NumPyモジュールをインポート
# MNIST画像データをchannels_firstにする為に次元を入れ換え
train_images = np.transpose(train_images, [0, 3, 1, 2])
test_images = np.transpose(test_images, [0, 3, 1, 2])
# CNNモデルを構築
model_cnn = Sequential()
#layer0
output_channels = 5
model_cnn.add(Conv2D(output_channels,
kernel_size=(4, 4),
strides=(1, 1),
padding='valid',
data_format='channels_first',
input_shape=(1, 28, 28),
dilation_rate=(1, 1),
activation=None,
use_bias=True,
kernel_initializer='glorot_normal',
bias_initializer='ones',
kernel_regularizer=None,
bias_regularizer=None,
activity_regularizer=None,
kernel_constraint=None,
bias_constraint=None,
name='conv1'))
#layer1
model_cnn.add(MaxPooling2D(pool_size=(2, 2),
strides=(2, 2),
padding='same',
data_format='channels_first',
name='maxpool1'))
#layer2
model_cnn.add(Activation('tanh'))
#layer3
output_channels = 3
model_cnn.add(Conv2D(output_channels,
kernel_size=(3, 3),
strides=(1, 1),
padding='valid',
data_format='channels_first',
dilation_rate=(1, 1),
activation=None,
use_bias=True,
kernel_initializer='glorot_normal',
bias_initializer='ones',
kernel_regularizer=None,
bias_regularizer=None,
activity_regularizer=None,
kernel_constraint=None,
bias_constraint=None,
name='conv2'))
#layer4
model_cnn.add(MaxPooling2D(pool_size=(2, 2),
strides=(2, 2),
padding='same',
data_format='channels_first',
name='maxpool2'))
#layer5
model_cnn.add(Activation('tanh'))
#layer6
output_channels = 3
model_cnn.add(Conv2D(output_channels,
kernel_size=(4, 4),
strides=(1, 1),
padding='valid',
data_format='channels_first',
dilation_rate=(1, 1),
activation=None,
use_bias=True,
kernel_initializer='glorot_normal',
bias_initializer='ones',
kernel_regularizer=None,
bias_regularizer=None,
activity_regularizer=None,
kernel_constraint=None,
bias_constraint=None,
name='conv3'))
#layer7
model_cnn.add(Activation('tanh'))
#layer8
model_cnn.add(Flatten(data_format=None, name='flat1'))
#layer9
output_channels = 10
model_cnn.add(Dense(output_channels,
activation=None,
use_bias=True,
kernel_initializer='glorot_normal',
bias_initializer='ones',
kernel_regularizer=None,
bias_regularizer=None,
activity_regularizer=None,
kernel_constraint=None,
bias_constraint=None,
name='dense1'))
#layer10
model_cnn.add(Activation('softmax'))
重要なのが、8-9行目で、画像データをchannels_firstに次元を入れ換えています。
そして、各レイヤーのdata_format設定でchannels_firstにしていることです。
data_format設定については、5章で詳しく述べます。
また、その他の各レイヤーの引数パラメータについては、それぞれ言及したいことが山ほどあるため、それについても5章で説明します。
2-05. 学習および評価をし、正答率を確認する
前節でCNN(畳み込みニューラルネットワーク)構築できたので、そのモデルに正規化したMNIST手書き数字データセットを入力して、学習および評価させてみます。
Jupyter Notebookの「編集」→「ノートブックの設定」でハードウェアアクセラレータをGPUに設定することを忘れないでください。
忘れると学習時間がとんでもなく長時間になって、12時間ではとても終わりませんので注意してください。
そして、8章で述べていますが、学習終了後にCNNモデルを外部ストレージに保存して置くことをお勧めします。
8章を参照して、予めGoogleドライブをマウントしておいてください。
新たにコードセルを追加して、以下のコードを入力します。
import matplotlib.pyplot as plt
# モデルをコンパイル
model_cnn.compile(
loss='categorical_crossentropy',
optimizer=tf.keras.optimizers.Adam(),
metrics=['accuracy'])
# 学習を実行する
hist = model_cnn.fit(train_images, train_labels,
batch_size=64,
epochs=2000,
verbose=1,
validation_data=(test_images, test_labels))
model_cnn.summary()
# モデルを評価する
score = model_cnn.evaluate(test_images, test_labels, verbose=1)
print('正解率=', score[1], 'loss=', score[0])
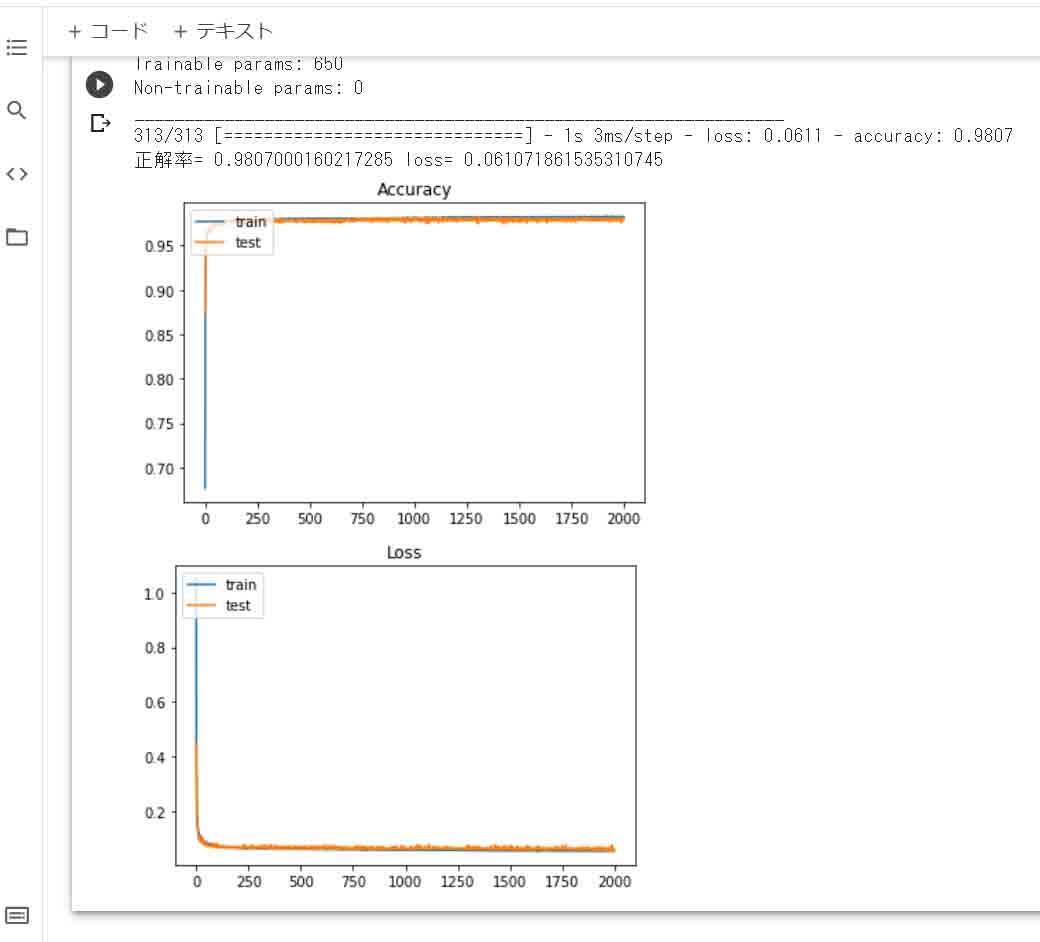
# 学習の様子をグラフ表示
plt.plot(hist.history['accuracy'])
plt.plot(hist.history['val_accuracy'])
plt.title('Accuracy')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
# ロス値をグラフ表示
plt.plot(hist.history['loss'])
plt.plot(hist.history['val_loss'])
plt.title('Loss')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
# 学習済みモデルをh5形式ファイルでGoogleドライブに保存
model_cnn.save('/content/drive/MyDrive/colab_my_data/my_model.h5')
import matplotlib.pyplot as pltは、学習経過をグラフ化させるためのライブラリ matplotlibをインポートしています。
compile でCNNモデルをコンパイルします。
compileについての詳細は、KerasのSequentialモデルのドキュメントも合わせて参照してください。
loss は正解ラベルデータとの誤差の処理方法ですが、1章で紹介したSONY Neural Network Console で作ったCNNモデルに習って categorical_crossentropy としています。
softmax 出力と categorical_crossentropy は一体と思っておけば良いです。
optimizer では、最適化、つまり誤差が最小になるように計算する手法を選ぶわけですが、SONY Neural Network ConsoleではデフォルトがAdamだったので、それに習いました。
Adamの最適化方法は私には難しくてよくわかりません。
metrics は’accuracy’としておけば良いと思います。
fit関数で学習を実行させます。
batch_size のデフォルトは32ですが、SONY Neural Network Consoleのデフォルト値に習って64としました。
epochs は、以前のディープラーニングの勉強その6記事で、エポック数を2000としたので、それに習っています。
試しに1回だけ学習させたい場合は、epochs=1 とすれば良いです。
verbose は1としておけば、学習経過が表示されるので良いと思います。
validation_data にはMNIST評価用データを入力しています。
summary関数で、CNNモデルの出力shapeやコスト(重みとバイアスのデータ数)、学習後の正答率等の一覧を表示させます。
