
こんばんは。
今まで5回シリーズでゼロからディープラーニングを勉強してきて、ある程度理解が進んだので、今回はちょっと応用して、紙に書いた手書き数字をカメラ(イメージセンサ)で撮影して、夢の画像認識の第一歩に挑戦してみたいと思います。
使うのは、M5Stack社のM5Cameraです。
WiFiマイコンESP32-WROVERと、イメージセンサOV2640を駆動させて、Arduinoプログラミングで畳み込みニューラルネットワーク(CNN)を組んで、リアルタイム画像認識の実験です。
使う言語はPythonではなく、C/C++言語です。
まずは、以下の動画をご覧ください。
Arduino IDEのシリアルモニターに画素を1秒毎に表示させ、CNN処理で画像判定させています。
どうだ!
やっと画像認識らしきものの第一歩ができるようになりましたよ!
しかも、夢のリアルタイム画像認識です。
いやぁ~、ここまで来るのに長いなが~い道のりでした。
こちらの記事からディープラーニングを勉強し始めて、約5か月かかりました。
ニューラルネットワークのプログラミングには様々なライブラリがあるようですが、自分自身で畳み込みニューラルネットワークをプログラミングしたということに意味があります。
ニューラルネットワークの構造が手に取るようにわかるようになってきました。
これはMNISTデータセットで学習した重みとバイアスを使っていますが、本来のディープラーニングは実際のカメラ画像を学習データとして学習させるものと思います。
今回はまだ手始めなのでご容赦ください。
ただ、学習処理はさすがに自力では無理だったので、SONYのツール、Neural Network Consoleに頼りました。
学習計算を自身でプログラミングするのはとても時間がかかりますし、たとえ出来たとしても、おそらく処理速度が遅いものしか作れないでしょう。
今はGoogleやSONYなどの大手が超高速学習ツールを作っているので、それに頼った方が現実的です。
自分でプログラミングできるのは、ニューラルネットワークだけですが、それでも充分応用が利くと思いました。
動画を見て分かる通り、1秒毎に画像を取得しているので、位置決めがちょっと難しいですね。
コツをつかむと、ある位置に画像があれば認識率が上がるポイントが見えてきます。
それに、太いマジックで書いた文字は認識率高いですが、細い文字は認識率が悪いです。
また、左方向からライトを当てているので、M5Cameraの影を消しています。
認識し易い画像にするための前処理がかなり大事だということが分かって来ますね。
ところで、今回のプログラミングで、今まで敬遠してきたforループやwhileループの高速化に少しだけこだわってみました。
というのも、畳み込みニューラルネットワーク(CNN)をArduino のC/C++言語でプログラミングすると、forループやwhileループがメチャメチャ多くなりましたし、リアルタイム画像認識に挑戦しようとすると、できるだけ高速化した方が良いと思ったからです。
最初に組みあがった時には、畳み込みニューラルネットワークの演算が38msくらいかかりましたが、ループ処理をごにょごにょして、17ms程度に収めることができました。
これはCNN処理のみの計算時間です。
(後述しますが、カメラ画像取得からのトータル時間は約160msでした。)
ここまで時間を切り詰められれば、個人的には上出来です。
ループ処理の高速化については、今度記事にしようと思っています。
ただ、今回の実験で課題に上がってきたのは、スタックメモリサイズです。
ヒープメモリに関しては使い回したので問題無いと思うのですが、スタックサイズがギリギリなんです。
今回は28 x 28 pixel のMNIST画像に合わせて配列を確保しましたが、重みやバイアスパラメータもかなりの量なので、他のプログラミングを増やそうとするとすぐにスタックオーバーフローを起こします。
これは今後の課題ですが、もっと工夫してメモリを減らす必要がありますね。
ということで、この実験を説明していきたいと思います。
なお、何度も申し上げておりますが、私はプログラミングもディープラーニングも独学でド素人です。
誤りや勘違いが多々あると思いますので、お気づきの点があればコメント投稿でご連絡いただけると助かります。
- CNNをNeural Network Consoleで組み直し、重みとバイアスパラメータをエクスポートする
- テスト用の畳み込みニューラルネットワークをArduinoスケッチ(プログラム)で組む
- M5Cameraを使ったリアルタイム画像認識Arduinoスケッチ(プログラム)作成
- まとめ
【目次】
事前準備
使ったもの
ESP32開発ボード
Arduino IDE でプログラミング可能なWiFi & BluetoothマイコンESP32を搭載した、以下の開発ボードを使いました。
M5Camera
WiFi & Bluetooth マイコンのESP32-WROVERとイメージセンサOV2640を搭載したモジュールを使いました。
ただ、注意していただきたいのは、そのサイトにも書いてある通り、旧製品と現行製品ではピンアサインが異なっているので気を付けてください。
ちなみに、Amazonでは残念ながら販売されていませんでした。
パソコンおよびUSBケーブル
今回はディープラーニングの学習にWindows版SONY Neural Network Consoleを使用しているので、MACパソコンを使う場合は有料のクラウド版Neural Network Consoleを使わねばならないということに注意が必要です。
(2020/12月時点)
USBケーブルは良質で太く短い信頼性のあるものが良いと思います。
その分、取り回しにくいところがありますが、書込みは安定しています。
私は以下の物を使いました。
Arduino core for the ESP32 のインストール
事前にArduino IDEと、Arduino core for the ESP32 をインストールしておいてください。
Arduino core for the ESP32 のインストール方法
この記事で使ったバージョンは以下のとおりです。
●Arduino IDE ver 1.8.13
●Arduino core for the ESP32 stable ver 1.0.4
その他のバージョンでは動かない場合も有り得ますのでご了承ください。
SONY Neural Network Console を使えるようにしておく
SONY の Neural Network Console はディープラーニングを手軽に使えるツールです。
ただ、残念ながらオフラインで無料で使えるのはWindows版しかありません。
(クラウド版ならば有料ですがブラウザで使うことができます。)
過去の以下の記事で使い方等を説明していますので、参照してみてください。
ゼロからディープラーニングを勉強してみる ~その4。SONY Neural Network Console 導入編~
ゼロからディープラーニングを勉強してみる ~その5。SONY Neural Network Console いろいろ試す編~
1.CNNをNeural Network Consoleで組み直し、重みとバイアスパラメータをエクスポートする
では、まず、Arduinoプログラミングする前に、前回記事と前々回記事で扱ったように、SONYのNeural Network Consoleを使ってESP32用の畳み込みニューラルネットワーク(CNN)を組み直して、学習させ、学習済みの重みやバイアスデータをエクスポートします。
1-01. 低コスト高正答率の畳み込みニューラルネットワークをNeural Network Consoleで組み直す
SONY Neural Network Console の以下の記事
ゼロからディープラーニングを勉強してみる ~その4。SONY Neural Network Console 導入編~
を参照して、新たに手書き数字MNISTデータセットの畳み込みニューラルネットワーク(CNN)を組み直していきます。
今回のESP32用のニューラルネットワークでは、マイコンのメモリ消費をいかに少なくし、かつ高い正答率(98%以上)を出せるかが肝になると思います。
メモリを少なくするには、重みとバイアスのパラメータ総数を出来る限り抑えることです。
ということで、以下の畳み込みニューラルネットワーク(CNN)を組んでみました。
(図01-01-01)
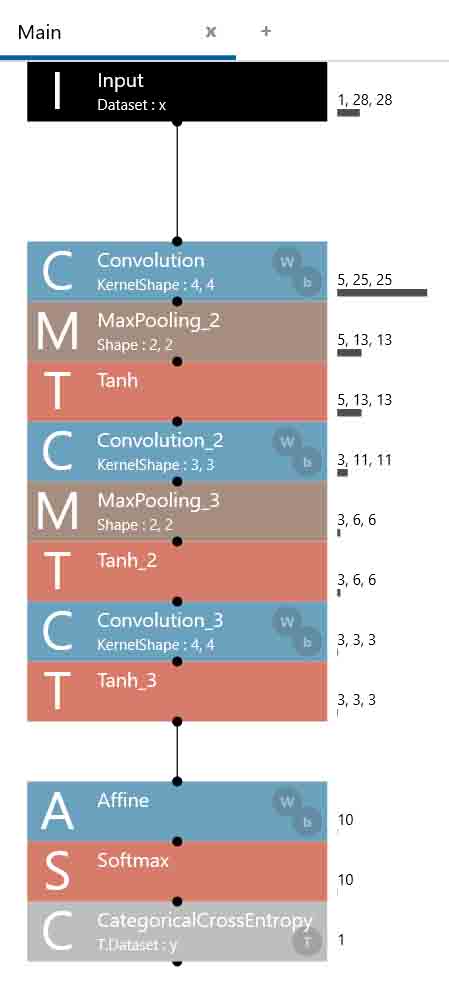
Inputは手書き数字MNISTデータセットの28×28 pixel にします。
最初のConvolution(畳み込み処理)では、カーネルが4×4で、ストライド1、出力が25×25の5ノード(ニューロン)にしました。