evaluate関数で、評価用MNISTデータを入力して再評価させて正答率を表示させていますが、summary関数で評価用正答率が表示出来ているので、これは無くても良いかもです。
学習状況のヒストリーやロス関数のヒストリーをグラフ表示させているところは、説明を割愛します。
最後の行のsave関数で、学習済みのCNNモデルをHDF5形式(拡張子.h5)でGoogleドライブに保存します。
7章で詳しく述べていますが、予めGoogleドライブをマウントしておく必要があります。
Googleドライブなどの外部ストレージに保存せずに、ルートに保存してしまうと、いずれ消えてしまうので要注意です。
学習すると、実行結果は以下のように表示されます。
ハードウェアアクセラレータをGPUにすると、昼間の学習時間は2時間30分ほど、深夜0時以降の学習時間は1時間40分ほどでした。
(図02-05-01)
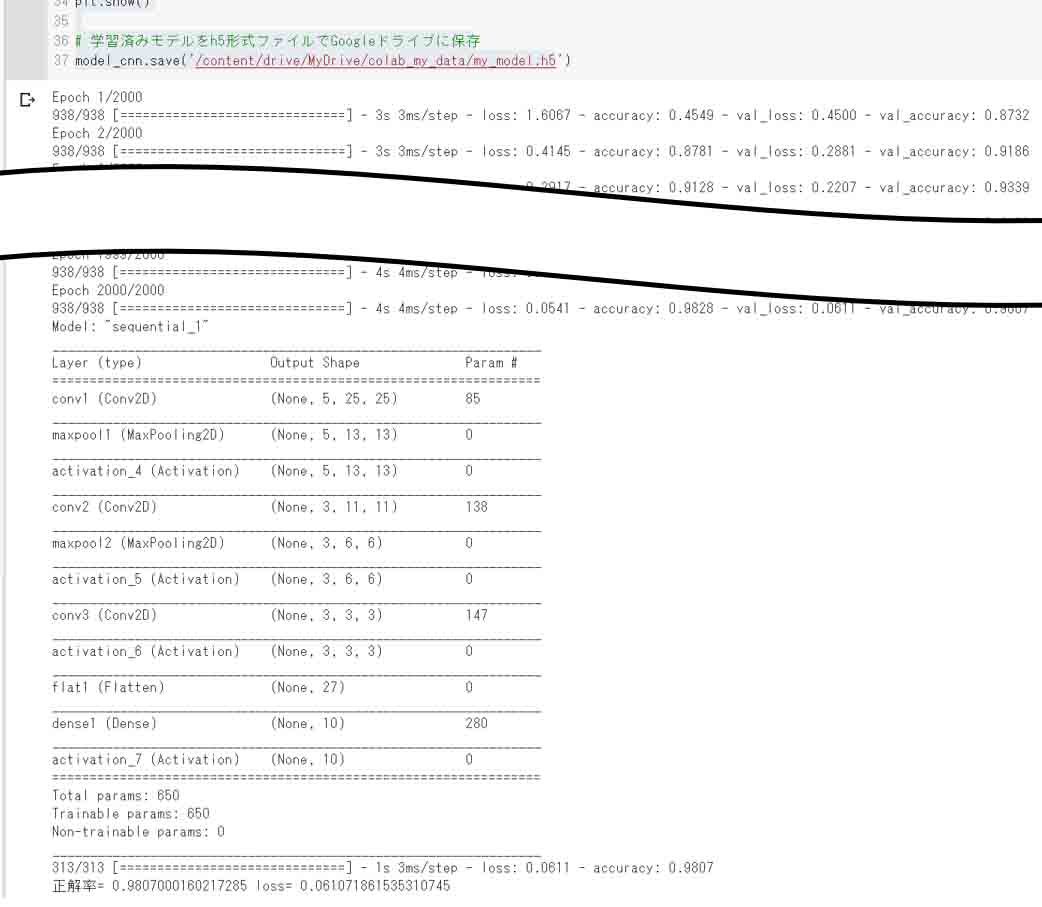
(図02-05-02)
私はもうかれこれ数十回学習させたと思いますが、これはその中でも一番良い正答率98%を叩き出した時のものです。
平均はだいたい97.5%でした。
学習させるたびに毎回正答率が異なります。
この正答率は以前のディープラーニングのお勉強その6記事で紹介したSONY Neural Network Consoleで学習させたときとほぼ同じなので、これでヨシとします。
これでバッチリ再現できたものと判断したいと思います。
CNNの各レイヤーの出力段チャンネル数が5以下なのに、この正答率は我ながら良くできたと思っています。
各レイヤーのパラメータ設定方法等についての詳しい説明は、5章以降で説明してみます。
3.レイヤー単独で出力結果を確認する方法
KerasでCNN(畳み込みニューラルネットワーク)モデルを構築してはみましたが、各レイヤーの出力が自分の意図通りになっているか確認したいですよね。
以前、SONY Neural Network Consoleで中間層の出力を試したことがあったのですが、日本語ドキュメントを見ながらでも、ちょっと面倒でした。
それで、TensorFlowやKerasでもその方法を探って、いろいろ試行錯誤しましたが、サッパリ分かりませんでした。
Kerasでは無理なのかなと諦めていたら、Kerasのこちらのドキュメントに方法が書いてありました。
英語ですが、とても簡単な方法で、レイヤー単体で出力結果を見ることが出来る良い方法があったんです。
ただ、そこにはテンソル(Tensor)配列を使ってインプットとしていました。
テンソルって何?
という感じでしたが、NumPy配列に変換しても問題ありませんでした。
テンソルより、NumPy配列の方が表示も簡単だし、理解し易いです。
(テンソルとNumPyの違いについて、この後の4章で述べます)
以下のような簡単なコードを組むだけです。
自分の好きな任意の入力値を代入して、レイヤーの引数パラメータ設定をして、出力結果を配列で確認することが出来るんです。
# Kerasのインポート
import numpy as np
from keras.layers import MaxPooling2D
# 入力としての2次元配列作成
input_ary = [[-1., 2., -3.],
[-4., -5., -6.],
[-7., 8., -9.]]
# NumPy配列に変換
input_nary = np.array(input_ary)
# 3×3の2次元配列をKerasモデル用の4次元配列に変換
input_nary = input_nary.reshape(1, 3, 3, 1)
# 単体レイヤーの設定
maxpool_2d = MaxPooling2D(pool_size=(2, 2),
strides=(2, 2),
padding='same')
# 単体レイヤーに入力し、出力結果を得る
output_ary = maxpool_2d(input_nary)
# 出力結果をテンソル(Tensor)で表示
print('shape=', output_ary.shape)
print(output_ary)
# テンソルをNumPy配列に変換
output_ary = output_ary.numpy()
output_ary = output_ary.reshape(2, 2)
print('\n4次元配列→2次元配列に変換')
print(output_ary)
【実行結果】
shape= (1, 2, 2, 1) tf.Tensor( [[[[ 2.] [-3.]] [[ 8.] [-9.]]]], shape=(1, 2, 2, 1), dtype=float32) 4次元配列→2次元配列に変換 [[ 2. -3.] [ 8. -9.]]
ここでは、MaxPooling2Dレイヤーの出力結果を見ましたが、Conv2Dをインポートすれば、Conv2Dレイヤーの出力も見ることができます。
これができれば、Excelに落とし込んだり、組み込みマイコンプログラムに落とし込んで検証したりできますね。
特に、後の6章で紹介していますが、パディング(padding)を確認したい時にはとっても重宝しました。
4.テンソル(Tensor)とNumPy配列の違い
前章では、今まで聞きなれないテンソル(Tensor)という配列がいきなり出てきました。
テンソルって何?
これについては、TensorFlowの「テンソルと演算」ドキュメントに書いてありました。
NumPy 配列と テンソル(Tensor)配列の違いは
●テンソルは( GPU や TPU などの)アクセラレータメモリを使用できる
●テンソルの要素は変更不可
ということです。
なるほど!
GPU演算に相応しいデータ型を決めて、変更できないようにしておかないと、GPU演算を上手く生かせないっていうことなんでしょうね。
テンソルを変えたい場合は、NumPy関数等で通常演算するだけでNumPy配列に自動的に変換され、NumPy配列からテンソル系の演算を行ってもテンソルに自動的に変換されると書いてあります。
便利ですね。
さすが、よく考えられています。
つまり、個人的な解釈で言うと、KerasはTensorFlowを使いやすくしたライブラリなので、CNN(畳み込みニューラルネットワーク)をKerasで構築して、KerasレイヤーにNumPy配列を入力すれば、出力は自動的にテンソル配列に変換されていて、効率良くGPU演算できる状態でメモリにデータが配置されているということなんだと思います。
なるほどなぁ~。
5.レイヤー引数パラメータについて(個人的見解を含む)
3章で紹介した、各レイヤー単独で出力結果を確認していると、引数パラメータ設定の意味が段々と分かって来ました。
意外と大きな勘違いしていることが多々ありました。
Conv2D レイヤー
filters
先頭の引数です。
2章では変数をoutput_channelsとして代入しています。
これは、出力ニューロン(ノード)数です。Kerasでは、出力チャンネル数と言います。
フィルターと言うと更に混乱しそうですが、要するに重みフィルターの数と出力チャンネル数は同じです。
つまり、(4, 4)の重みフィルターを5つにすると、出力チャンネル(ノード)数も5となります。
kernel_size
重みフィルターの配列サイズです。
kernel_size=(4, 4)
とすれば、4×4 です。
strides
文字通り、ストライドです。
strides=(1, 1)
とすると、横に1マス、縦に1マスのストライドします。
padding
これが要注意で、実は一番勘違いしたところです。
ここで述べると長くなるので、後の6章で詳しく述べています。
data_format
これはビギナーの方々は要注意です。
私は、長い間悩んでハマりました。
デフォルト設定では、
data_format='channels_last'
となっています。
KerasのConvolutionのドキュメントを参照すると分かると思いますが、channels_lastの場合のshape(配列)の要素順は、
(batch, height, width, channels)
と書いてあります。
batchはバッチサイズで、画像データ60000件のうち、64件毎に学習させる場合、バッチサイズは64となると思います。
heightは日本語で「高さ」ですから「列」と解釈できて、widthは幅ですから「行」と理解できます。
channelsはニューロン(ノード)数です。
ただ、ここで問題なのが、そのKerasドキュメントの下側に「入力のshape」という欄があって、そこにはdata_format='channels_last'の場合, (batch_size, rows, cols, channels)
と書いてあるところです。
rowは日本語で「行」で、colはcolumnの略ですから「列」ですよね。
ここで私は迷い、ハマりました。
ドキュメントが間違えているのかと思い、いろいろ調べたんですが、そこを指摘しているところはどこにもありませんでした。
そこで、何気にTwitterで不満をぶつけたら、けりさんから教えて頂きました。
なんと、
height = the number of rows(行の数)
width = the number of cols(列の数)
ということで、同じ意味だそうです。
確かに、rowsとcolsは複数形になっているので、そういう意味だということです。
お恥ずかしながら、ただ単に自分の英語力不足だったということで、無駄な時間を費やしてしまいました。
今まで殆どGoogle 翻訳に頼っていたので、こういう単純な文法はスルーしてしまい、中学校の英語力すら消え去っていました。
改めて、プログラミングは英語力が大事なんだなと思いましたね。
けりさん、教えて頂きありがとうございました。
m(_ _)m
さて、ここでもう一つ疑問なのが、何でchannels_lastがデフォルトなのかということです。
つまり、出力配列が25×25だとして、それが5チャンネル(ノード)だった場合、
(25, 25, 5)
となり、チャンネル(ノード)が最後に来るということです。
C言語から勉強してきた私にとっては、5×25×25という順序が多次元配列の感覚なので、頭が混乱してきます。
channels_lastの方が、計算は速いんでしょうかね?