その後のMaxPoolingは、カーネル2×2で、ストライド2、出力は13×13にしました。
その後は例のごとくTanhで-1.0~+1.0の範囲に収めます。
ここまでは共に出力が奇数マスなので、前回のこちらの記事で述べたように、淵の処理(IgnoreBorder)に注意しておきます。
2回目のConvolution_2ではコストを減らすために、5ノードから3ノードにニューロンを減少させました。
カーネルは3×3、ストライド1で、出力は11×11です。
その後にカーネル2×2、ストライド2のMaxPoolingを行います。出力は6×6にしました。
その後はTanhで-1.0~+1.0の範囲に収めます。
3回目のConvolution_3で、カーネル4×4、出力3ノード、3×3にしました。
ここまで畳み込めれば、後のMaxPoolingは不要で、すぐTanh処理にします。
Affineは出力10ノードとして、SoftmaxとCategoricalCrossEntropy処理をしてCNN組み立ての完了です。
では、このニューラルネットワークのコスト(重みとバイアスパラメータの総数)を見てみると、以下のようになりました。
(図01-01-02)
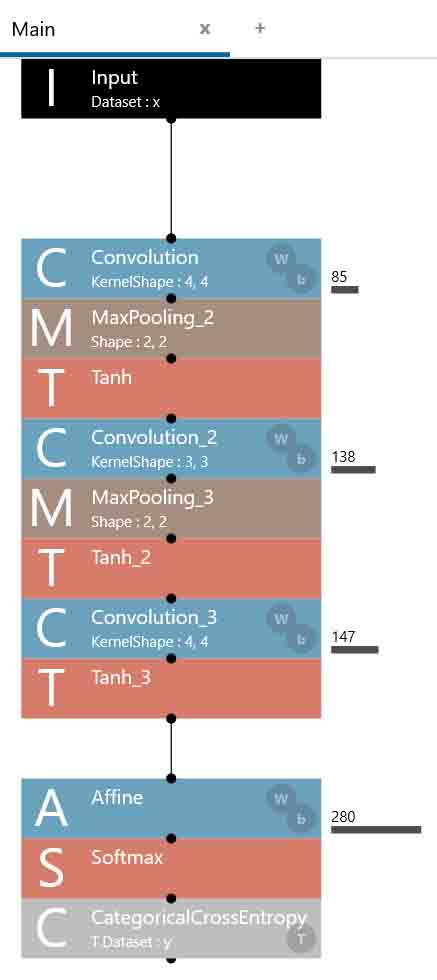
コストの総計は650個です。
これが多いか少ないかは後で述べます。
では、各モジュールのレイヤープロパティを見てみると以下の感じです。
まず、最初のConvolutionとMaxPoolingです。
(図01-01-03)
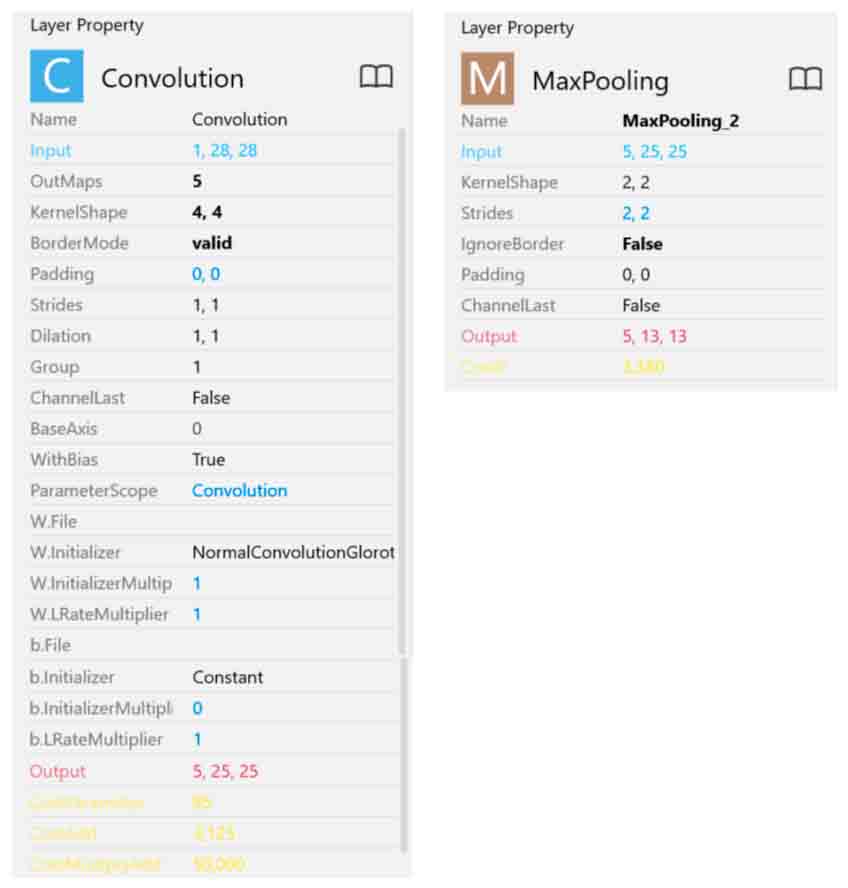
次に2回目のConvolutionとMaxPoolingです。
(図01-01-04)
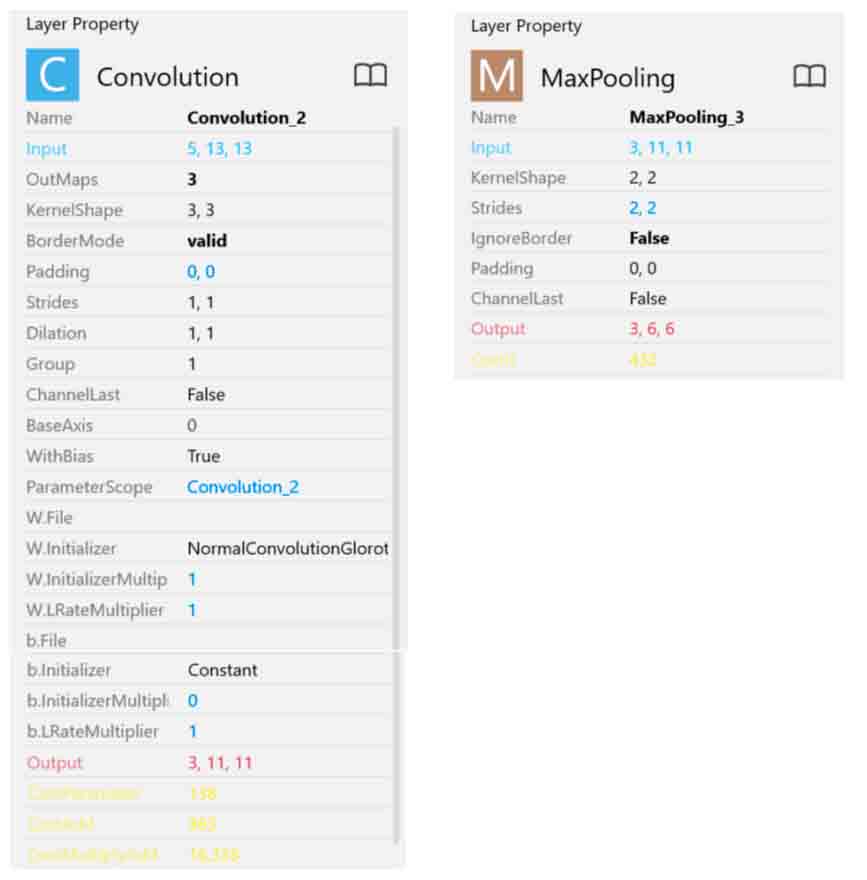
そして、3回目のConvolutionとAffineです。
(図01-01-05)
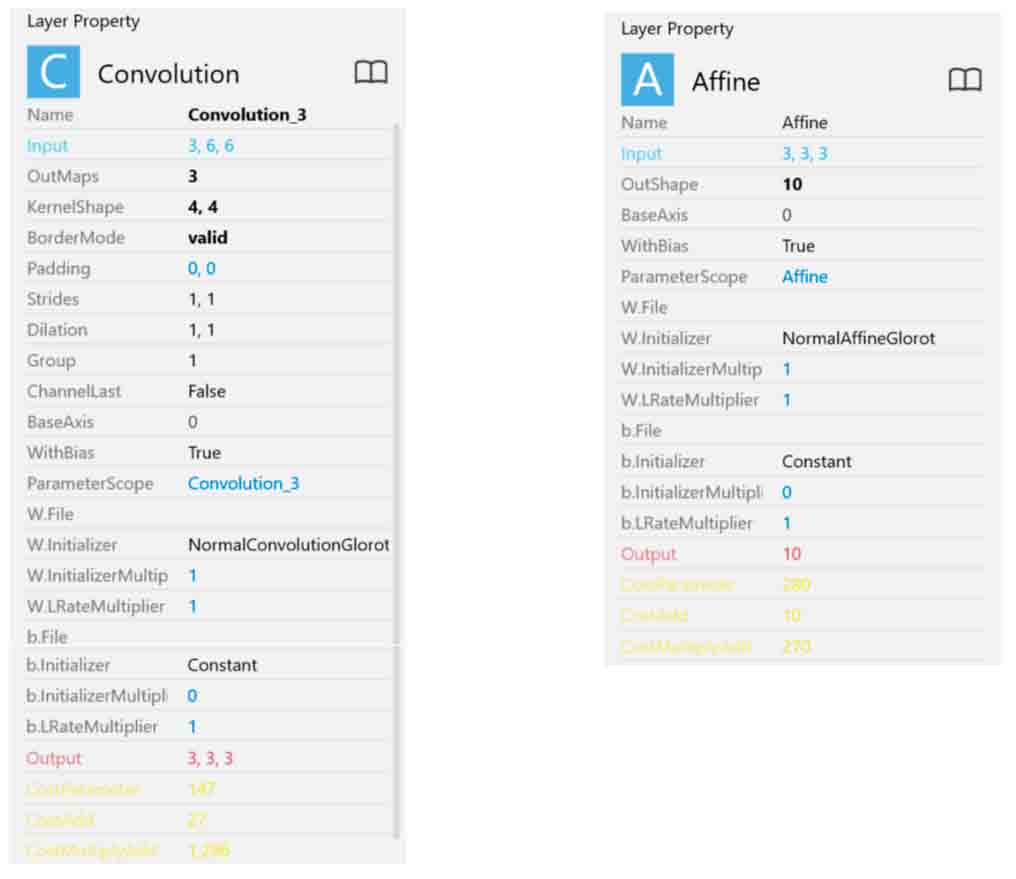
以上でできるだけコストを抑えた畳み込みニューラルネットワークができました。
1-02. 手書き数字MNISTデータセットで学習させる
では、学習させてみます。
Max Epoch は2000とし、その他はデフォルト設定で行いました。
結果、以下のグラフになりました。
(図01-01-06)
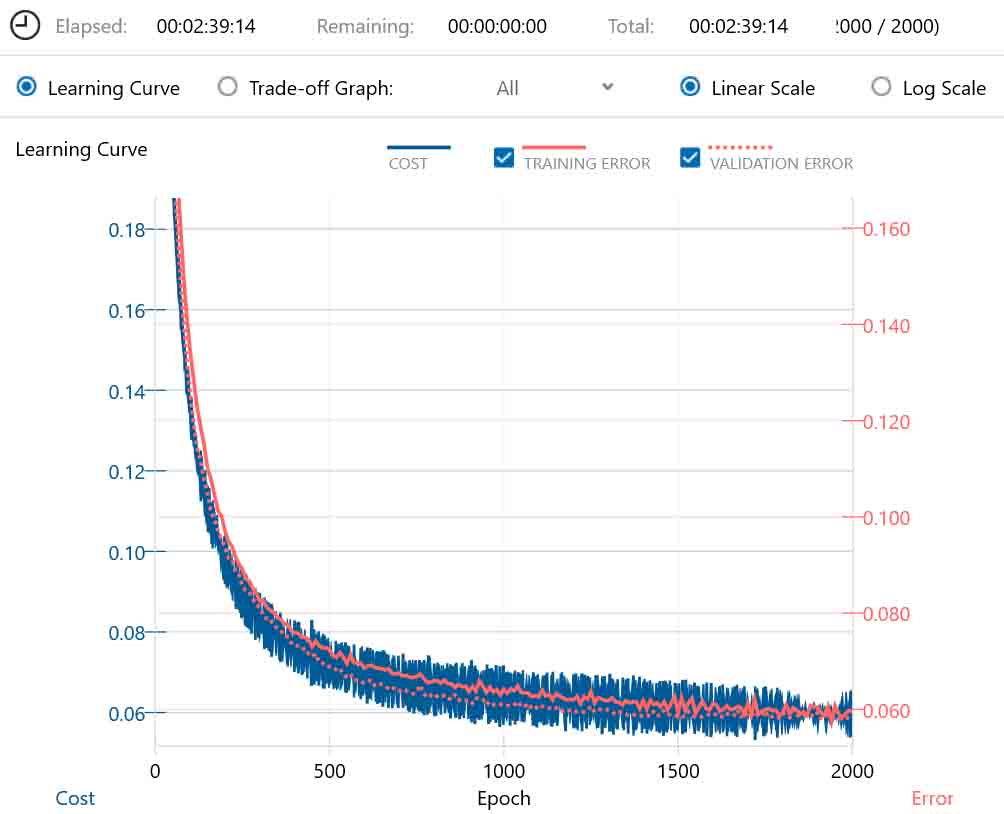
学習時間は2時間39分かかりました。
グラフを拡大してみても最後の方はほぼ横這いですから、これ以上学習させても効果は無いので、Max Epochは2000で良かったと思います。
では、評価結果は以下のようになりました。
(図01-01-07)
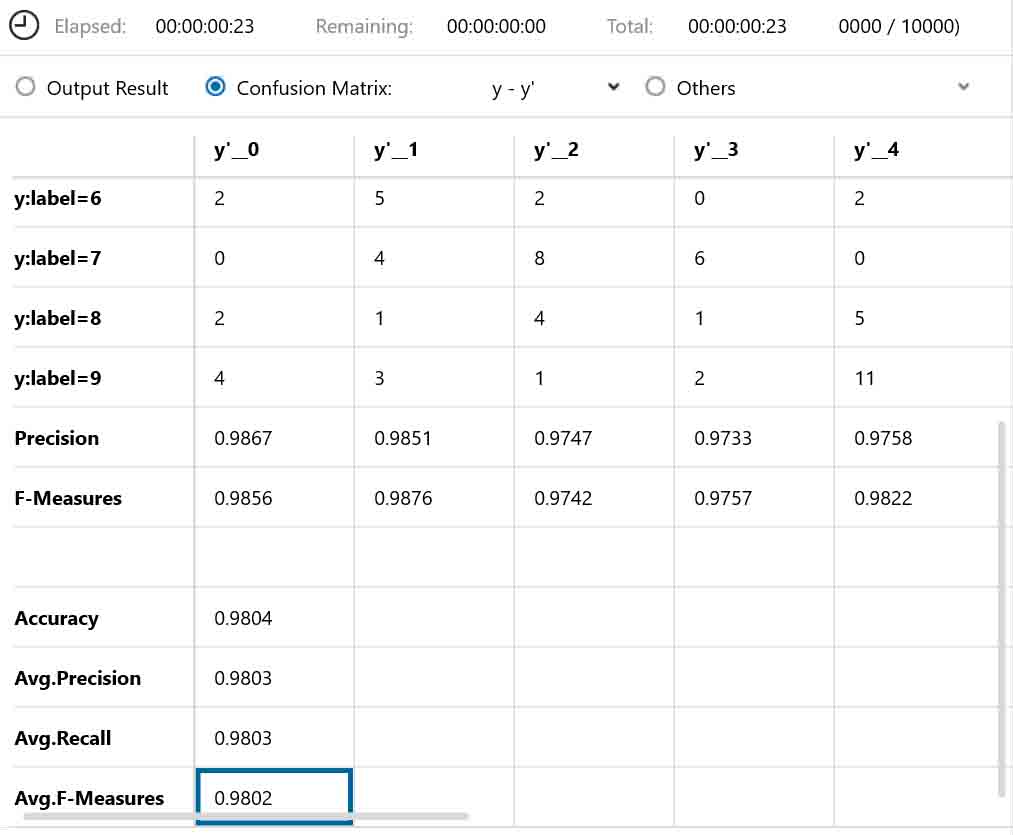
やった!
目標の正答率98%を超えました。
ところで、先に述べたコストパラメータの総数を見て下さい。
650個でしたね。
前回のこちらの記事のニューラルネットワークでは、評価が同等の98%越えでしたが、コストは983個でした。
よって、このニューラルネットワークは低コストで高正答率だということです。
この様に、低コストにしつつ正答率を上げるのがなかなか難しかったです。
いろんなパターンを試しましたが、正答率を上げるコツはConvolutionのストライドを1で死守することだと思います。
ストライドを2にしてしまうと、コストは下げられますが、正答率が途端に下がってしまうので要注意ですね。
それと、MaxPoolingも無い方が良いに決まっていますね。
1-03. 重みとバイアスパラメータをC言語形式でエクスポートする
では、低コスト高正答率の畳み込みニューラルネットワーク(CNN)が完成したので、学習済みのコストパラメータ(重みとバイアスパラメータ)をエクスポートして、C言語ヘッダファイルを作成します。
SONY Neural Network Console のエクスポート方法はこちらの記事を参照してください。
エクスポートされたファイルのうち、以下のファイルを使用します。
MainRuntime_parameters.h
MainRuntime_parameters.c
2.テスト用の畳み込みニューラルネットワークをArduinoスケッチ(プログラム)で組む
では、実際に畳み込みニューラルネットワーク(CNN)を自己流でプログラミングしていきたいと思います。
Arduino IDE でプログラミングしていきますが、先ほどエクスポートした重みとバイアスデータを取り込んでいくことになります。
2-01. Arduinoスケッチに重みとバイアスパラメータヘッダファイルを取り込む
では、まず、1-03節でエクスポートされた重みとバイアスパラメータのファイルをArduinoスケッチに取り込みます。
まず、Arduino IDE で新規にスケッチを作成し、名前を付けて保存しておきます。
(図02-01-01)
ここではtest_cnn01というファイル名にしておきます。
その後、一旦Arduino IDEを閉じます。
次に、その保存したスケッチフォルダをエクスプローラで開きます。
Windowsパソコンで、Arduino IDEがデフォルト設定の場合、
C:\Users\ユーザー名\Documents\Arduino\スケッチ名フォルダ
というパスになると思います。
そして、1-03節で重みとバイアスパラメータをエクスポートしたフォルダ開き、下図の様に
MainRuntime_parameters.h
MainRuntime_parameters.c
という2つのC言語ファイルをArduinoスケッチフォルダにコピー&ペーストします。
(図02-01-02)
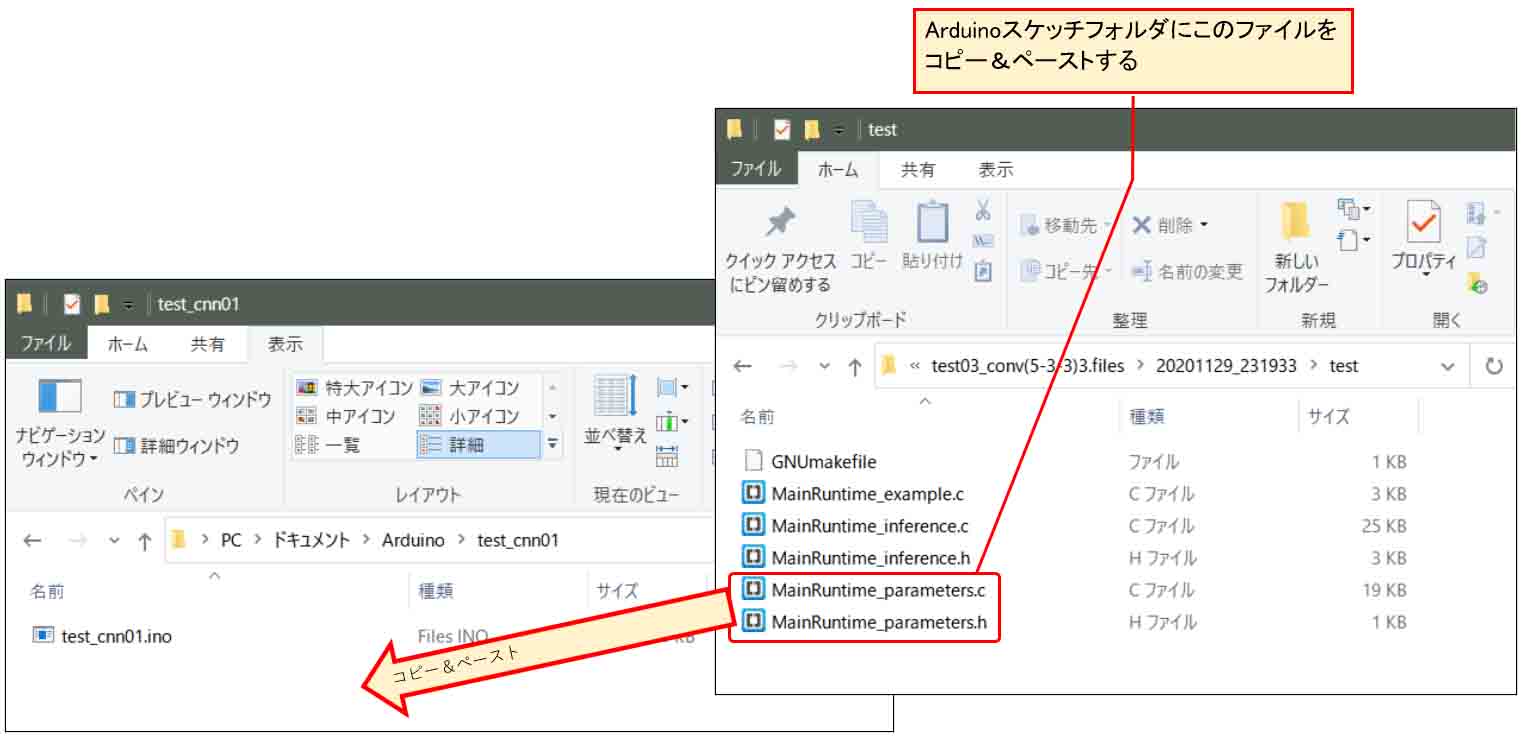
すると、こんな感じになると思います。
(図02-01-03)
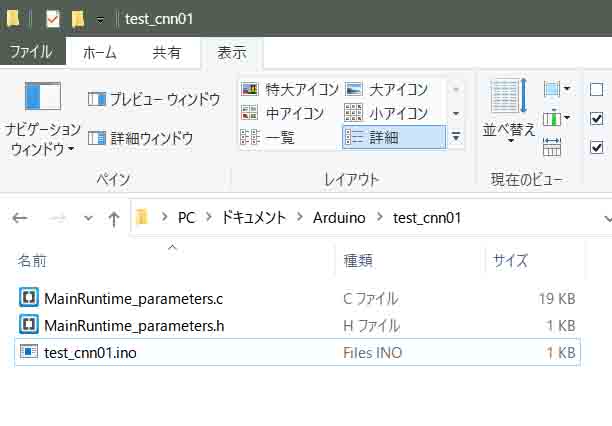
そうしたら、再びArduino IDEを起動し、先ほど保存したArduinoスケッチファイルを開きます。
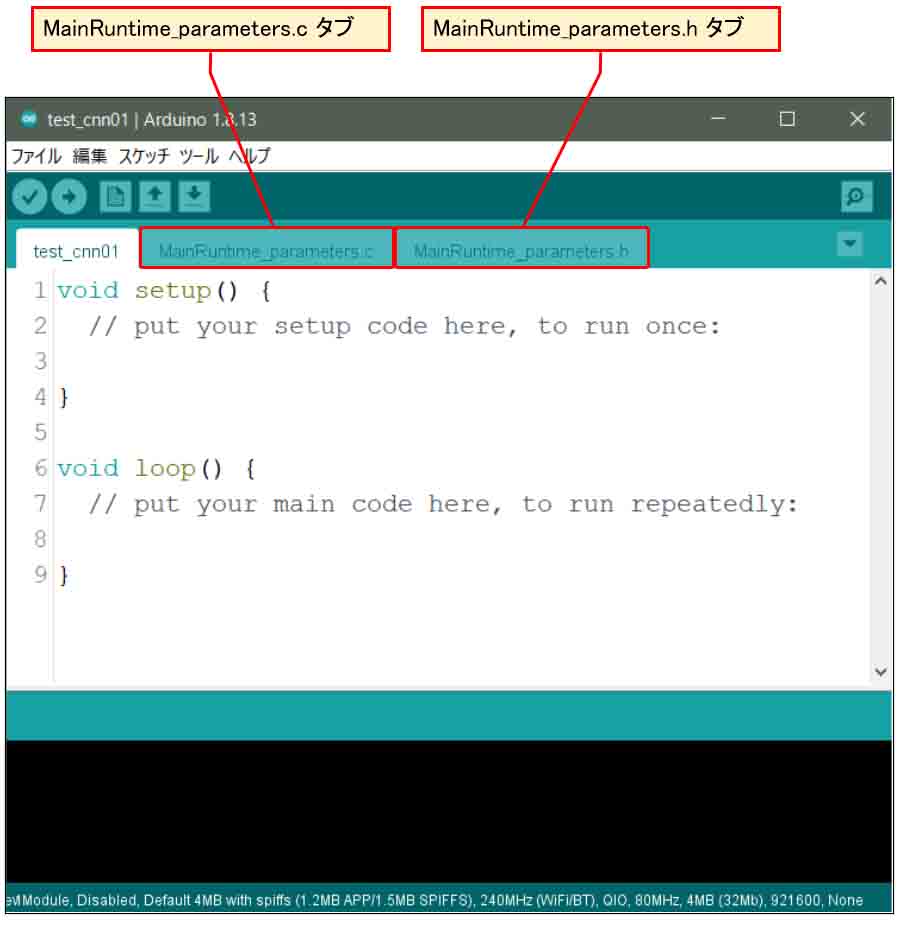
すると、以下のように、
MainRuntime_parameters.c
というタブと
MainRuntime_parameters.h
というタブが出来ていると思います。
これで、学習済み重みとバイアスパラメータを取り込むことができました。
(図02-01-04)
2-02. テスト用手書き数字ヘッダファイルを取り込む
次に、テスト用の1文字分の手書き数字MNISTデータをC言語ヘッダファイルに変換して、Arduinoスケッチファイルに組み込んでみます。
まず、下図の様にスケッチの右上方面に▼マークがあるので、そこをクリックし、「新規タブ」をクリックします。
(図02-02-01)
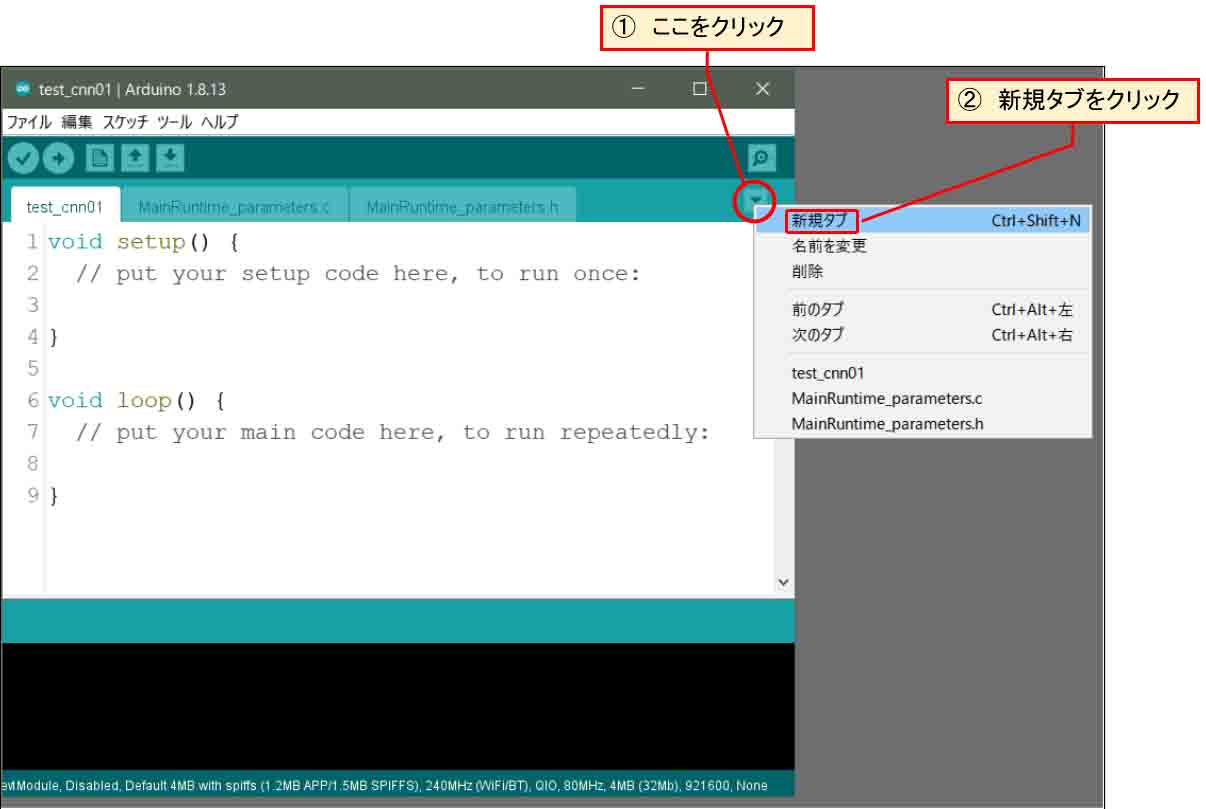
すると、下図の様にタブ名称入力欄が表示されるので、そこに仮に、
test_pix.h
というヘッダファイル名を入力して、OKをクリックします。
(図02-02-02)
すると、こんな感じで新たなタブができました。
(図02-02-03)
次に、手書き数字MNISTデータの中から正解が5という学習データをC言語の配列に変換したコードを作ります。
以下の感じです。
constexpr uint8_t input_pix[28 * 28] =
{0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,0,0,3,18,18,18,126,136,175,26,166,255,247,127,0,0,0,0,
0,0,0,0,0,0,0,0,30,36,94,154,170,253,253,253,253,253,225,172,253,242,195,64,0,0,0,0,
0,0,0,0,0,0,0,49,238,253,253,253,253,253,253,253,253,251,93,82,82,56,39,0,0,0,0,0,