結局、理由は分らなかったのですが、channels_lastは頭が混乱するので、私は、
data_format='channels_first'
にしました。
すると、
(batch, channels, height, width)
となり、私の感覚としてはしっくり来ます。
ただ、ネット上に溢れているKerasのサンプルコードは、ほとんどがデフォルトのchannels_lastなので、ネット上のサンプルを多用する場合は、気を付けなければなりませんね。
逆に混乱することになるかも、、。
input_shape
これも要注意です。
Convolutionレイヤーを、モデル全体の最初の層に使うときはinput_shapeを指定します。
かなり忘れがちです。
例えば,data_format='channels_last'で,白黒の28×28画像の場合、
input_shape=(28, 28, 1)
となります。
data_format='channels_first'の場合、
input_shape=(1, 28, 28)
となります。
28×28 カラーRGB画像では、
input_shape=(28, 28, 3)
となります。
dilation_rate
カーネルの膨張用パラメータです。
1より大きくすると確実に正答率が下がるので、私個人としてはしばらくは使わないと思います。
dilation_rate=(1, 1)
がデフォルトです。
activation
活性化関数の設定です。
当ブログのディープラーニングシリーズ第7弾までは、Tanhを使っていました。
ただ、1章のSONY Neural Network Consoleで組んだCNNでは、Tanhを1つのレイヤーとしているので、ここではConv2Dの引数をNoneにして、後で述べるActivationレイヤーでtanhを使うようにしました。
use_bias
文字通り、バイアス値を使うかということです。
ここでは、
use_bias=True
とします。
kernel_initializer
重みの初期値を指定できます。
初期値を適切に決めることによって学習速度が早くなったりします。
初期値をゼロにしたい場合、
kernel_initializer='zeros'
とします。
または、
kernel_initializer=initializers.Zeros()
でもいけますが、
from keras import initializers
のようにinitializersをインポートしておく必要があります。
initializersについては、Kerasの初期化ドキュメントを参照してください。
以前のExcelでディープラーニングの勉強その3記事でやった時には、重みの初期値を乱数にしていました。
SONY Neural Network Consoleの場合は、
kernel_initializer='glorot_normal'
という設定がデフォルトだったので、今回はそれに習いました。
bias_initializer
実はこれもややこしく、混乱して沼にハマりましたので要注意です。
私は、SONY Neural Network Consoleのデフォルト値に習って、Constantの1.0で初期化したかったんです。
それで、Kerasの重み初期化のドキュメントを見てみると、Constant設定について具体的に記述されているところがどこにもありません。
ゼロで初期化する場合の
bias_initializer='zeros'
という記述はありましたが、他の方法が分かりません。
そこで、
bias_initializer='Constant(value=1.0)'
としてみました。
しかしエラーが出ました。
また、
bias_initializer=Constant(value=1.0)
としてもエラーが出ました。
なら、
bias_initializer=initializers.Constant(value=1.0)
としたら、今度はinitializersが無いというエラーが出ましたが、
from keras import initializers
として、initializersをインポートして、
bias_initializer=initializers.Constant(value=1.0)
とすれば、ようやく正常終了しました。
しかし、initializersをわざわざインポートしなくても、
bias_initializer='ones'
でOKだったことがつい最近判明しました。
この方法は公式ドキュメントのどこにも書いてありません。
私が想像でこうやればできるかもと思ってやってみたらうまくいきました。
要するに、initializers関数群の頭の大文字を小文字にした文字列を使えば良いようです。
kernel_regularizer, bias_regularizer, activity_regularize
これらは使ったことが無いので、Noneにしました。
要は、最適化学習最中に、レイヤー内のパラメータあるいは出力に制約を設ける設定だそうです。
詳しくは、Kerasの正規化ドキュメントを参照してください。
kernel_constraint, bias_constraint
これも使ったことが無いので、Noneにしました。
要は、最適化中のネットワークパラメータに制約(例えば非負の制約)をする設定だそうです。
詳しくは、Kerasの正規化ドキュメントを参照してください。
name
後でモデルを再構築して途中経過出力したい場合に、レイヤーに名前をつけておくと、後々便利です。
name='conv1'
と言う感じで、好きな名前にすれば良いです。
MaxPooling2D レイヤー
pool_size
MaxPoolingのpool_sizeは(2, 2)、つまり2×2マスにすることが多いです。
このサイズが大きくなればなるほど正答率が下がるので、できるだけ低い値にすることです。
strides
ストライドは、pool_sizeが(2, 2)の場合は、ストライドも(2, 2)にすることが多いです。
Convolutionのように(1, 1)にしてもあまり正答率は上がりません。
padding
これはConv2Dと同様、めちゃめちゃ勘違いし易いので要注意です。
6章を参照してください。
data_format
これは、先ほどのConv2Dのdata_formatと同じで要注意な引数です。
name
これも、Conv2Dのところで説明したように、名前を付けておくと後々便利です。
Activation レイヤー
Conv2Dの所でも述べたように、1章のSONY Neural Network ConsoleのCNNに習って、活性化関数をActivationレイヤーとして使いました。
ここでは、tanhと最終段のsoftmaxで使っています。
Flatten レイヤー
これはちょっと分かり難いかも知れませんが、以前のExcelでディープラーニングの勉強その3記事でやったように、ニューラルネットワークをExcelで組んでみれば理解し易いです。
最終のMaxPooling出力から全結合Dense(Affine)に渡す時には、MaxPooling出力のチャンネル(ノード)分けは不要で、全て1つの次元配列にまとめてしまった方が、全結合への計算は簡単になります。
3章で紹介した、レイヤー単独の出力方法を使って確かめてみます。
入力を、3チャンネル2×2の配列とした場合のFlattenの出力はこんな感じです。
# Flatten data_format=Noneを試す
# NumPy配列をインプットとする
# Kerasのインポート
import numpy as np
from keras.layers import Flatten
# 入力としての(3, 2, 2)配列作成
input_ary = [[[1, 2],
[3, 4]],
[[5, 6],
[7, 8]],
[[9, 10],
[11, 12]]]
# NumPy配列に変換
input_nary = np.array(input_ary)
print('input_ary shape=', input_nary.shape)
# 3×3の2次元配列をKerasモデル用の4次元配列に変換
input_nary = input_nary.reshape(1, 2, 2, 3)
# 単体レイヤーの設定
flatten_out = Flatten(data_format=None)
# 単体レイヤーに入力し、出力結果を得る
output_ary = flatten_out(input_nary)
# 出力結果をテンソル(Tensor)で表示
print('output_ary shape=', output_ary.shape)
print('[Tensor]')
print(output_ary)
# テンソルをNumPy配列に変換
output_ary = output_ary.numpy()
print('[NumPy]')
print(output_ary)
【実行結果】
input_ary shape= (3, 2, 2) output_ary shape= (1, 12) [Tensor] tf.Tensor([[ 1 2 3 4 5 6 7 8 9 10 11 12]], shape=(1, 12), dtype=int64) [NumPy] [[ 1 2 3 4 5 6 7 8 9 10 11 12]]
このように、入力shape (3, 2, 2)の部分だけに注目すると、要素数(12)の1次元に変換されました。
ここではdata_format=Noneで実行しましたが、data_format='channels_first'でも'channels_last'でも同じ結果が得られました。
(1, 12)という訳は、データが1組ということです。
これがMNISTの場合は60000件になるので、(60000, 12)となると思います。
このように、Flattenで配列を平坦化することによって、次の全結合Dense(Affine)の計算が簡単になります。
Flattenを使わずにいきなりDenseに入力してもエラーになるので、FlattenとDenseは一体と憶えておけば良いかも知れませんね。
Dense レイヤー
Denseは全結合レイヤーです。
SONY Neural Network ConsoleではAffineと言います。
units
全結合の出力ノード数です。ここでは、output_channelsという変数を作って、代入しています
activation
出力の活性化関数を決めます。
2章のCNNでは不要なのでNoneにしました。
use_bias
バイアスは必要なので、Trueにしました。
kernel_initializer
ここはConv2Dと同じく、SONY Neural Network Consoleのデフォルト値に合わせて、glorot_normalにしました。
bias_initializer
これも、Conv2Dのところで述べたのと同じで、SONY Neural Network Consoleのデフォルト値に合わせて、
bias_initializer='ones'
として、初期値を1.0としました。
kernel_regularizer, bias_regularizer, activity_regularize
Conv2Dのところで述べたのと同様で、使ったことが無いので、Noneにしました。
kernel_constraint, bias_constraint
Conv2Dのところで述べたのと同様で、使ったことが無いので、Noneにしました。
name
これも、Conv2Dと同様に名前を付けておくと後々便利です。
6.パディング(padding)の謎
ニューラルネットワークの各レイヤー(層)の設定で、個人的に最も悩まされたのがパディング(padding)です。
paddingは、特にストライドが2以上のMaxPooling層で問題になります。
Convolution層でもストライドが2以上ならば問題になって来ます。
paddingというのは、以前のこちらの記事でも少し紹介しましたが、MaxPooling層で入力の配列要素数が奇数の場合、Poolサイズが(2, 2)で、ストライドが(2, 2)とすると、境界線付近で割り切れなくなるため、上下または左右にゼロまたはその他の数値で穴埋めして割り切れるようにする手法です。
これは、文章にしても何が何だかサッパリ分からないと思いますので、後ほど図で説明します。
私は、Kerasを使わずに自分でニューラルネットワークをプログラミングしたいが為に、一旦、Excelに落とし込むことをします。
その為には、各パラメータの意味をしっかり理解していないと、Kerasで組んだニューラルネットワークをExcelやその他プログラミングで再現できません。
とくに悩ましいのが、
padding='valid'
や、
padding='same'
です。
ネット上の情報を見ると、padding='same'の場合はほとんどが上下左右にゼロパディングされるとありました。
しかし、どうも出力結果のshape(配列要素数)が異なった結果になり、かなり悩まされました。
ということで、3章で紹介した手法を用いて、検証してみました。
6-01. padding=’valid’ はパディング無効だった
validはvalidationの略です。
日本語訳すると「有効」という意味になりますが、実は何とpadding無効なんです!