0,0,0,0,0,0,0,18,219,253,253,253,253,253,198,182,247,241,0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,80,156,107,253,253,205,11,0,43,154,0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,14,1,154,253,90,0,0,0,0,0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,0,139,253,190,2,0,0,0,0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,0,11,190,253,70,0,0,0,0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,0,0,35,241,225,160,108,1,0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,0,0,0,81,240,253,253,119,25,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,0,0,0,0,45,186,253,253,150,27,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,16,93,252,253,187,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,249,253,249,64,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,0,0,0,0,46,130,183,253,253,207,2,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,0,0,39,148,229,253,253,253,250,182,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,24,114,221,253,253,253,253,201,78,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,23,66,213,253,253,253,253,198,81,2,0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,18,171,219,253,253,253,253,195,80,9,0,0,0,0,0,0,0,0,0,0,0,0,
0,0,0,0,55,172,226,253,253,253,253,244,133,11,0,0,0,0,0,0,0,0,0,0,0,0,0,0,
0,0,0,0,136,253,253,253,212,135,132,16,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0};
では、これを先ほどのスケッチ上のtest_pix.hタブにコピー&ペーストします。
すると、こんな感じです。
(図02-02-04)
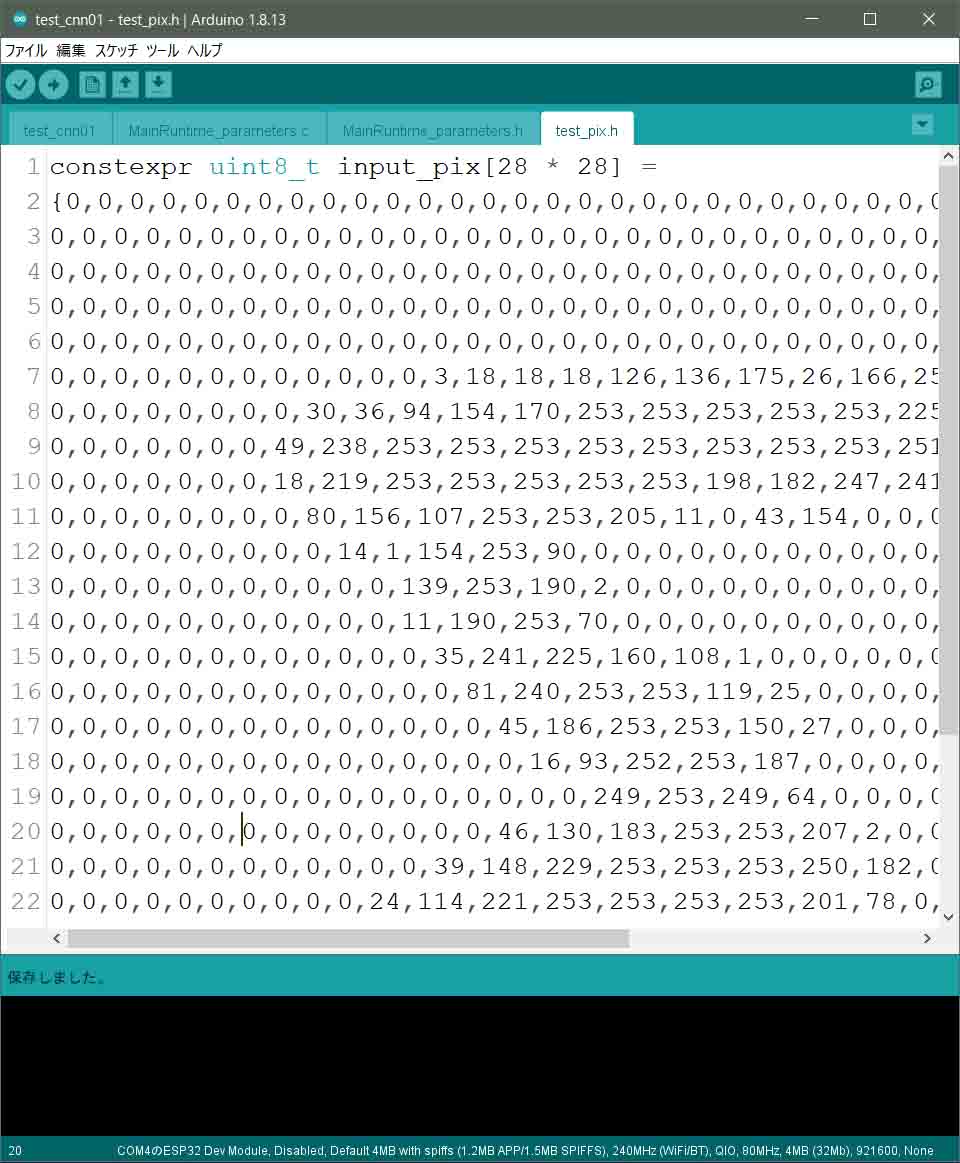
constexpr指定子は今回初めて使ってみました。
C++11以降で使えるらしく、Arduino core ESP32でも使えました。
これは、コンパイル時に計算して定数化してくれるみたいです。
constでも良いと思うのですが、28 * 28 という計算があるので、constexprとしてみました。
正直、const と constexprの使いどころの違いはよくわかっていませんので、何となく使ってみた感じです。
これで下準備ができました。
2-03. C++のvectorクラスを使って畳み込みニューラルネットワークの行列演算プログラミングをすることについて
幸い、Arduino core for the ESP32では、C++言語標準ライブラリのvectorクラスが使えるので、それで行列計算プログラミングをしていきます。
今までその存在は知ってはいたものの、実際にガッツリ使ったことは無かったのですが、今回使ってみて、行列計算にはとても便利だなと思いました。良い勉強になりました。
C言語の場合、行列計算は2次元配列をひたすらループ処理で一つ一つの要素を計算するプログラミングになると思われますが、C++のvectorクラスを使うと比較的簡単に構成できました。これを使わない手は無いですね。
でも、通常の配列やポインタの扱いとはちょっと異なるので注意が必要です。
Excelの場合、行列の内積計算はSUMPRODUCT関数を使いましたが、vectorでそれに相当するものは inner_product関数がありました。
それに、行列の中の要素を複製できるcopy関数や、行列の中の最大値を求めるmax_element関数等がありました。
そして、その最大値が行列のどこの位置にあるのかを示してくれるdistance関数もあって、とても便利です。
ただ、C言語の配列に相当するものをvectorで作ると、イテレータというポインタに相当するアドレスを使うことになるため、今までC言語ばかりやってきた私にとっては最初の頃はかなり混乱しました。
でも、しばらく使っていると慣れて来て、行列計算にはvectorは便利だなと思うようになりました。
おそらく、Pythonならばもっとやり易いんでしょうね。
2-04. vectorクラスのメモリ領域について
vectorクラスのメモリ領域について、簡単に触れておこうと思います。
(正直言って私は詳しくは知りませんので、間違えていたらスミマセン。)
C言語の配列でニューラルネットワーク用の行列を作る場合、2次元配列の宣言は以下の感じでゼロに初期化します。
uint8_t ary[28][28] = {0};
これが、vectorクラスを使うとC++03の場合、右山カッコが連続する場合はスペースが入る特殊な表記になるそうです。
vector<vector<uint8_t> > ary(28, vector<uint8_t>(28, 0));
これで28×28のbyte型の領域を確保できて、ゼロで初期化できます。
ただ、C++11の場合は、以下のように右山カッコを連続して表記できるようになっているそうです。
vector<vector<uint8_t>> ary(28, vector<uint8_t>(28, 0));
Arduino core for the ESP32では、どちらも使えました。
ということで、C++11が使えるようですね。
この記述方法はいろいろ歴史があってそうなったらしいのですが、最初は悩まされましたね。
そして、注意しなければならないのは、vectorクラスで領域を確保する場合のメモリ領域です。
Arduino core for the ESP32ではメインloop関数内の最大スタックメモリサイズは8192byteとなっています(stable ver 1.0.4の場合)。
これは、Arduino core for the ESP32内のmain.cppで定義されています。
配列の場合はスタックメモリ領域を使います。
これに対して、vectorクラスの場合は、可変長要素なのでヒープメモリ領域を使うようです。
ですから、領域を確保したら残りのヒープメモリ領域を常に把握しておき、使い終わったら出来るだけ早めにその領域を解放することが大事だと思います。
畳み込みニューラルネットワークを組む場合はそうしないとすぐにヒープメモリを使い果たしてしまいます。
C言語ではmalloc等で確保したヒープメモリはfreeで解放しますが、vectorの場合はswapを使うらしいです。
つまり、こんな感じだそうです。
vector<vector<float>>().swap(ary);
C++14の場合はswapよりもshrink_to_fitを使った方が良いらしいのですが、Arduino core for the ESP32(stable ver 1.0.4)では非対応みたいです。
よって、swapを使うしか無いようです。
ただ、この解放方法は全ての領域が完全に解放される保証は無いそうで、解放されない領域もあるらしいです。
ですから、以下の関数
esp_get_free_heap_size()
を使って、常にヒープメモリの残り容量を監視しておくことが大事なのかと思います。
2-05. Arduinoスケッチ入力(テスト用CNNプログラムコード作成)
では、いよいよ自己流でプログラミングした畳み込みニューラルネットワーク(CNN)のコードをスケッチに入力していきます。
まだC++のvectorクラスも使い始めたばかりで、無駄が多いと思います。
もっと良い方法をご存知ならば、コメント投稿でご連絡いただけるとうれしいです。
/* The MIT License (MIT)
* License URL: https://opensource.org/licenses/mit-license.php
* Copyright (c) 2020 Mgo-tec. All rights reserved.