なんだとぉ~!!!
これ、間違えやすいですよね。
何でvalidなのかは、いろいろ調べてみましたが、結局わかりませんでした。
では、まず、下図の様なshape=(3, 5)の配列をインプットするとします。
ゼロパディングかどうかを判断するために、敢えて負の値を入れています。
(図06_01_01)
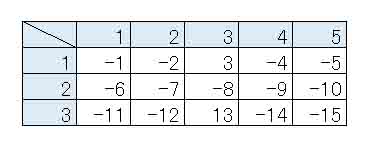
これを、3章で紹介したレイヤー単独の出力結果確認方法を使って、MaxPooling2Dレイヤーのプロパティ―設定で、
padding='valid'
にして実行してみます。
# inputが奇数配列の場合、padding='valid' を検証
# NumPy配列をインプットとする
# Kerasのインポート
import numpy as np
from keras.layers import MaxPooling2D
# 入力としての2次元配列作成
input_ary = [[-1, -2, 3, -4, -5],
[-6, -7, -8, -9, -10],
[-11, -12, 13, -14, -15]]
# NumPy配列に変換
input_nary = np.array(input_ary)
print('input_ary shape=', input_nary.shape)
# 3×3の2次元配列をKerasモデル用の4次元配列に変換
input_nary = input_nary.reshape(1, 3, 5, 1)
# 単体レイヤーの設定
maxpool_2d = MaxPooling2D(pool_size=(2, 2),
strides=(2, 2),
padding='valid')
# 単体レイヤーに入力し、出力結果を得る
output_ary = maxpool_2d(input_nary)
# 出力結果をテンソル(Tensor)で表示
print('output_ary shape=', output_ary.shape)
print(output_ary)
# テンソルをNumPy配列に変換
output_ary = output_ary.numpy()
output_ary = output_ary.reshape(1, 2)
print('\n4次元配列→2次元配列に変換')
print('output_ary shape=', output_ary.shape)
print(output_ary)
【実行結果】
input_ary shape= (3, 5) output_ary shape= (1, 1, 2, 1) tf.Tensor( [[[[-1] [ 3]]]], shape=(1, 1, 2, 1), dtype=int64) 4次元配列→2次元配列に変換 output_ary shape= (1, 2) [[-1 3]]
わかりましたでしょうか?
図で表すと以下の感じです。
(図06_01_02)
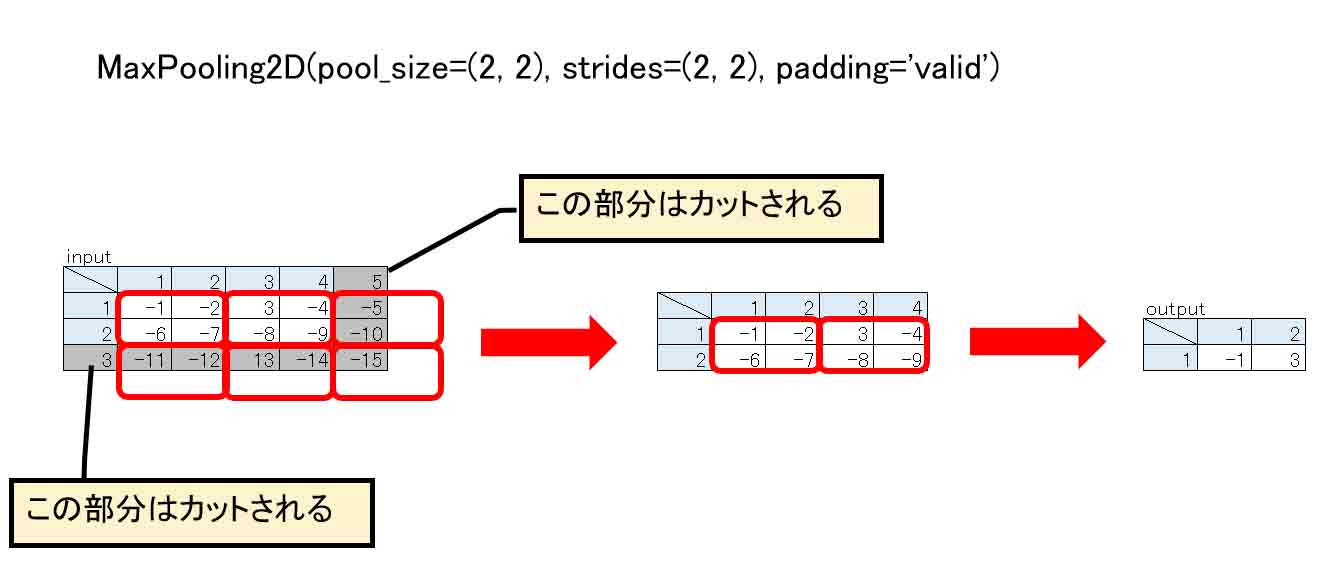
つまり、Poolサイズ(2, 2)で、奇数の要素数では境界線付近で割り切れなくなってはみ出るので、その部分の要素はカットされてしまうということです。
6-02. padding=’same’ はゼロパディングではない?
さて、これが問題です。
padding='same'については、KerasのConvolutionレイヤーのドキュメントを見ると、
“same”は元の入力と同じ長さを出力がもつように入力にパディングします。
とあります。
しかし、これがとっても分かりにくい表現なんです。
では、3章で紹介したレイヤー単独の出力結果確認方法を使って、実際に計算させてみます。
# inputの要素数が奇数で、padding='same'の場合を検証
# NumPy配列をインプットとする
# Kerasのインポート
import numpy as np
from keras.layers import MaxPooling2D
# 入力としての2次元配列作成
input_ary = [[-1, -2, 3, -4, -5],
[-6, -7, -8, -9, -10],
[-11, -12, 13, -14, -15]]
# NumPy配列に変換
input_nary = np.array(input_ary)
print('input_ary shape=', input_nary.shape)
# 3×3の2次元配列をKerasモデル用の4次元配列に変換
input_nary = input_nary.reshape(1, 3, 5, 1)
# 単体レイヤーの設定
maxpool_2d = MaxPooling2D(pool_size=(2, 2),
strides=(2, 2),
padding='same')
# 単体レイヤーに入力し、出力結果を得る
output_ary = maxpool_2d(input_nary)
# 出力結果をテンソル(Tensor)で表示
print('output_ary shape=', output_ary.shape)
print(output_ary)
# テンソルをNumPy配列に変換
output_ary = output_ary.numpy()
output_ary = output_ary.reshape(2, 3)
print('\n4次元配列→2次元配列に変換')
print(output_ary)
【実行結果】
input_ary shape= (3, 5) output_ary shape= (1, 2, 3, 1) tf.Tensor( [[[[ -1] [ 3] [ -5]] [[-11] [ 13] [-15]]]], shape=(1, 2, 3, 1), dtype=int64) 4次元配列→2次元配列に変換 [[ -1 3 -5] [-11 13 -15]]
さて、どうでしょうか?
ネット上の情報の殆どは上下左右にゼロパディングされていると書かれていますが、こうやって入力の各要素に負の値を入れてみてMaxPooling処理させると、予想とは全然違った値になったではありませんか!
つまり、ゼロパディングされていたとすると、-5のところはゼロでないとおかしいわけで、-11や-15の所もゼロにならなければおかしいわけです。
と、いうことは、ゼロパディングではないと言えるのではないでしょうか?
よって、私の個人的判断で、こう言い切ってしまいます。
(図06_02_01)
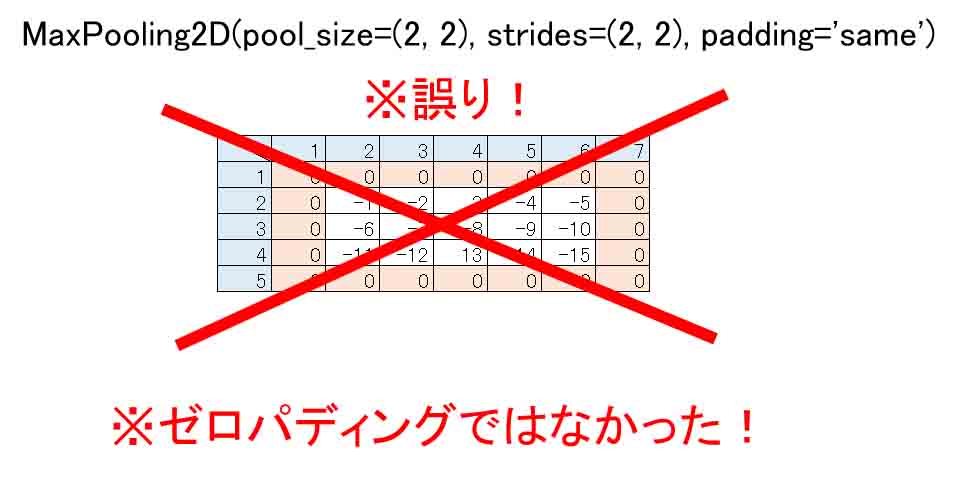
padding='same'はゼロパディングしない。
正しくは、こうだと思われます。
(図06_02_02)
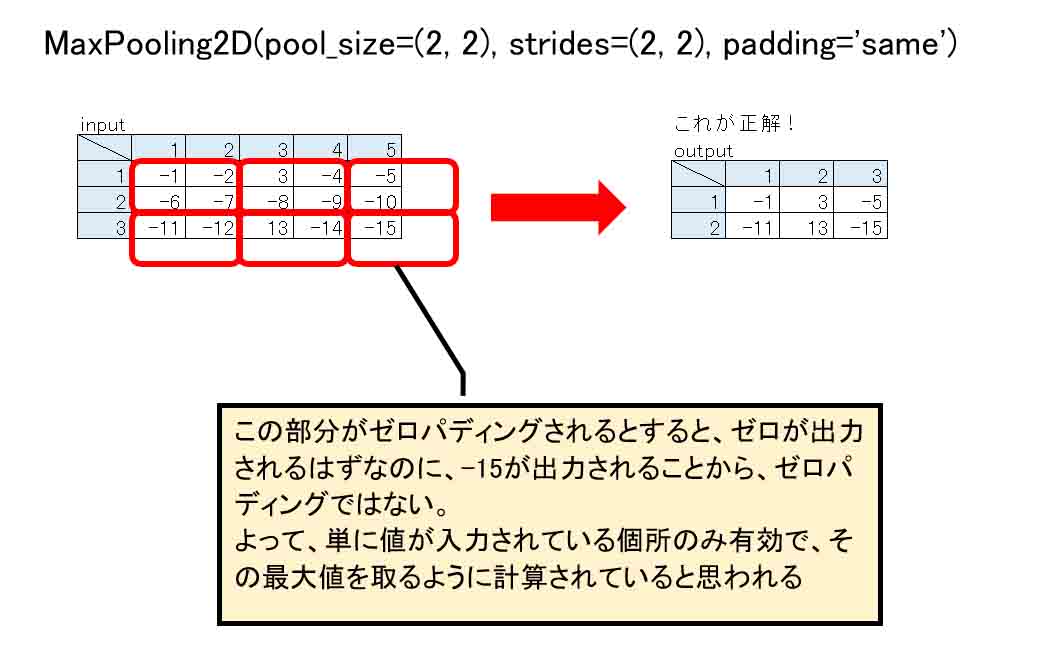
恐らく、TensorFlowやKerasのソースコードを解読できれば判明するかと思いますが、ザッと私が見たところ、難解過ぎて解読は無理でした。
でも、計算結果だけでも判断できるので、個人的にpadding='same'はゼロパディングではないと断言しちゃいます。
現に、Kerasのドキュメントにも、padding='same'はゼロパディングするとはどこにも書いてありません。
ただパディングするとしか書いてありませんでした。
間違えていたら教えてください。
もし、意図的に上下左右の任意の場所にゼロパディングしたいならば、
ZeroPadding2D
というレイヤー関数が用意されているので、それを利用すれば良いと思います。
ところで、Conv2Dレイヤーの場合はゼロパディングではないと言い切れないところがあります。
3章で紹介したレイヤー単独の出力結果確認方法を使って、カーネルサイズ(2, 2)、ストライド(2, 2)として計算させてみると、
# Conv2D
# inputの要素数が奇数で、padding='same'の場合を検証
# NumPy配列をインプットとする
# Kerasのインポート
import numpy as np
from keras.layers import Conv2D
# 入力としての2次元配列作成(convolutionの場合float型にする)
input_ary = [[-1., -2., 3., -4., -5.],
[-6., -7., -8., -9., -10.],
[-11., -12., 13., -14., -15.]]
# NumPy配列に変換
input_nary = np.array(input_ary)
print('input_ary shape=', input_nary.shape)
# 3×3の2次元配列をKerasモデル用の4次元配列に変換
input_nary = input_nary.reshape(1, 3, 5, 1)
# 単体レイヤーの設定
conv_2d = Conv2D(1,
kernel_size=(2, 2),
strides=(2, 2),
padding='same',
use_bias=False,
activation=None,
kernel_initializer='ones')
# 単体レイヤーに入力し、出力結果を得る
output_ary = conv_2d(input_nary)