*
* Use Arduino core for the ESP32 stable v1.0.4
*/
//#include <vector> //予めincludeされているため、不要。
#include "MainRuntime_parameters.h"
using namespace std;
class Conv {
public:
uint16_t input_vec_width;
uint16_t output_vec_width;
uint16_t output_padding;
uint16_t output_width_pad;
uint16_t kernel_width;
uint16_t kernel_size;
uint16_t output_size;
uint32_t w_addrs;
uint32_t b_addrs;
uint8_t input_node_num;
uint8_t output_node_num;
uint8_t stride;
float *weight;
float *bias;
};
class MaxPooling {
public:
uint16_t input_vec_width;
uint16_t output_vec_width;
uint16_t output_padding;
uint16_t output_width_pad;
uint16_t kernel_width;
uint16_t output_size;
uint8_t stride;
uint8_t output_node_num;
};
class Affine {
public:
uint16_t weight_size;
uint16_t output_node_num;
float *weight;
float *bias;
};
Conv fcnv, cnv2, lcnv;
MaxPooling mxp1, mxp2;
Affine afn1;
constexpr uint16_t in_pix_width = 28;
constexpr uint16_t inpix_size = in_pix_width * in_pix_width;
void setup() {
Serial.begin(115200);
Serial.println();
//初回convolutionパラメータ初期化
fcnv.input_vec_width = in_pix_width;
fcnv.output_padding = 1;
fcnv.stride = 1;
fcnv.kernel_width = 4;
fcnv.output_vec_width = 25;
fcnv.output_width_pad = fcnv.output_vec_width + fcnv.output_padding;
fcnv.kernel_size = fcnv.kernel_width * fcnv.kernel_width;
fcnv.w_addrs = 0;
fcnv.b_addrs = 0;
fcnv.output_node_num = 5;
fcnv.weight = (float *)MainRuntime_parameters[0];
fcnv.bias = (float *)MainRuntime_parameters[1];
fcnv.output_size = fcnv.output_width_pad * fcnv.output_width_pad;
//初回maxpoolingパラメータ初期化
mxp1.input_vec_width = fcnv.output_width_pad;
mxp1.output_vec_width = 13;
mxp1.output_padding = 0;
mxp1.output_width_pad = mxp1.output_vec_width + mxp1.output_padding;
mxp1.kernel_width = 2;
mxp1.stride = 2;
mxp1.output_node_num = fcnv.output_node_num;
mxp1.output_size = mxp1.output_width_pad * mxp1.output_width_pad;
//2回目convolutionパラメータ初期化
cnv2.input_vec_width = mxp1.output_vec_width;
cnv2.output_vec_width = 11;
cnv2.output_padding = 1;
cnv2.stride = 1;
cnv2.output_width_pad = cnv2.output_vec_width + cnv2.output_padding;
cnv2.kernel_width = 3;
cnv2.kernel_size = cnv2.kernel_width * cnv2.kernel_width;
cnv2.w_addrs = 0;
cnv2.b_addrs = 0;
cnv2.input_node_num = 5;
cnv2.output_node_num = 3;
cnv2.weight = (float *)MainRuntime_parameters[2];
cnv2.bias = (float *)MainRuntime_parameters[3];
cnv2.output_size = cnv2.output_width_pad * cnv2.output_width_pad;
//2回目maxpoolingパラメータ初期化
mxp2.input_vec_width = cnv2.output_width_pad;
mxp2.output_vec_width = 6;
mxp2.output_padding = 0;
mxp2.output_width_pad = mxp2.output_vec_width + mxp2.output_padding;
mxp2.kernel_width = 2;
mxp2.stride = 2;
mxp2.output_node_num = cnv2.output_node_num;
mxp2.output_size = mxp2.output_width_pad * mxp2.output_width_pad;
//最終段convolutionパラメータ初期化
lcnv.output_vec_width = 3;
lcnv.input_vec_width = 6;
lcnv.output_padding = 0;
lcnv.kernel_width = 4;
lcnv.kernel_size = lcnv.kernel_width * lcnv.kernel_width;
lcnv.stride = 1;
lcnv.w_addrs = 0;
lcnv.b_addrs = 0;
lcnv.input_node_num = 3;
lcnv.output_node_num = 3;
lcnv.weight = (float *)MainRuntime_parameters[4];
lcnv.bias = (float *)MainRuntime_parameters[5];
lcnv.output_size = lcnv.output_node_num * lcnv.output_vec_width * lcnv.output_vec_width;
//affineパラメータ初期化
afn1.weight_size = lcnv.output_size;
afn1.output_node_num = 10;
afn1.weight = (float *)MainRuntime_parameters[6];
afn1.bias = (float *)MainRuntime_parameters[7];
}
void loop() {
Serial.printf("Start remaining heap size = %d\r\n", esp_get_free_heap_size());
vector<float> input_pix_vec(inpix_size, 0);
input_layer(input_pix_vec, inpix_size);
//シリアルモニターに画素を表示
serial_print_pixels(input_pix_vec);
//ここから畳み込みニューラルネットワーク
uint32_t cnn_time = micros(); //畳み込みニューラルネットワーク計算時間測定開始
//Serial.println("------------convolution1------------");
vector<vector<float>> conv1_out_vec(fcnv.output_node_num, vector<float>(fcnv.output_size, -300.0f));
first_convolution(input_pix_vec, fcnv, conv1_out_vec);
//Serial.println("------------maxpooling1------------");
vector<float>().swap(input_pix_vec); //vectorコンテナ解放
vector<vector<float>> maxpool1_out_vec(mxp1.output_node_num, vector<float>(mxp1.output_size, 0.0f));
maxpooling(conv1_out_vec, mxp1, maxpool1_out_vec);
//Serial.println("------------tanh1------------");
for(int i = 0; i < mxp1.output_node_num; i++){
tanh_f(maxpool1_out_vec[i]);
}
//Serial.println("------------conv2----------");
//この環境ではメモリ解放にshrink_to_fitは使えない
vector<vector<float>>().swap(conv1_out_vec); //vectorコンテナ解放
vector<vector<float>> conv2_out_vec(cnv2.output_node_num, vector<float>(cnv2.output_size, -300.0f));
convolution(maxpool1_out_vec, cnv2, conv2_out_vec);
//Serial.println("------------maxpooling2------------");
vector<vector<float>>().swap(maxpool1_out_vec); //vectorコンテナ解放
vector<vector<float>> maxpool2_out_vec(mxp2.output_node_num, vector<float>(mxp2.output_size, 0.0f));
maxpooling(conv2_out_vec, mxp2, maxpool2_out_vec);
//Serial.println("------------tanh2------------");
for(int i = 0; i < mxp2.output_node_num; i++){
tanh_f(maxpool2_out_vec[i]);
}
//Serial.println("------------conv3----------");
vector<vector<float>>().swap(conv2_out_vec); //vectorコンテナ解放
vector<float> conv3_out_vec(lcnv.output_size, -300.0f);
last_convolution(maxpool2_out_vec, lcnv, conv3_out_vec);
//Serial.println("------------tanh3------------");
tanh_f(conv3_out_vec);
//Serial.println("------------affine----------");
vector<vector<float>>().swap(maxpool2_out_vec); //vectorコンテナ解放
vector<float> affine_out_vec(afn1.output_node_num, -300.0f);
affine(conv3_out_vec, afn1, affine_out_vec);
//affine出力値を表示
/*
Serial.println("affine");
for(int i = 0; i < 10; i++){
Serial.printf("[%d] %7.5lf\r\n", i, affine_out_vec[i]);
}
Serial.println();
*/
//Serial.println("------------softmax----------");
vector<float>().swap(conv3_out_vec); //vectorコンテナ解放
vector<float> softmax_out_vec(afn1.output_node_num, 0.0f);
softmax(affine_out_vec, softmax_out_vec);
vector<float>().swap(affine_out_vec); //vectorコンテナ解放
vector<float>::iterator iter = max_element(softmax_out_vec.begin(), softmax_out_vec.end());
uint8_t index = distance(softmax_out_vec.begin(), iter);
cnn_time = micros() - cnn_time;
//softmax出力値を表示
Serial.println("softmax");
for(int i = 0; i < 10; i++){
Serial.printf("[%d] %7.5lf\r\n", i, softmax_out_vec[i]);
}
Serial.println();
vector<float>().swap(softmax_out_vec); //vectorコンテナ解放