# 出力結果をテンソル(Tensor)で表示
print('output_ary shape=', output_ary.shape)
print(output_ary)
# テンソルをNumPy配列に変換
output_ary = output_ary.numpy()
output_ary = output_ary.reshape(2, 3)
print('\n4次元配列→2次元配列に変換')
print(output_ary)
【実行結果】
input_ary shape= (3, 5) output_ary shape= (1, 2, 3, 1) tf.Tensor( [[[[-16.] [-18.] [-15.]] [[-23.] [ -1.] [-15.]]]], shape=(1, 2, 3, 1), dtype=float32) 4次元配列→2次元配列に変換 [[-16. -18. -15.] [-23. -1. -15.]]
こんな感じになりましたので、ゼロパディングされていたとしても同じ計算結果になります。
ですから、Convolutionの場合は正確なところは分かりません。
7.学習済みモデルをHDF5形式でGoogle Driveに保存する
2章で作成したモデルの最後の行では、学習済みのCNNモデルをGoogle Driveに保存する処理をしています。
Google Colaboratoryのクラウドの特徴ですが、せっかく2時間も学習させたのに、何も対策しないと次にGoogle Colaboratoryを使う時に学習データが消えてしまいます。
よって、重みデータを取り出したい場合はまた最初から学習し直さねばなりません。
ですが、Google Colaboratoryには、学習済みデータを外部ファイルとして、Googleドライブに保存することができます。
ここでは、HDF5形式ファイルで保存します。
拡張子は.h5です。
HDF5形式について、私はよく知りませんし、ビューワーソフトも手頃なものが見つかりませんでした。
ただ、KerasやSONY Neural Network Consoleで読み書きできるので、それを使えば問題ないと思います。
ただ、Google Colaboratoryで学習済みモデルを外部ファイルに保存するには、いろいろと注意点があります。
例えば、学習が済んだモデルの後で、以下のコードを実行し、Google Colabのルートに保存するとします。
model_cnn.save('my_model.h5')
次に、下図のように、Jupyter Notebookの左側のファイルアイコンをクリックします。
(図07_01)
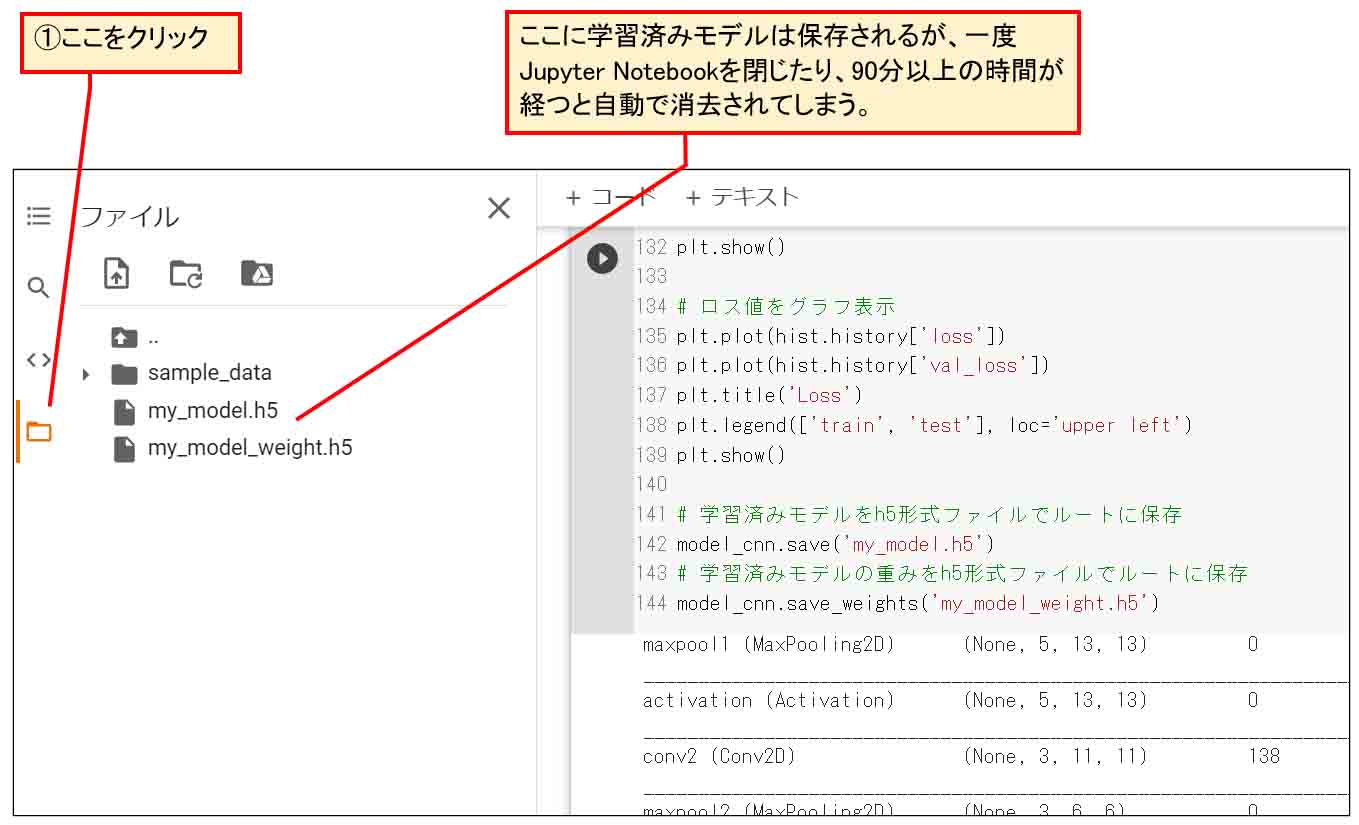
すると、ルートに my_model.h5 というファイルができています。
ただし、ここにできたファイルは、Google Colaboratoryを閉じて、次に起動する時には自動で消去されている場合があります。