Serial.printf("result = %d\r\n", index);
Serial.printf("CNN calculation time = %d us\r\n", cnn_time);
Serial.printf("Last remaining heap size = %d\r\n\r\n", esp_get_free_heap_size());
delay(5000);
}
void input_layer(vector<float> &inpix_vec, uint16_t inpx_size){
#include "test_pix.h" //ここでincludeしてメモリ節約
//全ての要素を0~1.0の範囲のfloat型に変換
int i = inpx_size - 1;
do{
inpix_vec[i] = (float)input_pix[i] / 255.0f;
--i;
}while(i >= 0);
}
void serial_print_pixels(vector<float> &input_pix_vec){
Serial.println("------------------------------------------------------------");
int i, j;
for(j = 0; j < in_pix_width; j++){
for(i = 0; i < in_pix_width; i++){
//Serial.printf("%03d,",pre_maxpool_vec[ary_cnt]);
if(input_pix_vec[i + j * in_pix_width] > 0){
Serial.print('#');
//Serial.printf("%7.5lf,", input_pix_vec[i + j * in_pix_width]);
} else {
Serial.print(' ');
}
}
Serial.println();
}
Serial.println("------------------------------------------------------------");
}
void first_convolution(vector<float> &input_pix, Conv &conv, vector<vector<float>> &output_vec){
int i;
for(i = 0; i < conv.output_node_num; i++){
conv.w_addrs = i * conv.kernel_size;
conv.b_addrs = i;
first_conv_tmp(input_pix, conv, output_vec[i]);
}
}
void first_conv_tmp(vector<float> &input_pix, Conv &conv, vector<float> &output_vec){
vector<float> weight_vec(conv.kernel_size, 0.0f);
vector<float> in_kernel_vec(conv.kernel_size, 0.0f);
weight_vec.assign(conv.weight + conv.w_addrs, conv.weight + conv.w_addrs + conv.kernel_size);
uint16_t vec_index = 0;
uint16_t max_vec_count = conv.input_vec_width - (conv.kernel_width - 1);
float innr_prod = 0.0f;
int i, j;
for(j = 0; j < max_vec_count; j = j + conv.stride){
for(i = 0; i < max_vec_count; i = i + conv.stride){
fcnv_inner_prod_output(input_pix, weight_vec, in_kernel_vec, conv, i, j, innr_prod);
output_vec[vec_index] = innr_prod + conv.bias[conv.b_addrs];
vec_index++;
}
vec_index = vec_index + conv.output_padding;
}
}
void fcnv_inner_prod_output(vector<float> &input_pix, vector<float> &weight_vec, vector<float> &in_kernel_vec, Conv &conv, int x_elm, int y_elm, float &innr_p){
uint16_t vec_index = 0;
int i, j;
int ix;
int iy = 0;
j = conv.kernel_width - 1;
do{
ix = 0;
i = conv.kernel_width - 1;
do{
in_kernel_vec[vec_index++] = input_pix[ix + x_elm + ((iy + y_elm) * conv.input_vec_width)];
++ix;
--i;
}while(i >= 0);
++iy;
--j;
}while(j >= 0);
innr_p = inner_product(weight_vec.begin(), weight_vec.end(), in_kernel_vec.begin(), 0.0f);
}
void convolution(vector<vector<float>> &input_vec, Conv &conv, vector<vector<float>> &output_vec){
int i;
for(i = 0; i < conv.output_node_num; i++){
conv.w_addrs = i * (conv.kernel_size * conv.input_node_num);
conv.b_addrs = i;
conv_tmp(input_vec, conv, output_vec[i]);
}
}
void conv_tmp(vector<vector<float>> &input_vec, Conv &conv, vector<float> &output_vec){
vector<vector<float>> weight_vec(conv.input_node_num, vector<float>(conv.kernel_size, 0.0f));
vector<vector<float>> in_kernel_vec(conv.input_node_num, vector<float>(conv.kernel_size, 0.0f));
for(int i = conv.input_node_num - 1; i >= 0; --i){
weight_vec[i].assign(conv.weight + conv.w_addrs + (i * conv.kernel_size), conv.weight + conv.w_addrs + ((i + 1)* conv.kernel_size));
}
uint16_t vec_index = 0;
uint16_t max_vec_count = conv.input_vec_width - (conv.kernel_width - 1);
float tmp1 = 0.0f;
int i, j;
for(j = 0; j < max_vec_count; j = j + conv.stride){
for(i = 0; i < max_vec_count; i = i + conv.stride){
tmp1 = 0.0f;
inner_prod_output(input_vec, weight_vec, in_kernel_vec, conv, i, j, tmp1);
output_vec[vec_index++] = tmp1 + conv.bias[conv.b_addrs];
}
vec_index = vec_index + conv.output_padding;
}
}
void inner_prod_output(vector<vector<float>> &input_vec, vector<vector<float>> &weight_vec, vector<vector<float>> &in_kernel_vec, Conv &conv, int x_elm, int y_elm, float &innr_p){
vector<float>::const_iterator itr;
int cnt1;
int cnt2 = 0;
int i;
int j = conv.input_node_num - 1;
do{
cnt1 = 0;
i = conv.kernel_width - 1;
do{
itr = input_vec[cnt2].begin() + x_elm + ((cnt1 + y_elm) * conv.input_vec_width);
copy(itr, itr + conv.kernel_width, in_kernel_vec[cnt2].begin() + (cnt1 * conv.kernel_width));
++cnt1;
--i;
}while(i >= 0);
innr_p = innr_p + inner_product(weight_vec[cnt2].begin(), weight_vec[cnt2].end(), in_kernel_vec[cnt2].begin(), 0.0f);
++cnt2;
--j;
}while(j >= 0);
}
void tanh_f(vector<float> &input_vec){
for(float &x: input_vec){
x = tanhf(x);
}
}
void maxpooling(vector<vector<float>> &input_vec, MaxPooling &mpl, vector<vector<float>> &output_vec){
int i;
for(i = 0; i < mpl.output_node_num; i++){
maxpooling_tmp(input_vec[i], mpl, output_vec[i]);
}
}
void maxpooling_tmp(vector<float> &input_vec, MaxPooling &mpl, vector<float> &output_vec){
uint16_t vec_index = 0;
uint16_t max_vec_count = mpl.input_vec_width - (mpl.kernel_width - 1);
vector<float> in_kernel_vec(mpl.kernel_width * mpl.kernel_width, -400.0f);
int i, j;
for(j = 0; j < max_vec_count; j = j + mpl.stride){
for(i = 0; i < max_vec_count; i = i + mpl.stride){
if(vec_index >= output_vec.size()) return;
max_elm_output(input_vec, in_kernel_vec, mpl, i, j, output_vec[vec_index]);
vec_index++;
}
}
}
void max_elm_output(vector<float> &input_vec, vector<float> &in_kernel_vec, MaxPooling &mpl, int x_elm, int y_elm, float &output){
vector<float>::const_iterator itr;
int iy = 0;
int i = mpl.kernel_width - 1;
do{
itr = input_vec.begin() + x_elm + (y_elm + iy) * mpl.input_vec_width;
copy(itr, itr + mpl.kernel_width, in_kernel_vec.begin() + (iy * mpl.kernel_width));
++iy;
--i;
}while(i >= 0);
output = *max_element(in_kernel_vec.begin(), in_kernel_vec.end());
}
void last_convolution(vector<vector<float>> &input_vec, Conv &conv, vector<float> &output_vec){
vector<vector<float>> weight_vec(conv.input_node_num, vector<float>(conv.kernel_size, 0.0f));
vector<vector<float>> in_kernel_vec(conv.input_node_num, vector<float>(conv.kernel_size, 0.0f));
uint16_t vec_index = 0;
int i, j, k;
for(k = 0; k < conv.output_node_num; k++){
conv.w_addrs = k * (conv.kernel_size * conv.input_node_num);
conv.b_addrs = k;
float tmp1 = 0.0f;
for(i = conv.input_node_num - 1; i >= 0; --i){
weight_vec[i].assign(conv.weight + conv.w_addrs + (i * conv.kernel_size), conv.weight + conv.w_addrs + ((i + 1)* conv.kernel_size));
}
for(j = 0; j < conv.output_vec_width; j = j + conv.stride){
for(i = 0; i < conv.output_vec_width; i = i + conv.stride){
inner_prod_output(input_vec, weight_vec, in_kernel_vec, conv, i, j, tmp1);
output_vec[vec_index++] = tmp1 + conv.bias[conv.b_addrs];
tmp1 = 0.0f;
}
}
}
}
void affine(vector<float> &input_vec, Affine &affine, vector<float> &output_vec){
vector<float> weight_vec(affine.weight_size, 0.0f);
int i = affine.output_node_num - 1;
do{
weight_vec.assign(affine.weight + (affine.weight_size * i), affine.weight + (affine.weight_size * i) + affine.weight_size);
output_vec[i] = inner_product(weight_vec.begin(), weight_vec.end(), input_vec.begin(), 0.0f) + affine.bias[i];
--i;
}while(i >= 0);
}
void softmax(vector<float> &input_vec, vector<float> &output_vec){
float sum_exp = 0.0f;
float tmp[input_vec.size()];
int i = input_vec.size() - 1;
do{
tmp[i] = expf(input_vec[i]);
sum_exp += tmp[i];
--i;
}while(i >= 0);
i = input_vec.size() - 1;
do{
if(sum_exp == 0.0f){
Serial.println("Error! sum_exp.");
}
output_vec[i] = tmp[i] / sum_exp;
--i;
}while(i >= 0);
}
【ザックリ解説】
●8行目:
Arduino core for the ESP32 では、予めvectorがインクルードされているので、スケッチ上でのインクルードは不要です。
●9行目:
2-01節で述べたように、スケッチフォルダに取り込んだ重みとバイアスパラメータのヘッダファイルをインクルードします。
#include はコンパイルする時にその位置にソースコードを展開します。
つまり、MainRuntime_parameters.c というソースコードがグローバル領域で展開され、重みとバイアスの多量のパラメータ配列が宣言および初期化されます。
すると、グローバル領域のメモリがかなり消費されることになります。
MainRuntime_parameters.c のコードを崩してメモリを節約したかったのですが、SONY Neural Network Console のエクスポートファイルをそのまま使った方が簡単なので、今回はこれで行こうと思います。
●11行目:
std::vectorクラスを使う場合、毎回std::と入力する手間を省くため、
using namespace std;
とします。
ただ、usingは一長一短があって、名前衝突の可能性があることを念頭に置く必要があると思います。
●13-49行:
Convolution、MaxPooling、Affineのレイヤーパラメータの定義にはクラスを使いました。
構造体でも良いのですが、せっかくC++が使えるので、クラスにしました。
●63-132行:
各層のパラメータ初期化です。
●136-222行:
メインloop関数で、5秒毎に繰り返します。
基本的にvectorの2次元行列コンテナの領域を確保し、ConvolutionやMaxPoolingなどの層を計算し、その後、不要になったコンテナをswap関数で解放して、ヒープメモリを節約しています。
この方法が正しいのかよくわかりませんが、とりあえずうまく行っているのでヨシとします。
204行目でvectorのmax_element関数を使って、softmax出力値の最大値のイテレータを取得し、distance関数で10個のコンテナ要素の位置を取得して、それを判定結果として出力しています。
●225-233行:
手書き数字MNISTのデータ test_pix.h を全て255で割って、float型のvectorコンテナに変換する関数です。
ここのポイントは、226行でtest_pix.h をインクルードしていることです。
最近、個人的にこの技を習得しました。
includeは最初に記述するものだと固定観念がありましたが、includeって単にそこにコードを展開するだけだということを思い出して、試しに関数内でincludeしたらうまく行きました。スタック領域のメモリ節約になったのです。
つまり、配列宣言を関数内で行えば、関数を抜けるとメモリを解放してくれるわけです。
不思議なのが、グローバル領域でincludeするより、この関数内でincludeするとヒープメモリに余裕ができました。この理由はよくわかりません。
●253-447行:
後で述べていますが、Excelファイルで畳み込みニューラルネットワークの計算式を組んでテストしてみて、それに習って各層を関数に分けてプログラミングしてみました。
forループやwhileループについては、micros関数で時間計測しながらいろいろ試した結果、現状知り得る方法で一番速いものを選んで組んでみました。
速度重視のプログラミングにすると、可読性が悪くなりますが仕方ありません。
もっと良い方法があったら教えて頂きたいですね。
いつか、ループ処理の高速化については記事にしたいと思っています。
2-06. コンパイル書き込みおよび出力結果
前節のソースコードをArduino IDEに入力し終ったら、ESP32開発ボードをパソコンとUSB接続します。
Arduino IDEのツールメニューのボード設定は以下でOKです。
シリアルポートはご自分のパソコンのUSBポートを指定します。
(図02-06-01)
Upload Speed: 921600
CPU Frequency: 240MHz (WiFi/BT)
Flash Frequency: 80MHz
Flash Mode: QIO
Flash Size: 4MB (32Mb)
Partition Scheme: Default 4MB width spiffs (1.2MB APP/1.5MB SPIFFS)
Core Debug Level: なし
PSRAM: Disabled
シリアルポート: ※ESP32ボードに接続してあるUSBポート
その後、シリアルモニターを115200bpsで起動し、コンパイル書き込み実行させます。
すると、以下のようになりました。
5秒毎に新たに計算していますが、これは初回の計算値です。
(図02-06-02)
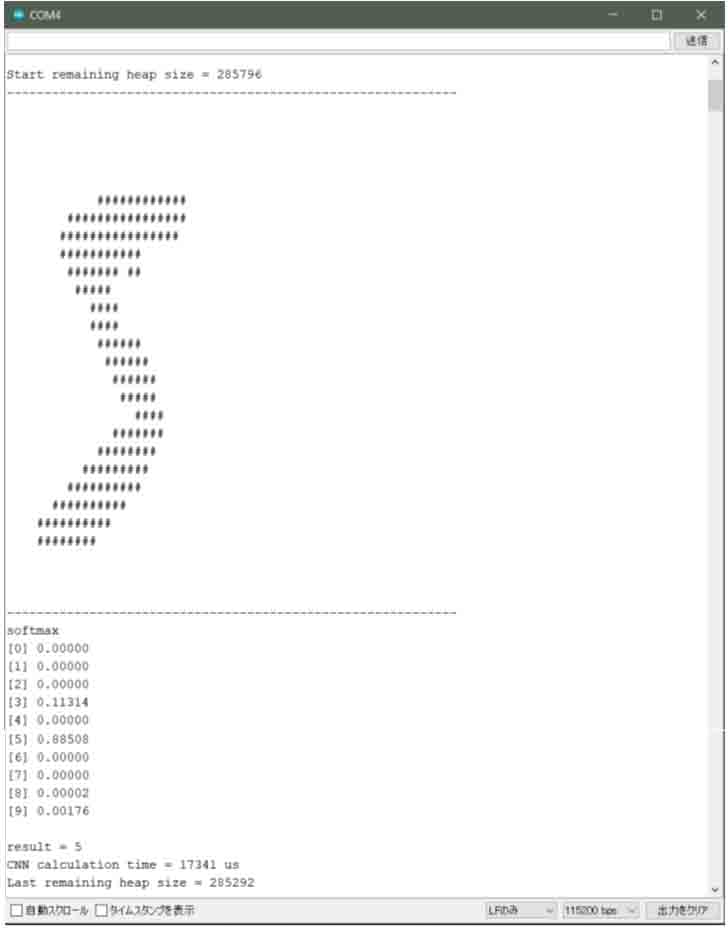
入力層の画素を’#’文字で表示し、その後にsoftmax出力値を出力しています。
その最大値のvectorコンテナのインデックス値が判定結果resultとなります。
result = 5
と表示されていれば、手書き数字MNISTの正解データと一致しするのでOKというわけです。
この初回の計算では、ニューラルネットワーク計算に入る前のヒープメモリサイズ
Start remaining heap size = 285796
となっていて、計算完了後のサイズは
Last remaining heap size = 285292
となっています。
あれ?
やっぱり、swapではヒープメモリが解放されない部分が残ってしまったのかな?
では、5秒毎に再計算されるので、その結果を見てみます。
すると以下のようになりました。
(図02-06-03)
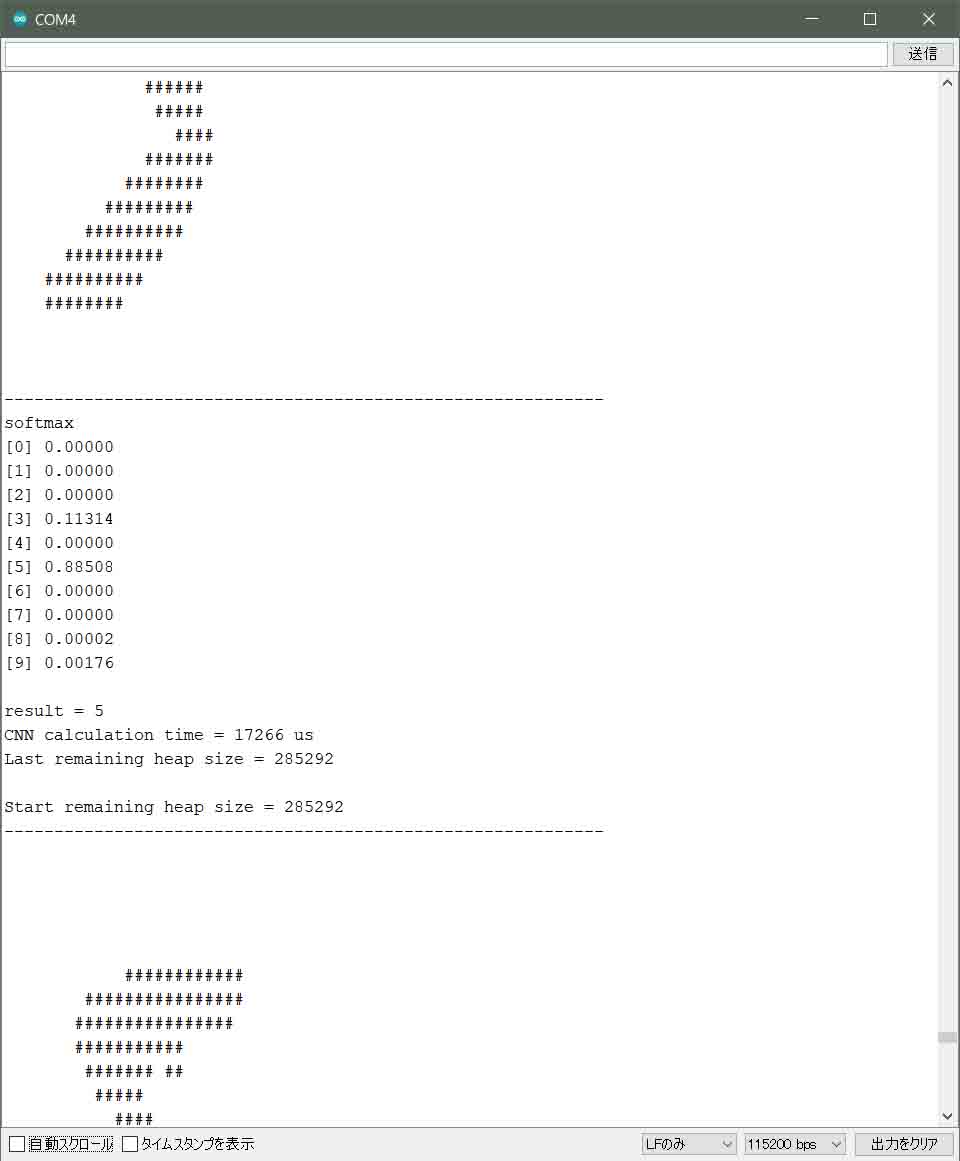
残りのヒープメモリサイズは285292で落ち着いています。
ということは、loop関数の初回はごく小さな不明なヒープメモリを消費していますが、loopを繰り返す毎にちゃんとswap関数でヒープメモリが解放されていることがわかると思います。
ところで、この判定結果はたまたま合っていただけかも知れませんね。
では、この結果が本当に合っているか検証してみます。
まず、前段のAffineの出力結果を見たいですね。
その場合、ソースコードの190行と196行のコメントを外してコンパイル書き込みし直し、affineの出力値を見てみます。
こんな感じです。
(図02-06-04)
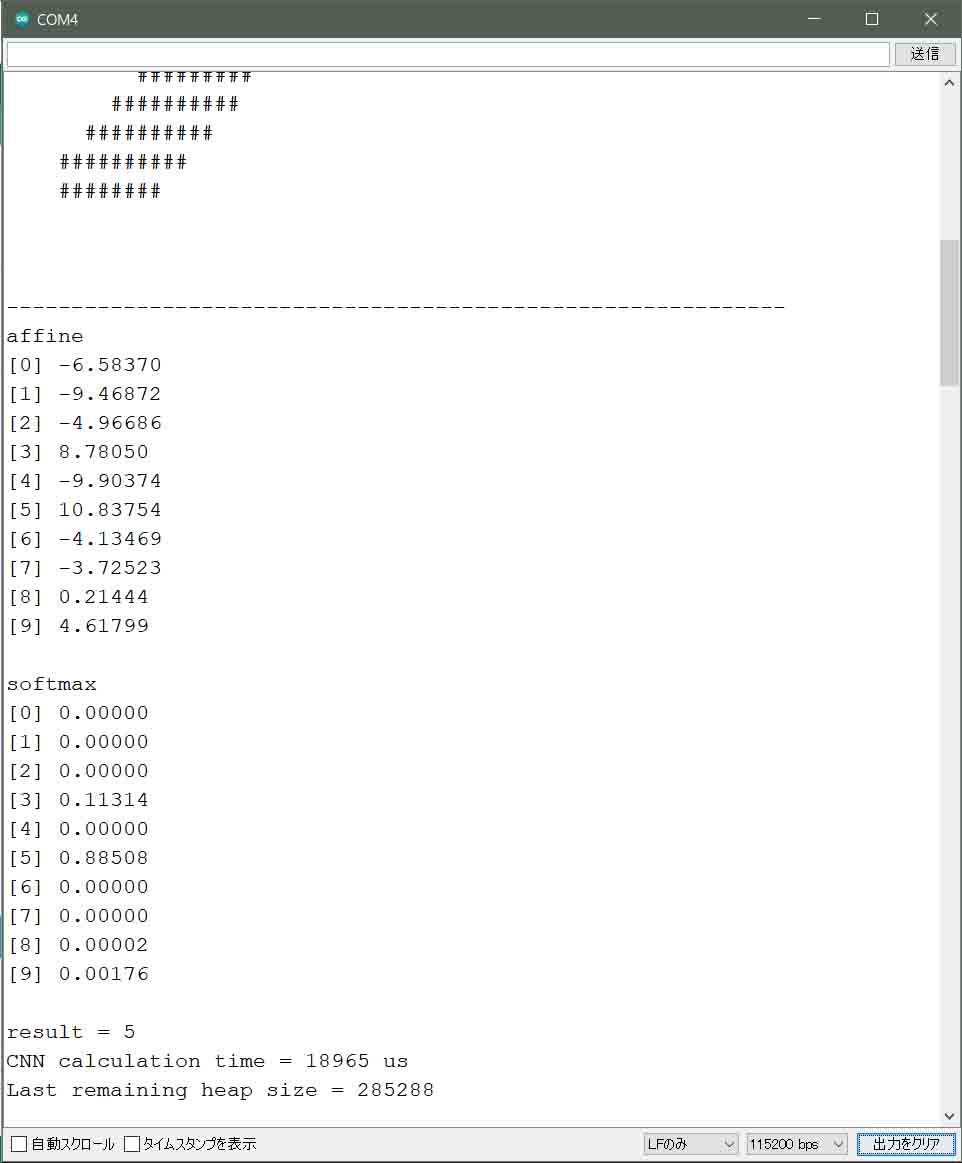
このaffine出力結果が合っているかどうかは、SONY Neural Network Console でもゴニョゴニョすると確認できるのですが、それよりも、Excelで同じニューラルネットワークを組んで確かめた方が個人的にはしっくりきました。
ただ、そのExcelの計算結果が合っているかも検証しなければならないです。
ざっくり言うと、要するにExcelで1000パターンを計算させた正解率が98%を超えていれば、恐らく正しいと言えます。
または、SONY Neural Network Consoleで途中結果を出力(結構難しい)させて、Excelの出力結果と照合していけば良いと思います。
そんなわけで、私は予め1章で学習させた畳み込みニューラルネットワークと途中出力を照合して、正しい計算式のExcelファイル作って置きました。
GitHubの以下のリンクに置いておきますので参考にしてみてください。
これは5という手書き数字の1パターンのみの計算ファイルです。
https://github.com/mgo-tec/test_excel_deeplearning/blob/master/ESP32_CNN/cnn(5_3_3)01.xlsx
これを開いて、Affineの出力値の所を見てみるとこんな感じです。
(図02-06-05)
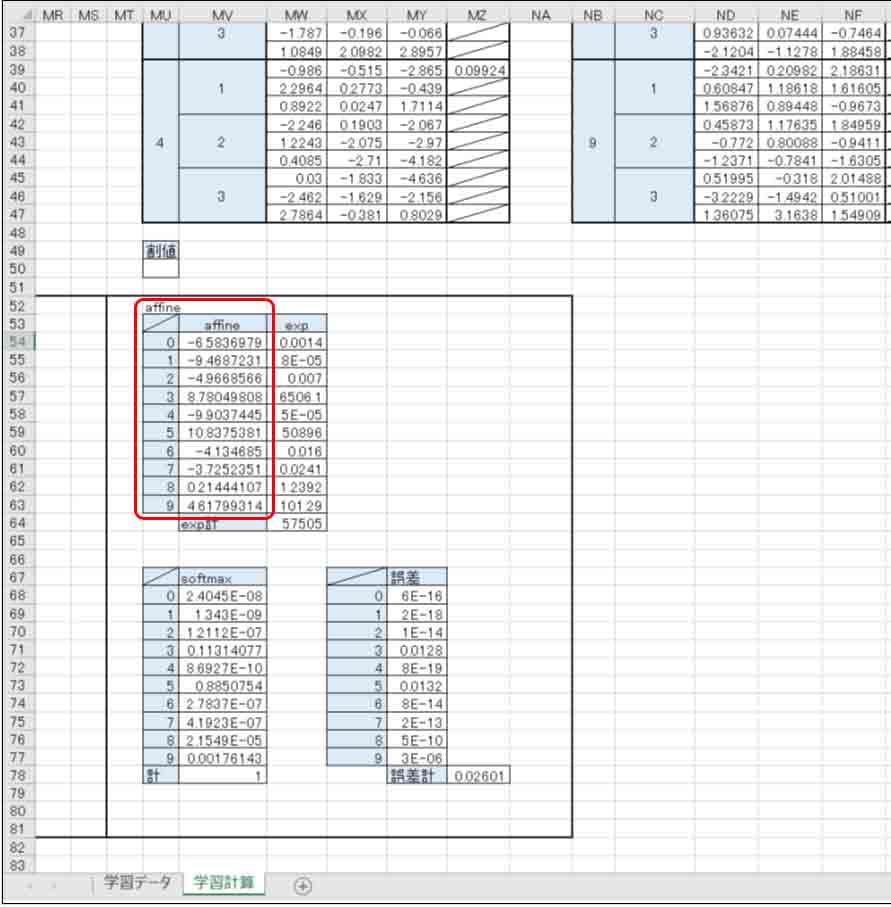
この出力結果と先ほどのシリアルモニターのaffine出力結果と照合してみると、ピタリと一致していますね。
これで、Arduino core ESP32で組んだニューラルネットワークのプログラミングが正しいと分かりました。
また、シリアルモニターで畳み込みニューラルネットワーク(CNN)の計算時間を見てみると、約17μsでした。
最初の頃にプログラミングした時には36μsだったので半分以下まで抑えられました。
forループやwhileループを試行錯誤した結果だと思います。
おそらく、プロのプログラマならばもっと高速にできるんでしょうね。
ところで、ExcelのCNNを見てみると、表がメチャメチャ多くて、計算コストが膨大だということが分かると思います。
重みとバイアスだけに絞ってピックアップしてみてみると、こんな感じです。
(図02-06-06)
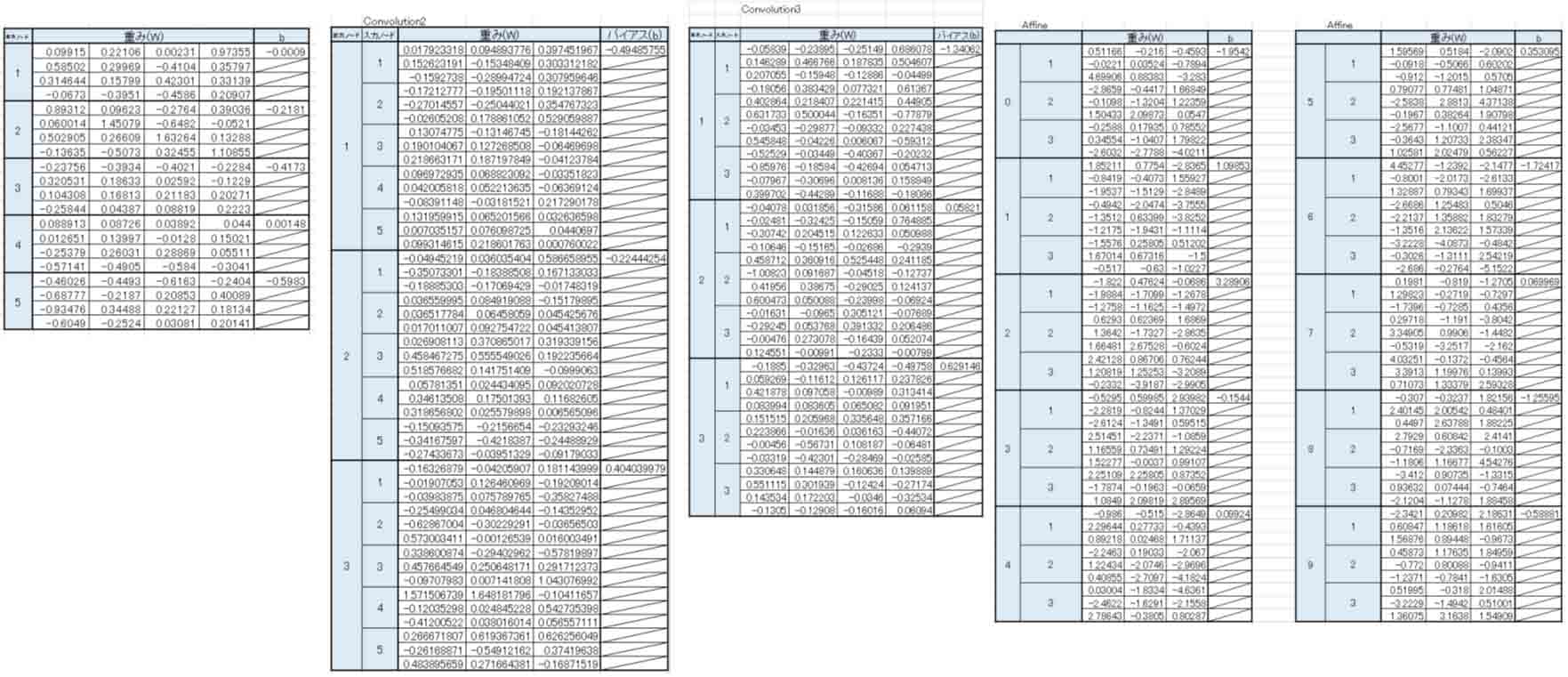
これだけでも結構すごいですね。
重みとバイアスパラメータの総数(コストパラメータ)が650ですから、前回記事までのエクセル計算の比ではありませんね。
こりゃぁ、非力なマイコンには厳しいわけです。
では、次はイメージセンサとESP32を組み合わせた画像認識に挑戦してみます。
3.M5Cameraを使ったリアルタイム画像認識Arduinoスケッチ(プログラム)作成
では、いよいよ夢のリアルタイム画像認識に足を踏み入れるべく、M5Cameraのイメージセンサとマイコンを使って畳み込みニューラルネットワーク(CNN)をプログラミングしてみたいと思います。
Arduino core for the ESP32内にある、ESP32 Camera Driverライブラリを使います。
これを使うと、スタックメモリ容量がギリギリです。
本当は、Neural Network Consoleからインポートした重みやバイアスパラメータファイルをインクルードせずに、そのデータを解体して個別に取り込んだ方がスタックメモリの節約になるのですが、今回はそのまま使ってみました。
よって、スタックメモリはパツパツなので、配列をちょっとでも多く確保しようとするとすぐにハングアップしてしまい、リセットを繰り返すことになるので注意が必要です。
3-01. 前準備
2-01節で説明したように、SONY Neural Network Consoleからエクスポートした以下の学習済みの重みとバイアスの入ったヘッダファイルとCソースコードを新規Arduinoスケッチに取り込んでおきます。
MainRuntime_parameters.h
MainRuntime_parameters.c
3-02. Arduinoスケッチの入力(M5Camera CNNプログラムソースコードの作成)
前準備が終わったスケッチにM5CameraのArduinoコードを組んでいきます。
入力層はM5Cameraのイメージセンサ OV2640 の画素にしますが、フレームサイズが問題です。
1章で学習させたものは、入力層が28×28 pixelです。
OV2640の最小フレームサイズは96×96 pixelですが、MaxPoolingで圧縮する場合、112×112 pixelが丁度良く割り切れることがわかったので、OV2640のフレームサイズは160×120 pixel (QQVGA)にしておきます。
よって、入力層の前処理として、160×120 の画角の上下両端を間引いて、112×112 の画素を切り抜き、それにカーネル4×4でストライド4のMaxPooling処理をします。
すると、28×28 pixel まで圧縮できて、MNISTデータセットと同じ画角になります。
畳み込みニューラルネットワークは2章でプログラミングしたものをそのまま使います。
素人の自分なりに組んでみましたが、無駄が多く、誤りがあるかもしれませんので、動作保証はしません。
/* The MIT License (MIT)
* License URL: https://opensource.org/licenses/mit-license.php
* Copyright (c) 2020 Mgo-tec. All rights reserved.