おそらく、9時間ルールや12時間ルールなどでランタイムが切断され、一時ファイルは消去されてしまうのだと思います。
これを永久的に保存したいならば、Googleドライブをマウントして、Googleドライブに保存するのが良いと思います。
下図のようにGoogleドライブアイコンをクリックします。
(図07_02)
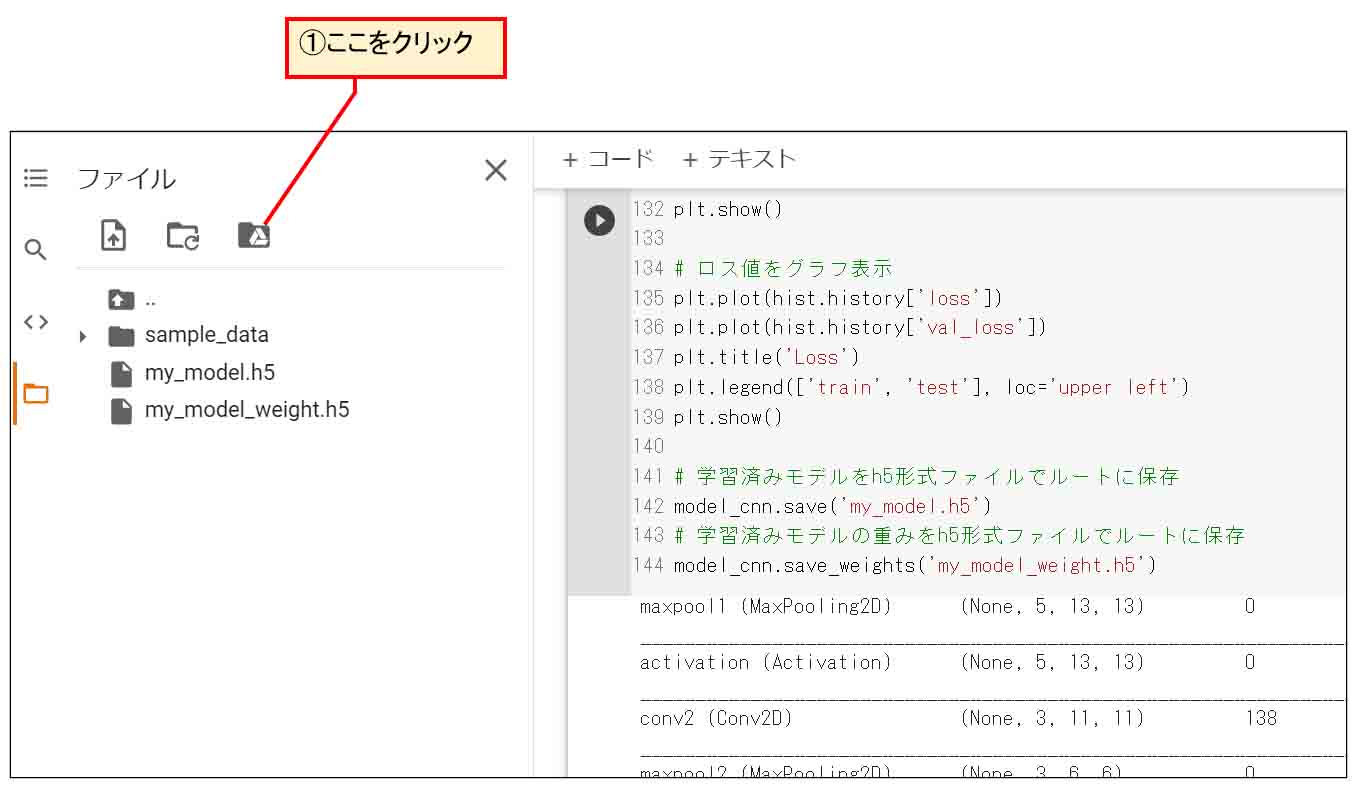
すると、以下のようなメッセージが出るので、「GOOGLEドライブに接続」をクリックします。
(図07_03)
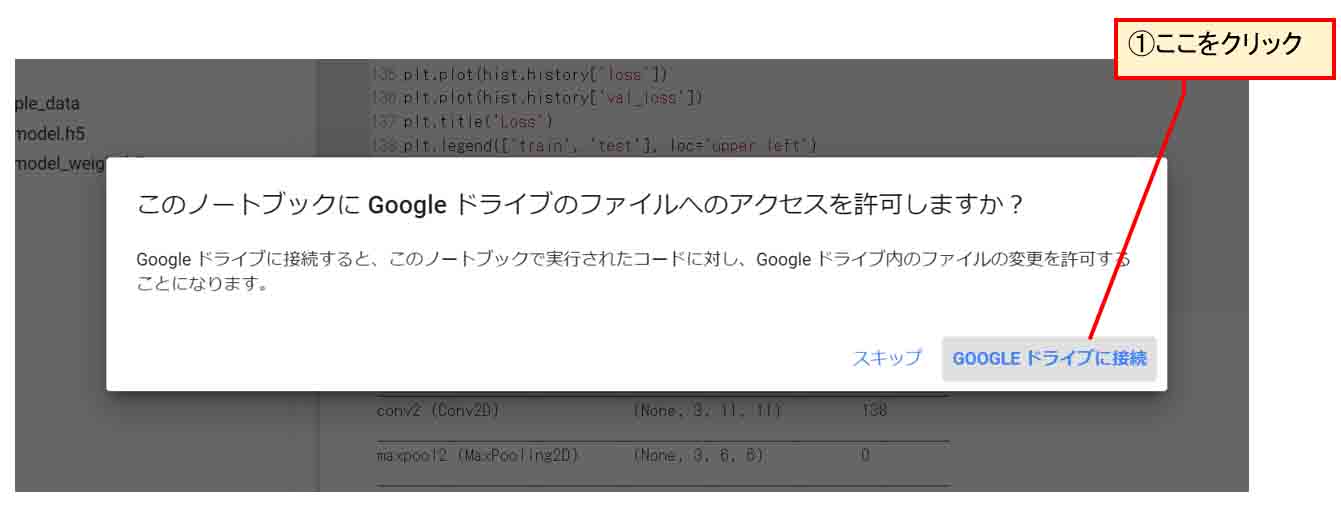
そして、ちょっと間を置くと、下図のようにGoogleドライブフォルダがマウントされます。
(図07_04)
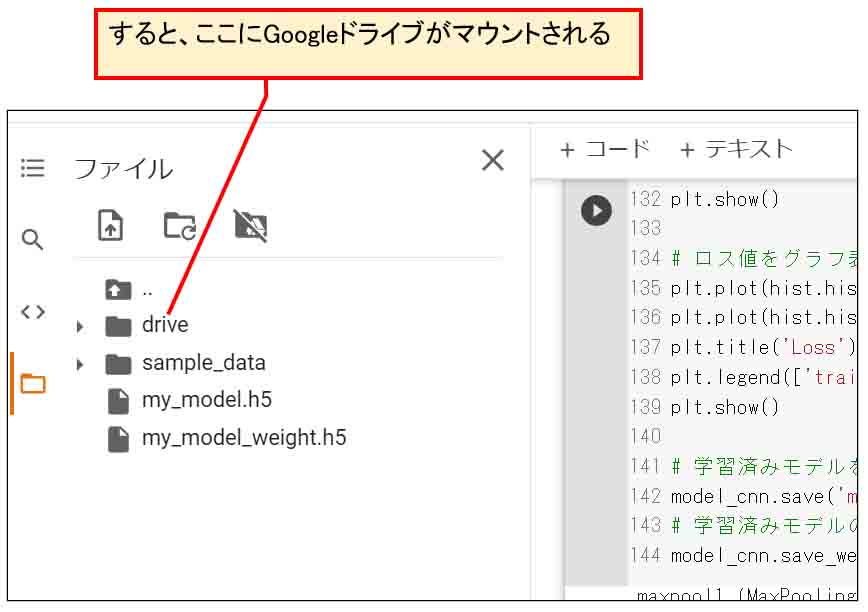
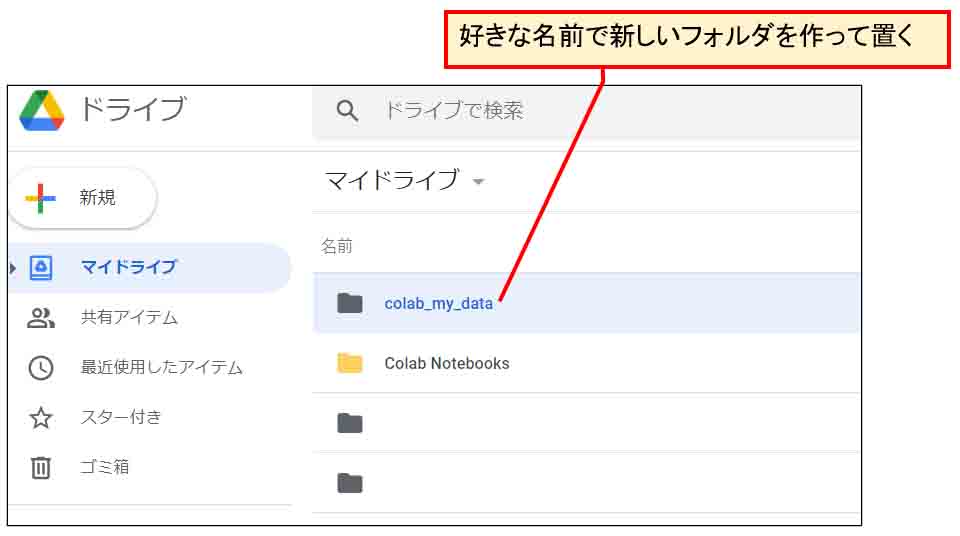
そうしたら、ブラウザの別のタブで自身のGoogleドライブを開き、好きな位置にデータ保存用のフォルダを作って置きます。
ここでは、colab_my_dataという名前にしておきます。
(図07_05)
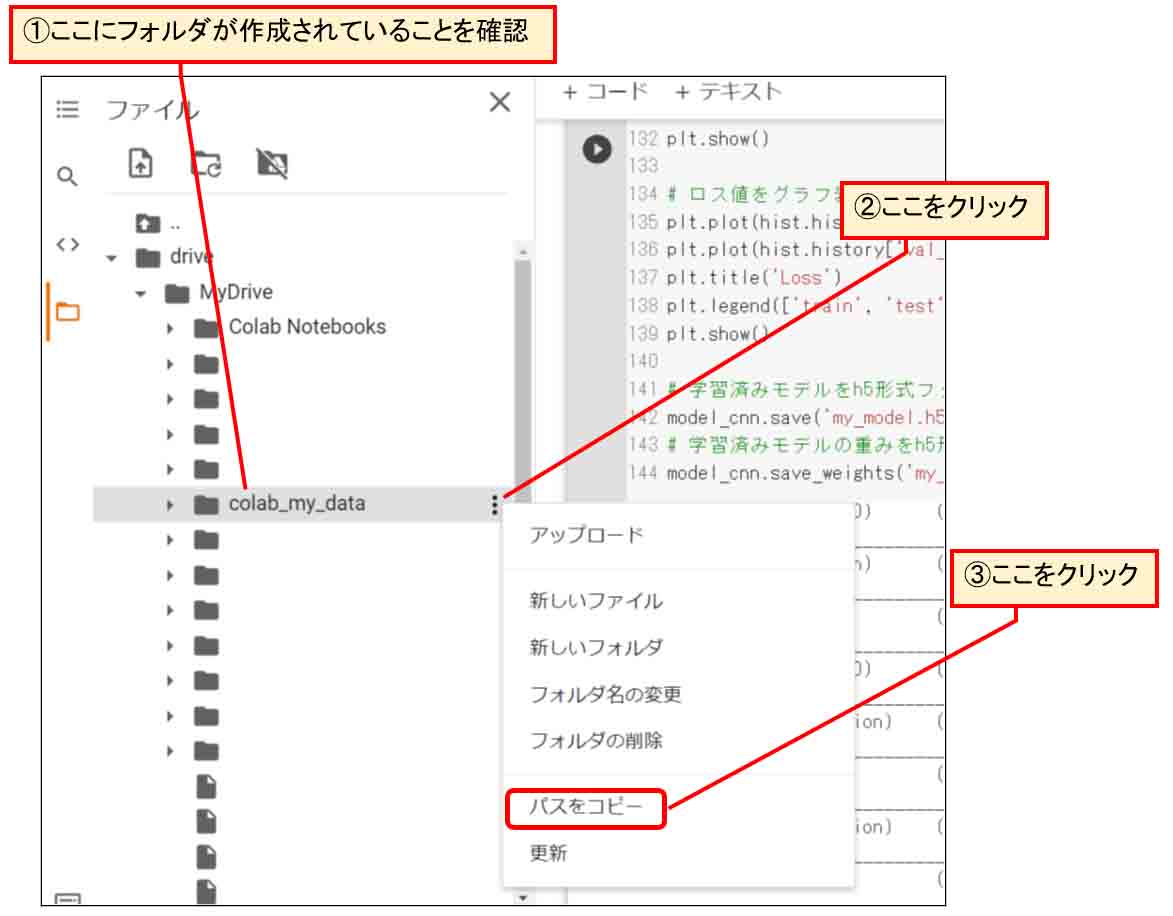
そして、今度はGoogle Colaboratoryに戻り、今作ったフォルダが作成されていることを確認します。
そして、下図の様なところをクリックし、フォルダのパスをコピーします。
(図07_06)
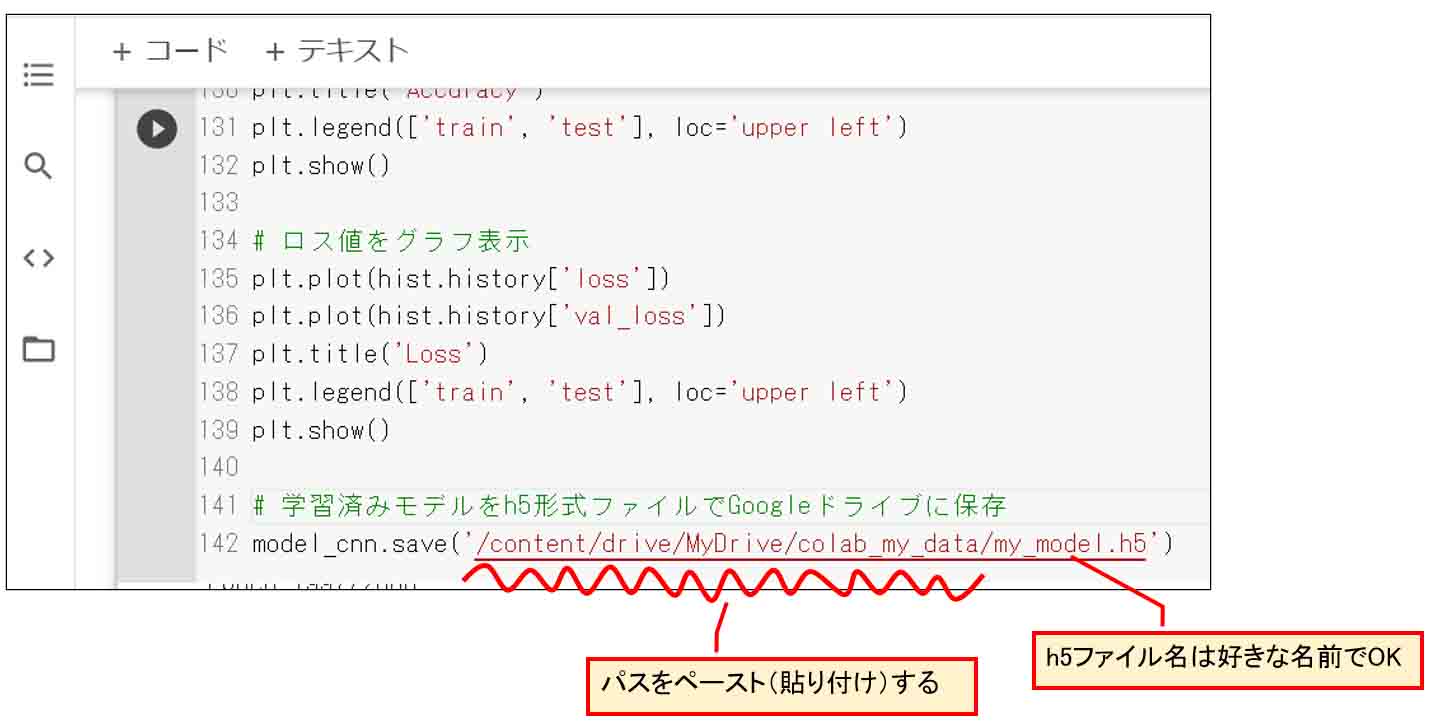
そうしたら、モデル学習が済んだ後の最後の行に以下のsave文一行で、学習済みモデルをGoogleドライブへHDF5形式ファイルで保存できます。
model_cnn.save('/content/drive/MyDrive/colab_my_data/my_model.h5')
ファイルパスのうち、先ほどコピーしたフォルダパスが以下です。
/content/drive/MyDrive/colab_my_data/
ファイル名は
my_model.h5
としました。
(図07_07)
因みに、ここでトラブルシューティングというか、要注意点をお知らせします。
何度も同じJupyter Notebookで、ファイルの読み書きをしていたり、しばらく作業を離れたりすると、なぜかGoogleドライブのマウントが切断されてしまう時がありました。
その場合、下図のように、Google Colaboratory上ではGoogleドライブにファイルが保存されているように見えるのですが、ブラウザの別タブで開いたGoogleドライブ上にはファイルが保存されていないということがありました。
そういう状態で、save関数を実行すると、以下のようなメッセージが出ました。
(図07_08)