*
* Use Arduino core for the ESP32 stable v1.0.4
*/
#include "MainRuntime_parameters.h"
#include <esp_camera.h>
#define PWDN_GPIO_NUM -1
#define RESET_GPIO_NUM 15
#define XCLK_GPIO_NUM 27
#define SIOD_GPIO_NUM 22 //M5Camera model A #25
#define SIOC_GPIO_NUM 23
#define Y9_GPIO_NUM 19
#define Y8_GPIO_NUM 36
#define Y7_GPIO_NUM 18
#define Y6_GPIO_NUM 39
#define Y5_GPIO_NUM 5
#define Y4_GPIO_NUM 34
#define Y3_GPIO_NUM 35
#define Y2_GPIO_NUM 32
#define VSYNC_GPIO_NUM 25 //M5Camera model A #22
#define HREF_GPIO_NUM 26
#define PCLK_GPIO_NUM 21
using namespace std;
class Conv {
public:
uint16_t input_vec_width;
uint16_t output_vec_width;
uint16_t output_padding;
uint16_t output_width_pad;
uint16_t kernel_width;
uint16_t kernel_size;
uint16_t output_size;
uint32_t w_addrs;
uint32_t b_addrs;
uint8_t input_node_num;
uint8_t output_node_num;
uint8_t stride;
float *weight;
float *bias;
};
class MaxPooling {
public:
uint16_t input_vec_width;
uint16_t output_vec_width;
uint16_t output_padding;
uint16_t output_width_pad;
uint16_t kernel_width;
uint16_t output_size;
uint8_t stride;
uint8_t output_node_num;
};
class Affine {
public:
uint16_t weight_size;
uint16_t output_node_num;
float *weight;
float *bias;
};
Conv fcnv, cnv2, lcnv;
MaxPooling pre_mxp, mxp1, mxp2;
Affine afn1;
constexpr uint16_t cam_flame_width = 160;
constexpr uint16_t cam_flame_height = 120;
constexpr uint16_t max_x_inbuf = cam_flame_width * 3;
constexpr uint16_t max_y_inbuf = cam_flame_height;
constexpr uint16_t cam_in_pix_width = 112;
constexpr uint16_t pre_maxpool_width = 28;
uint8_t cam_in_pix[cam_in_pix_width * cam_in_pix_width] = {};
void setup() {
Serial.begin(115200);
Serial.println();
camera_config_t config;
config.ledc_channel = LEDC_CHANNEL_0;
config.ledc_timer = LEDC_TIMER_0;
config.pin_d0 = Y2_GPIO_NUM;
config.pin_d1 = Y3_GPIO_NUM;
config.pin_d2 = Y4_GPIO_NUM;
config.pin_d3 = Y5_GPIO_NUM;
config.pin_d4 = Y6_GPIO_NUM;
config.pin_d5 = Y7_GPIO_NUM;
config.pin_d6 = Y8_GPIO_NUM;
config.pin_d7 = Y9_GPIO_NUM;
config.pin_xclk = XCLK_GPIO_NUM;
config.pin_pclk = PCLK_GPIO_NUM;
config.pin_vsync = VSYNC_GPIO_NUM;
config.pin_href = HREF_GPIO_NUM;
config.pin_sscb_sda = SIOD_GPIO_NUM;
config.pin_sscb_scl = SIOC_GPIO_NUM;
config.pin_pwdn = PWDN_GPIO_NUM;
config.pin_reset = RESET_GPIO_NUM;
config.xclk_freq_hz = 20000000;
config.pixel_format = PIXFORMAT_RGB888;
config.frame_size = FRAMESIZE_QQVGA; //160x120 pixel
config.fb_count = 1;
//esp_cameraライブラリ初期化
esp_err_t err = esp_camera_init(&config);
if (err != ESP_OK) {
Serial.printf("Camera init failed with error 0x%x", err);
return;
}
//イメージセンサ設定
sensor_t *sensor = NULL; //M5Cameraのセンサ設定用
sensor = esp_camera_sensor_get();
sensor->set_hmirror(sensor, 1); //M5Cameraのモデルによる
sensor->set_vflip(sensor, 1); //M5Cameraのモデルによる
sensor->set_exposure_ctrl(sensor, 1); //露出制御ON
sensor->set_aec2(sensor, 1); //自動露出制御ON
sensor->set_whitebal(sensor, 1); //ホワイトバランスON
sensor->set_awb_gain(sensor, 1); //自動ホワイトバランスゲインON
//事前画像処理maxpoolingパラメータ初期化
pre_mxp.input_vec_width = cam_in_pix_width;
pre_mxp.output_vec_width = pre_maxpool_width;
pre_mxp.output_padding = 0;
pre_mxp.output_width_pad = pre_mxp.output_vec_width + pre_mxp.output_padding;
pre_mxp.kernel_width = 4;
pre_mxp.stride = 4;
//初回convolutionパラメータ初期化
fcnv.input_vec_width = pre_maxpool_width;
fcnv.output_padding = 1;
fcnv.stride = 1;
fcnv.kernel_width = 4;
fcnv.output_vec_width = 25;
fcnv.output_width_pad = fcnv.output_vec_width + fcnv.output_padding;
fcnv.kernel_size = fcnv.kernel_width * fcnv.kernel_width;
fcnv.w_addrs = 0;
fcnv.b_addrs = 0;
fcnv.output_node_num = 5;
fcnv.weight = (float *)MainRuntime_parameters[0];
fcnv.bias = (float *)MainRuntime_parameters[1];
fcnv.output_size = fcnv.output_width_pad * fcnv.output_width_pad;
//初回maxpoolingパラメータ初期化
mxp1.input_vec_width = fcnv.output_width_pad;
mxp1.output_vec_width = 13;
mxp1.output_padding = 0;
mxp1.output_width_pad = mxp1.output_vec_width + mxp1.output_padding;
mxp1.kernel_width = 2;
mxp1.stride = 2;
mxp1.output_node_num = fcnv.output_node_num;
mxp1.output_size = mxp1.output_width_pad * mxp1.output_width_pad;
//2回目convolutionパラメータ初期化
cnv2.input_vec_width = mxp1.output_vec_width;
cnv2.output_vec_width = 11;
cnv2.output_padding = 1;
cnv2.stride = 1;
cnv2.output_width_pad = cnv2.output_vec_width + cnv2.output_padding;
cnv2.kernel_width = 3;
cnv2.kernel_size = cnv2.kernel_width * cnv2.kernel_width;
cnv2.w_addrs = 0;
cnv2.b_addrs = 0;
cnv2.input_node_num = 5;
cnv2.output_node_num = 3;
cnv2.weight = (float *)MainRuntime_parameters[2];
cnv2.bias = (float *)MainRuntime_parameters[3];
cnv2.output_size = cnv2.output_width_pad * cnv2.output_width_pad;
//2回目maxpoolingパラメータ初期化
mxp2.input_vec_width = cnv2.output_width_pad;
mxp2.output_vec_width = 6;
mxp2.output_padding = 0;
mxp2.output_width_pad = mxp2.output_vec_width + mxp2.output_padding;
mxp2.kernel_width = 2;
mxp2.stride = 2;
mxp2.output_node_num = cnv2.output_node_num;
mxp2.output_size = mxp2.output_width_pad * mxp2.output_width_pad;
//最終段convolutionパラメータ初期化
lcnv.output_vec_width = 3;
lcnv.input_vec_width = 6;
lcnv.output_padding = 0;
lcnv.kernel_width = 4;
lcnv.kernel_size = lcnv.kernel_width * lcnv.kernel_width;
lcnv.stride = 1;
lcnv.w_addrs = 0;
lcnv.b_addrs = 0;
lcnv.input_node_num = 3;
lcnv.output_node_num = 3;
lcnv.weight = (float *)MainRuntime_parameters[4];
lcnv.bias = (float *)MainRuntime_parameters[5];
lcnv.output_size = lcnv.output_node_num * lcnv.output_vec_width * lcnv.output_vec_width;
//affineパラメータ初期化
afn1.weight_size = lcnv.output_size;
afn1.output_node_num = 10;
afn1.weight = (float *)MainRuntime_parameters[6];
afn1.bias = (float *)MainRuntime_parameters[7];
}
void loop() {
Serial.printf("Start remaining heap size = %d\r\n", esp_get_free_heap_size());
camera_fb_t * fb = NULL;
//M5CameraのイメージセンサOV2640から画像データを取得
fb = esp_camera_fb_get();
if (!fb) {
Serial.println("Camera capture failed");
return;
}
//160 x 120 pix画像から112 x 112 pix 画像を抽出し、白黒反転する
image_preprocessing(fb, cam_in_pix);
if(fb){
esp_camera_fb_return(fb); //fb解放
fb = NULL;
}
//112x112pix画像を28x28pix画像にMaxPooling圧縮する
vector<float> pre_maxpool_vec(pre_maxpool_width * pre_maxpool_width, 0);
pre_img_maxpool(cam_in_pix, pre_mxp, pre_maxpool_vec);
//シリアルモニターに画素を表示
serial_print_pixels(pre_maxpool_vec);
//ここから畳み込みニューラルネットワーク
uint32_t cnn_time = micros(); //CNNの計算時間計測開始
//Serial.println("------------convolution1------------");
vector<vector<float>> conv1_out_vec(fcnv.output_node_num, vector<float>(fcnv.output_size, -300.0f));
first_convolution(pre_maxpool_vec, fcnv, conv1_out_vec);
//Serial.println("------------maxpooling1------------");
vector<float>().swap(pre_maxpool_vec); //vectorコンテナ解放
vector<vector<float>> maxpool1_out_vec(mxp1.output_node_num, vector<float>(mxp1.output_size, 0.0f));
maxpooling(conv1_out_vec, mxp1, maxpool1_out_vec);
//Serial.println("------------tanh1------------");
for(int i = 0; i < mxp1.output_node_num; i++){
tanh_f(maxpool1_out_vec[i]);
}
//Serial.println("------------conv2----------");
//この環境ではメモリ解放にshrink_to_fitは使えない
vector<vector<float>>().swap(conv1_out_vec); //vectorコンテナ解放
vector<vector<float>> conv2_out_vec(cnv2.output_node_num, vector<float>(cnv2.output_size, -300.0f));
convolution(maxpool1_out_vec, cnv2, conv2_out_vec);
//Serial.println("------------maxpooling2------------");
vector<vector<float>>().swap(maxpool1_out_vec); //vectorコンテナ解放
vector<vector<float>> maxpool2_out_vec(mxp2.output_node_num, vector<float>(mxp2.output_size, 0.0f));
maxpooling(conv2_out_vec, mxp2, maxpool2_out_vec);
//Serial.println("------------tanh2------------");
for(int i = 0; i < mxp2.output_node_num; i++){
tanh_f(maxpool2_out_vec[i]);
}
//Serial.println("------------conv3----------");
vector<vector<float>>().swap(conv2_out_vec); //vectorコンテナ解放
vector<float> conv3_out_vec(lcnv.output_size, -300.0f);
last_convolution(maxpool2_out_vec, lcnv, conv3_out_vec);
//Serial.println("------------tanh3------------");
tanh_f(conv3_out_vec);
//Serial.println("------------affine----------");
vector<vector<float>>().swap(maxpool2_out_vec); //vectorコンテナ解放
vector<float> affine_out_vec(afn1.output_node_num, -300.0f);
affine(conv3_out_vec, afn1, affine_out_vec);
//Serial.println("------------softmax----------");
vector<float>().swap(conv3_out_vec); //vectorコンテナ解放
vector<float> softmax_out_vec(afn1.output_node_num, 0.0f);
softmax(affine_out_vec, softmax_out_vec);
vector<float>().swap(affine_out_vec); //vectorコンテナ解放
vector<float>::iterator iter = max_element(softmax_out_vec.begin(), softmax_out_vec.end());
uint8_t index = distance(softmax_out_vec.begin(), iter);
cnn_time = micros() - cnn_time;
Serial.printf("result = %d\r\n", index);
Serial.printf("cnn_calc_time = %d us\r\n", cnn_time);
Serial.printf("Last remaining heap size = %d\r\n", esp_get_free_heap_size());
delay(1000);
}
void image_preprocessing(camera_fb_t * fb, uint8_t *output_pix){
uint16_t ary_cnt = 0;
uint8_t rgb_maxvalue = 0;
uint8_t threshold = 160; //画素の有効閾値
vector<uint8_t> rgb_vec(3, 0);
int x_margin = 24;
int y_margin = 4;
int y_elm = y_margin;
const int imax = x_margin * 3 + cam_in_pix_width * 3;
int i;
int j = cam_flame_height + y_margin - 1; //160幅pixelの内、24~135のpixelを使用
do{
for(i = x_margin * 3; i < max_x_inbuf; i += 3){
if(i >= imax) break;
rgb_vec[0] = fb->buf[y_elm * max_x_inbuf + i]; //red
rgb_vec[1] = fb->buf[y_elm * max_x_inbuf + (i+1)]; //green
rgb_vec[2] = fb->buf[y_elm * max_x_inbuf + (i+2)]; //blue
rgb_vec[0] = 0xff - rgb_vec[0];
rgb_vec[1] = 0xff - rgb_vec[1];
rgb_vec[2] = 0xff - rgb_vec[2];
//RGBの値のうち、最大値を選択
rgb_maxvalue = *max_element(rgb_vec.begin(), rgb_vec.end());
if(rgb_maxvalue > threshold){
output_pix[ary_cnt] = rgb_maxvalue;
}else{
output_pix[ary_cnt] = 0;
}
ary_cnt++;
if(ary_cnt >= cam_in_pix_width * cam_in_pix_width) return;
}
++y_elm;
--j;
}while(j >= y_margin);
}
void serial_print_pixels(vector<float> &input_pix_vec){
Serial.println("----------------------------");
int i, j;
for(j = 0; j < pre_maxpool_width; j++){
for(i = 0; i < pre_maxpool_width; i++){
//Serial.printf("%03d,",pre_maxpool_vec[ary_cnt]);
if(input_pix_vec[i + j * pre_maxpool_width] > 0){
Serial.print('#');
//Serial.printf("%7.5lf,", input_pix_vec[i + j * pre_maxpool_width]);
} else {
Serial.print(' ');
}
}
Serial.println();
}
Serial.println("----------------------------");
}
void pre_img_maxpool(uint8_t *input_pix, MaxPooling mpl, vector<float> &output_vec){
uint16_t vec_index = 0;
uint16_t max_vec_count = mpl.input_vec_width - (mpl.kernel_width - 1);