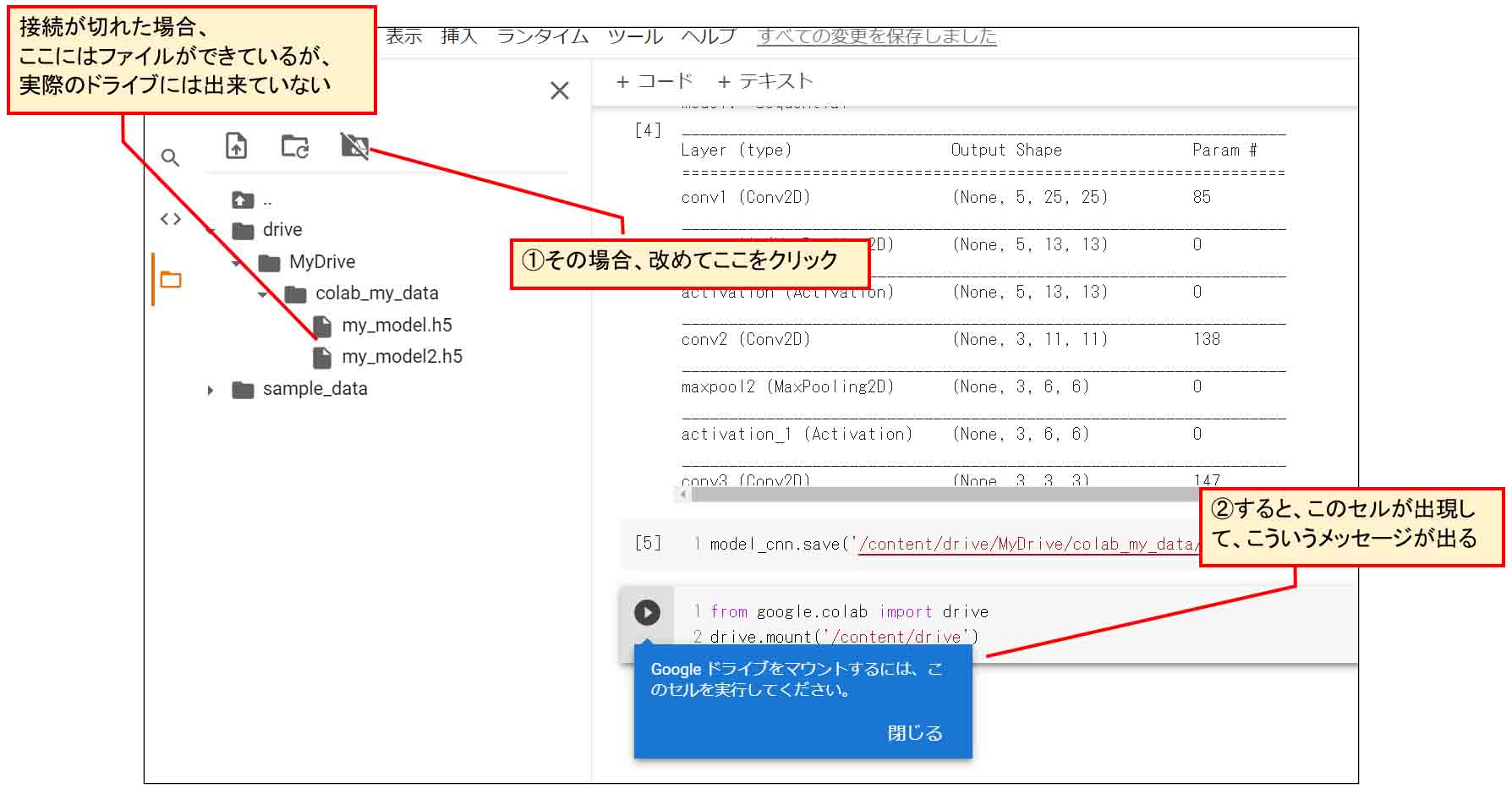
こうなると、このメッセージ通りにコードを入れ込んでもうまくいきませんでした。
ブラウザの更新ボタンを押してもダメでした。
この場合は、一旦、Google Colaboratoryを閉じて、Googleドライブのh5ファイルを消去して、保存用フォルダを空にしてから、Google Colaboratoryを再起動します。
その後、「ランタイムを最初から実行」にすると、ちゃんと保存できました。
この挙動はクラウド環境の嫌なところですね。
8.Googleドライブに保存したHDF5形式の学習済みモデルを読み込む
では、Googleドライブに保存したHDF5形式の学習済みモデルファイルを読み込んでみます。
まず、注意しなければならないのは、Google Colaboratoryファイルを新規作成して、Googleドライブに保存してあるHDF5形式ファイルを読み込む時、必ず事前にGoogleドライブをマウントしておくことを忘れないでください。
(7章参照)
忘れると、「ファイルが見つからない」というエラーが出てしまいます。
Googleドライブのマウントが済んであることを確認できたら、以下のコードを組むだけでOKです。
Googleドライブのファイルパスは先ほどと同じです。
# 学習済みモデルh5ファイルを読み込んで出力
# load_modelをインポートする
from tensorflow.python.keras.models import load_model
# modelへ保存データを読み込み
model = load_model('/content/drive/MyDrive/colab_my_data/my_model.h5')
model.summary()
【実行結果】
(図08_01)
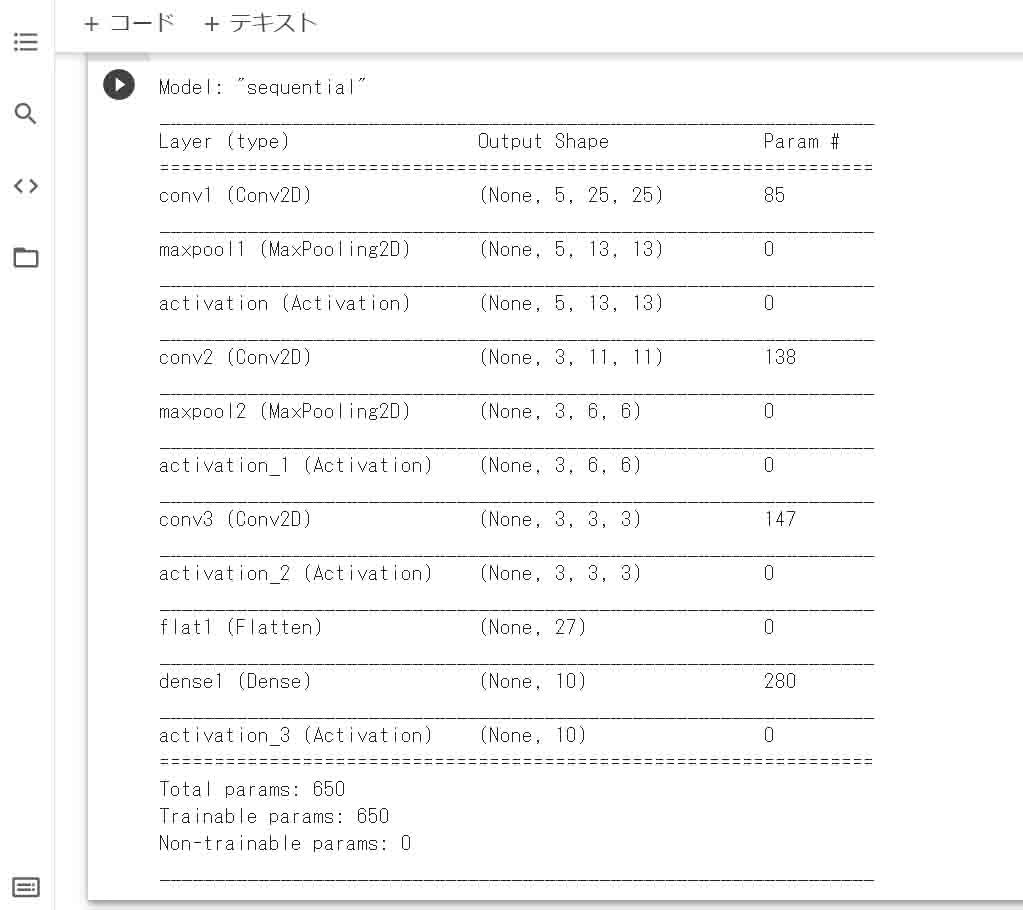
ちゃんと読み込まれていますね。
これでバッチリです。
安心してGoogle Colaboratoryを閉じられますね。
9.まとめ
Google Colaboratoryで独自のCNN(畳み込みニューラルネットワーク)を組んでみました。
各レイヤーの引数パラメータがこんなにも要注意点があるとは思ってもいませんでした。
実際に自分でCNNを組んでみると、改めてTensorFlowやKerasはビギナー向けでは無く、中堅者以上向けのディープラーニングツールだと思いました。
でも、このブログ記事を書いている上で、いろいろな発見があり、レイヤー単独で出力結果を見られるようにもなったので、得たものは大きいですね。
これからはいろいろ応用できそうな気がします。
では、今回はここまでです。
次回は、学習済みモデルから重みやバイアスデータを抽出する方法を説明できればと思っています。
ではまた・・・。
Amazon.co.jp 当ブログのおすすめ
コメント