vector<float> in_kernel_vec(mpl.kernel_width * mpl.kernel_width, -500.0f);
int i, j;
for(j = 0; j < max_vec_count; j = j + mpl.stride){
for(i = 0; i < max_vec_count; i = i + mpl.stride){
pre_max_elm_output(input_pix, in_kernel_vec, mpl, i, j, output_vec[vec_index]);
vec_index++;
}
}
}
void pre_max_elm_output(uint8_t *input_pix, vector<float> &in_kernel_vec, MaxPooling &mpl, int x_elm, int y_elm, float &output){
int ix;
int iy = 0;
uint16_t k_cnt = 0;
int i, j;
j = mpl.kernel_width - 1;
do{
ix = 0;
i = mpl.kernel_width - 1;
do{
in_kernel_vec[k_cnt] = (float)input_pix[ix + x_elm + (y_elm + iy) * mpl.input_vec_width];
++ix;
--i;
}while(i >= 0);
++iy;
--j;
}while(j >= 0);
output = (*max_element(in_kernel_vec.begin(), in_kernel_vec.end())) / 255.0f;
}
void first_convolution(vector<float> &input_pix, Conv &conv, vector<vector<float>> &output_vec){
int i;
for(i = 0; i < conv.output_node_num; i++){
conv.w_addrs = i * conv.kernel_size;
conv.b_addrs = i;
first_conv_tmp(input_pix, conv, output_vec[i]);
}
}
void first_conv_tmp(vector<float> &input_pix, Conv &conv, vector<float> &output_vec){
vector<float> weight_vec(conv.kernel_size, 0.0f);
vector<float> in_kernel_vec(conv.kernel_size, 0.0f);
weight_vec.assign(conv.weight + conv.w_addrs, conv.weight + conv.w_addrs + conv.kernel_size);
uint16_t vec_index = 0;
uint16_t max_vec_count = conv.input_vec_width - (conv.kernel_width - 1);
float innr_prod = 0.0f;
int i, j;
for(j = 0; j < max_vec_count; j = j + conv.stride){
for(i = 0; i < max_vec_count; i = i + conv.stride){
fcnv_inner_prod_output(input_pix, weight_vec, in_kernel_vec, conv, i, j, innr_prod);
output_vec[vec_index] = innr_prod + conv.bias[conv.b_addrs];
vec_index++;
}
vec_index = vec_index + conv.output_padding;
}
}
void fcnv_inner_prod_output(vector<float> &input_pix, vector<float> &weight_vec, vector<float> &in_kernel_vec, Conv &conv, int x_elm, int y_elm, float &innr_p){
uint16_t vec_index = 0;
int i, j;
int ix;
int iy = 0;
j = conv.kernel_width - 1;
do{
ix = 0;
i = conv.kernel_width - 1;
do{
in_kernel_vec[vec_index++] = input_pix[ix + x_elm + ((iy + y_elm) * conv.input_vec_width)];
++ix;
--i;
}while(i >= 0);
++iy;
--j;
}while(j >= 0);
innr_p = inner_product(weight_vec.begin(), weight_vec.end(), in_kernel_vec.begin(), 0.0f);
}
void convolution(vector<vector<float>> &input_vec, Conv &conv, vector<vector<float>> &output_vec){
int i;
for(i = 0; i < conv.output_node_num; i++){
conv.w_addrs = i * (conv.kernel_size * conv.input_node_num);
conv.b_addrs = i;
conv_tmp(input_vec, conv, output_vec[i]);
}
}
void conv_tmp(vector<vector<float>> &input_vec, Conv &conv, vector<float> &output_vec){
vector<vector<float>> weight_vec(conv.input_node_num, vector<float>(conv.kernel_size, 0.0f));
vector<vector<float>> in_kernel_vec(conv.input_node_num, vector<float>(conv.kernel_size, 0.0f));
for(int i = conv.input_node_num - 1; i >= 0; --i){
weight_vec[i].assign(conv.weight + conv.w_addrs + (i * conv.kernel_size), conv.weight + conv.w_addrs + ((i + 1)* conv.kernel_size));
}
uint16_t vec_index = 0;
uint16_t max_vec_count = conv.input_vec_width - (conv.kernel_width - 1);
float tmp1 = 0.0f;
int i, j;
for(j = 0; j < max_vec_count; j = j + conv.stride){
for(i = 0; i < max_vec_count; i = i + conv.stride){
tmp1 = 0.0f;
inner_prod_output(input_vec, weight_vec, in_kernel_vec, conv, i, j, tmp1);
output_vec[vec_index++] = tmp1 + conv.bias[conv.b_addrs];
}
vec_index = vec_index + conv.output_padding;
}
}
void inner_prod_output(vector<vector<float>> &input_vec, vector<vector<float>> &weight_vec, vector<vector<float>> &in_kernel_vec, Conv &conv, int x_elm, int y_elm, float &innr_p){
vector<float>::const_iterator itr;
int cnt1;
int cnt2 = 0;
int i;
int j = conv.input_node_num - 1;
do{
cnt1 = 0;
i = conv.kernel_width - 1;
do{
itr = input_vec[cnt2].begin() + x_elm + ((cnt1 + y_elm) * conv.input_vec_width);
copy(itr, itr + conv.kernel_width, in_kernel_vec[cnt2].begin() + (cnt1 * conv.kernel_width));
++cnt1;
--i;
}while(i >= 0);
innr_p = innr_p + inner_product(weight_vec[cnt2].begin(), weight_vec[cnt2].end(), in_kernel_vec[cnt2].begin(), 0.0f);
++cnt2;
--j;
}while(j >= 0);
}
void tanh_f(vector<float> &input_vec){
for(float &x: input_vec){
x = tanhf(x);
}
}
void maxpooling(vector<vector<float>> &input_vec, MaxPooling &mpl, vector<vector<float>> &output_vec){
int i;
for(i = 0; i < mpl.output_node_num; i++){
maxpooling_tmp(input_vec[i], mpl, output_vec[i]);
}
}
void maxpooling_tmp(vector<float> &input_vec, MaxPooling &mpl, vector<float> &output_vec){
uint16_t vec_index = 0;
uint16_t max_vec_count = mpl.input_vec_width - (mpl.kernel_width - 1);
vector<float> in_kernel_vec(mpl.kernel_width * mpl.kernel_width, -400.0f);
int i, j;
for(j = 0; j < max_vec_count; j = j + mpl.stride){
for(i = 0; i < max_vec_count; i = i + mpl.stride){
if(vec_index >= output_vec.size()) return;
max_elm_output(input_vec, in_kernel_vec, mpl, i, j, output_vec[vec_index]);
vec_index++;
}
}
}
void max_elm_output(vector<float> &input_vec, vector<float> &in_kernel_vec, MaxPooling &mpl, int x_elm, int y_elm, float &output){
vector<float>::const_iterator itr;
int iy = 0;
int i = mpl.kernel_width - 1;
do{
itr = input_vec.begin() + x_elm + (y_elm + iy) * mpl.input_vec_width;
copy(itr, itr + mpl.kernel_width, in_kernel_vec.begin() + (iy * mpl.kernel_width));
++iy;
--i;
}while(i >= 0);
output = *max_element(in_kernel_vec.begin(), in_kernel_vec.end());
}
void last_convolution(vector<vector<float>> &input_vec, Conv &conv, vector<float> &output_vec){
vector<vector<float>> weight_vec(conv.input_node_num, vector<float>(conv.kernel_size, 0.0f));
vector<vector<float>> in_kernel_vec(conv.input_node_num, vector<float>(conv.kernel_size, 0.0f));
uint16_t vec_index = 0;
int i, j, k;
for(k = 0; k < conv.output_node_num; k++){
conv.w_addrs = k * (conv.kernel_size * conv.input_node_num);
conv.b_addrs = k;
float tmp1 = 0.0f;
for(i = conv.input_node_num - 1; i >= 0; --i){
weight_vec[i].assign(conv.weight + conv.w_addrs + (i * conv.kernel_size), conv.weight + conv.w_addrs + ((i + 1)* conv.kernel_size));
}
for(j = 0; j < conv.output_vec_width; j = j + conv.stride){
for(i = 0; i < conv.output_vec_width; i = i + conv.stride){
inner_prod_output(input_vec, weight_vec, in_kernel_vec, conv, i, j, tmp1);
output_vec[vec_index++] = tmp1 + conv.bias[conv.b_addrs];
tmp1 = 0.0f;
}
}
}
}
void affine(vector<float> &input_vec, Affine &affine, vector<float> &output_vec){
vector<float> weight_vec(affine.weight_size, 0.0f);
int i = affine.output_node_num - 1;
do{
weight_vec.assign(affine.weight + (affine.weight_size * i), affine.weight + (affine.weight_size * i) + affine.weight_size);
output_vec[i] = inner_product(weight_vec.begin(), weight_vec.end(), input_vec.begin(), 0.0f) + affine.bias[i];
--i;
}while(i >= 0);
}
void softmax(vector<float> &input_vec, vector<float> &output_vec){
float sum_exp = 0.0f;
float tmp[input_vec.size()];
int i = input_vec.size() - 1;
do{
tmp[i] = expf(input_vec[i]);
sum_exp += tmp[i];
--i;
}while(i >= 0);
i = input_vec.size() - 1;
do{
if(sum_exp == 0.0f){
Serial.println("Error! sum_exp.");
}
output_vec[i] = tmp[i] / sum_exp;
--i;
}while(i >= 0);
}
【ザクッと解説】
●8行目:
2-05節のソースコードと同様に、重みとバイアスパラメータのヘッダファイルをインクルードしておきます。
●9行目:
Arduino core for the ESP32 に同梱のesp_cameraライブラリをインクルードします。
●11-27行:
イメージセンサ OV2640 に接続してある、ESP32のピンアサインです。
過去に何回かM5Cameraを取り扱っているので参照してみてください。
M5Camera の映像をArduino IDE シリアルモニターに表示させてみる
esp32-cameraライブラリを読み解く ~モジュール接続、動作チェック編~
なお、M5Cameraはモデルの違いによって、ピンアサインが異なるようです。
スイッチサイエンスの以下の記事を参照してみてください。
https://www.switch-science.com/catalog/5207/
●85–107行:
esp32_cameraライブラリのconfig設定初期化です。
pixel_format はRGB888とします。そうした方がプログラミングしやすいです。
frame_sizeはQQVGAとします。160×120 pixelです。
●110行:
ここで、esp32_cameraライブラリを初期化しています。
ここである程度スタックメモリやヒープメモリを消費してしまいます。
●117-124行:
ここでイメージセンサOV2640の設定初期化を行います。
119と120行はM5Cameraのモデルによって必要です。
最近購入したものはこの設定が必要かと思います。
古いモデルはこの119行と120行をコメントアウトしてください。
これは画像の水平反転と垂直反転です。
露出設定やホワイトバランス設定も行います。
この設定について詳しくは以下の記事を参照してください。
https://www.mgo-tec.com/blog-entry-esp32-ov2640-ssd1331-test1.html/3#title07
●127-132行:
ここで112×112 pixel画像を28×28 pixelに圧縮するMaxPooling処理のパラメータ初期化です。
カーネルを4×4として、ストライド4としています。
●135-204行:
2-05節と同じく、畳み込みニューラルネットワークのパラメータ初期化です。
●211行:
ここで、イメージセンサOV2640からDMAで送られてくる画像を取得してバッファに保存します。
●217行:
ここで、QQVGAの160×120 pixelの画像を112×112 pixelに切り取り、白黒反転させる処理をしています。
●226行:
ここで、112×112 pixelの画像を28×28 pixel にMaxPooling処理して圧縮しておきます。
●232-283行:
ここは2-05節の畳み込みニューラルネットワークと同じです。
1秒毎に出力しています。
●293-330行:
イメージセンサOV2640から取得した160×120 pixel の画像を、左右24pixel、上下4pixel間引いて切り抜き、白黒反転させて、thresholdで画素の明るさ0~255の範囲のうち160以下は全てゼロにするという処理にしています。
3-03. コンパイル書き込み実行および出力結果
では、M5CameraをパソコンにUSB接続して、Arduino IDE を起動し、前節のスケッチを開きます。
ツールメニューのボード設定は、2-06節と同じでOKです。
では、シリアルモニターを115200bpsで起動し、コンパイル書き込み実行させます。
そして、紙にマジックで数字を手書きし、M5Cameraで撮影すると、以下の感じで1秒毎に表示されます。
(図03-03-01)
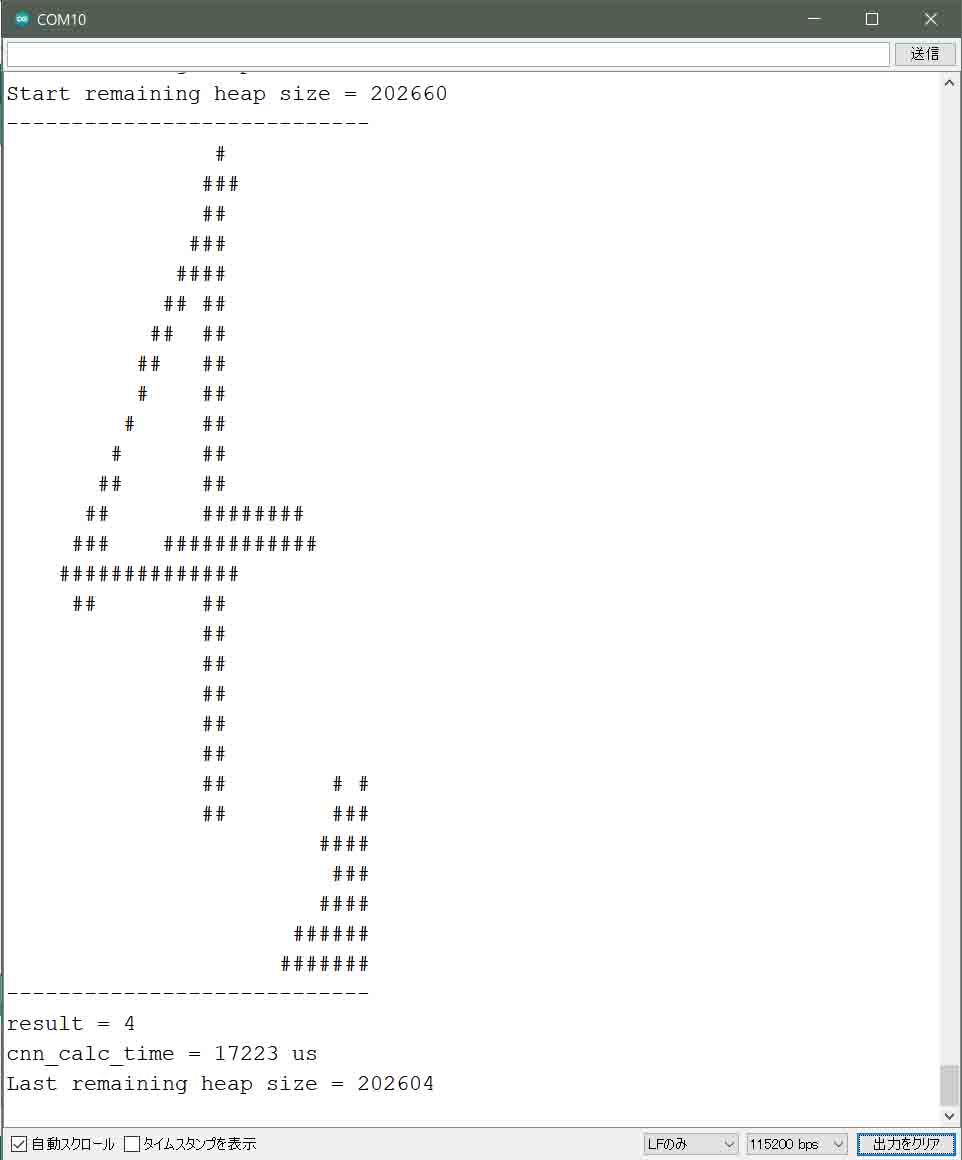
ここで注意していただきたいのは、最初の動画のところでも説明したように、影が出てしまうと正常に判定できないので、手書き文字に照明を当てるなどして、影を極力減らしてください。
そして、数字を破線の間のできるだけ中央に大き目に表示させることです。
最初はコツがつかみにくいですが、しばらく撮影しているとコツがつかめてくると思います。
正答率が上がった位置がおそらく最適な投影位置だと思います。
また、最初の動画にあるように、太いマジックで数字を書いた方が認識率は上がります。
細い文字は認識率が悪いです。
ということは、認識率を上げるためには画像の前処理が結構大事だということが分かりますね。
本来、ディープラーニングというものは、うまく認識しなかった画像を保存してストックしておき、それをまた学習データに反映させて、再学習させて、その重みとバイアスでCNNを作るのですが、それについては次回以降の課題とします。
ちなみに、2-06節でも述べましたが、ここでもcnn_calc_timeの値は変わらず、約17msです。
なかなか良い出来です。
ループ処理の最適化が効いていて、自分のプログラミングがほんの少し上達した感じがして嬉しいですね。
実は、ここには表示させていませんが、イメージセンサ画像取得後の前処理から時間計測すると、88ms くらいかかっています。
とすると、前処理の方をもっと改善するべきでしたね。
今後の課題です。
また、イメージセンサの画像取得からのトータル時間は、約160msかかっています。
フレームレートで言うと、約6fpsくらいです。
これで、液晶ディスプレイに表示させながら画像認識となると、フレームレートを上げるのはなかなか難しいですね。
今後の課題は山積です。
そんなこんなで、どんなもんでしょうか?
ここまでパッと手書き数字の画像認識ができると、
「ディープラーニングってこんなもんかぁ~」
と拍子抜けするのと同時に、
「やっと夢の画像認識が出来たぜ!」
という喜びも湧いてきて、ちょっと複雑な心境です。
いずれにしても、賛否両論あると思いますが、これは紛れもなく
AI、ディープラーニングによる画像認識達成!
と、自己満足しておきたいと思います!
やったぜ!!!
まとめ
ついに、ディープラーニングで夢のカメラ画像認識の第一歩を踏み出すことが出来て、個人的には大満足です。
畳み込みニューラルネットワークのプログラミングで一番懸念したのは計算時間でしたが、ループ処理を見直すことによって、かなり時間を切り詰めることが出来たのは収穫でした。
また、画像を認識し易くするために照明で影を無くすとか、画像のノイズを減らすなどの前処理が大事だということもよくわかりました。
あるいは、ノイズも含めたディープラーニングが必要なのかもしれませんね。
あとはこの画像認識をリアルタイムで液晶ディスプレイに表示させることが今後の課題です。
その為にはメモリ容量が大問題になってくるので、なかなか難しいと思います。
そうなると、PSRAMを使うとか考えなければならないし、そろそろESP32では限界かもしれません。
また、今回は手書き数字MNISTデータセットの学習データを使いましたが、本来のディープラーニングは実際の画像でディープラーニングをすることです。
これは今後、実験していこうと思います。
以上です。
ではまた。。。
Amazon.co.jp 当ブログのおすすめ
コメント
すごいです!!!(小並感)
これからも頑張ってください!!
わーい!
ありがとうございま~す!!!
(^^)
すばらしい! 試行錯誤の様子が伝わってきます。
引き続きこの活動を応援しております~
mizunaさん
記事をご覧いただき、そして、とても嬉しいコメントありがとうございまーーす!!!
最近はいろいろ多忙で記事更新できておりませんが、引き続きいろいろ試していきたいと思いま~す。
(^^)