今回はGoogle Driveに作ったフォルダに画像ファイルを放り込んで、Google Colaboratoryで独自の学習用および評価用のデータセットを作成してみたいと思います。
これができれば、MNISTなどの既存のデータセットに頼らず、自分独自の画像を使ってディープラーニングすることができるようになります。
PythonやKerasにはとっても便利なモジュールやライブラリがあって、特にload_img関数は、異なる種類やサイズの画像でも、全て同じサイズに整形(リサイズ)してくれて、比較的簡単にデータセットを作ることが出来て、スゲーなと思いました。
ということで、データセットの作り方を紹介したいと思います。
因みに何度も言っておりますが、私はPythonプログラミングやディープラーニングについては独学の素人です。
誤りがあるかも知れませんので、お気づきの点がありましたらコメント投稿でご連絡いただけると助かります。
- Google Driveに自作データセット用フォルダを作成し、画像ファイルを保存しておく
- 画像ファイルを読み込んで配列に変換
- Google Driveの画像データフォルダから学習用と評価用データセットを作成
- まとめ
【目次】
事前準備
以下の記事を参照して、Google Colaboratoryの設定を事前に済ませておきます。
そして、以下の記事を参照して、事前にファイル保存用のためにGoogle Driveをマウントしておきます。
学習済みモデルをHDF5形式でGoogle Driveに保存する
1.Google Driveに自作データセット用フォルダを作成し、画像ファイルを保存しておく
ではまず、自分でデータセットを作るにあたって、Google Driveにフォルダを作成し、データセット用に整理して画像を入れ込む作業をします。
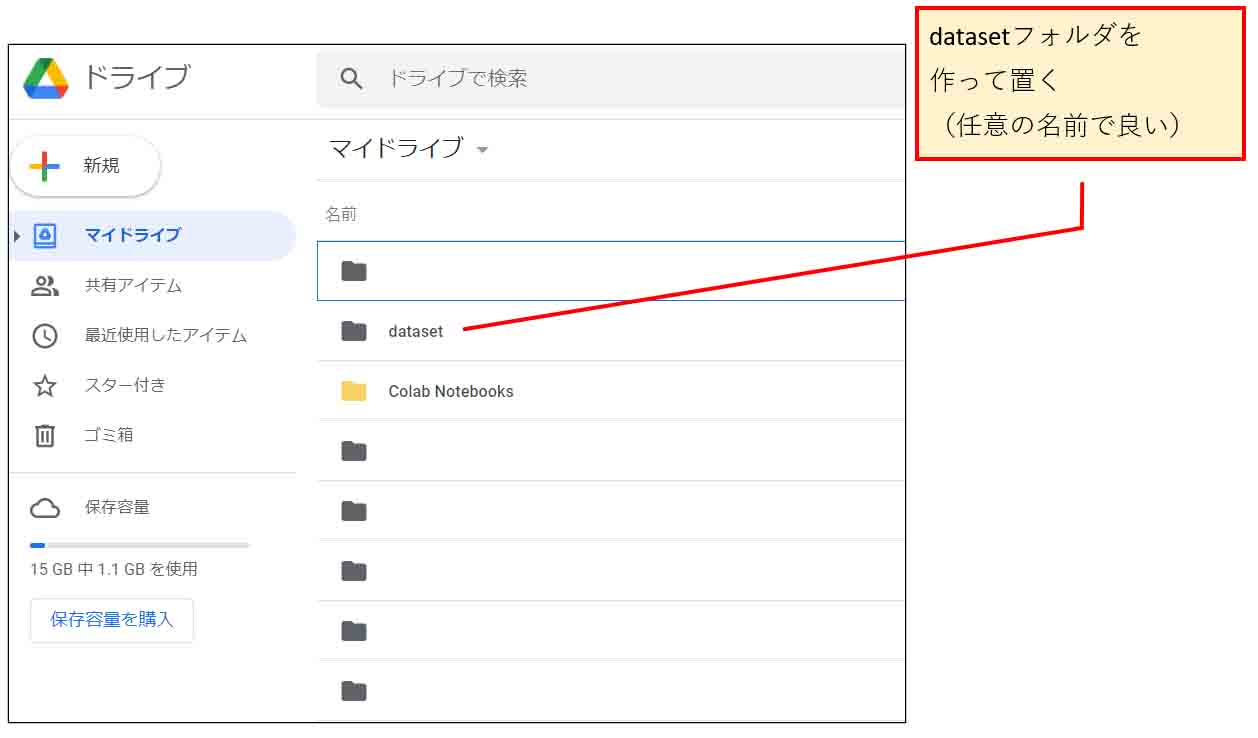
Google Driveを開きます。
そこにデータセット用の新規フォルダを作成しておきます。
ここでは、「dataset」というフォルダ名にしておきます。
(図01_01)
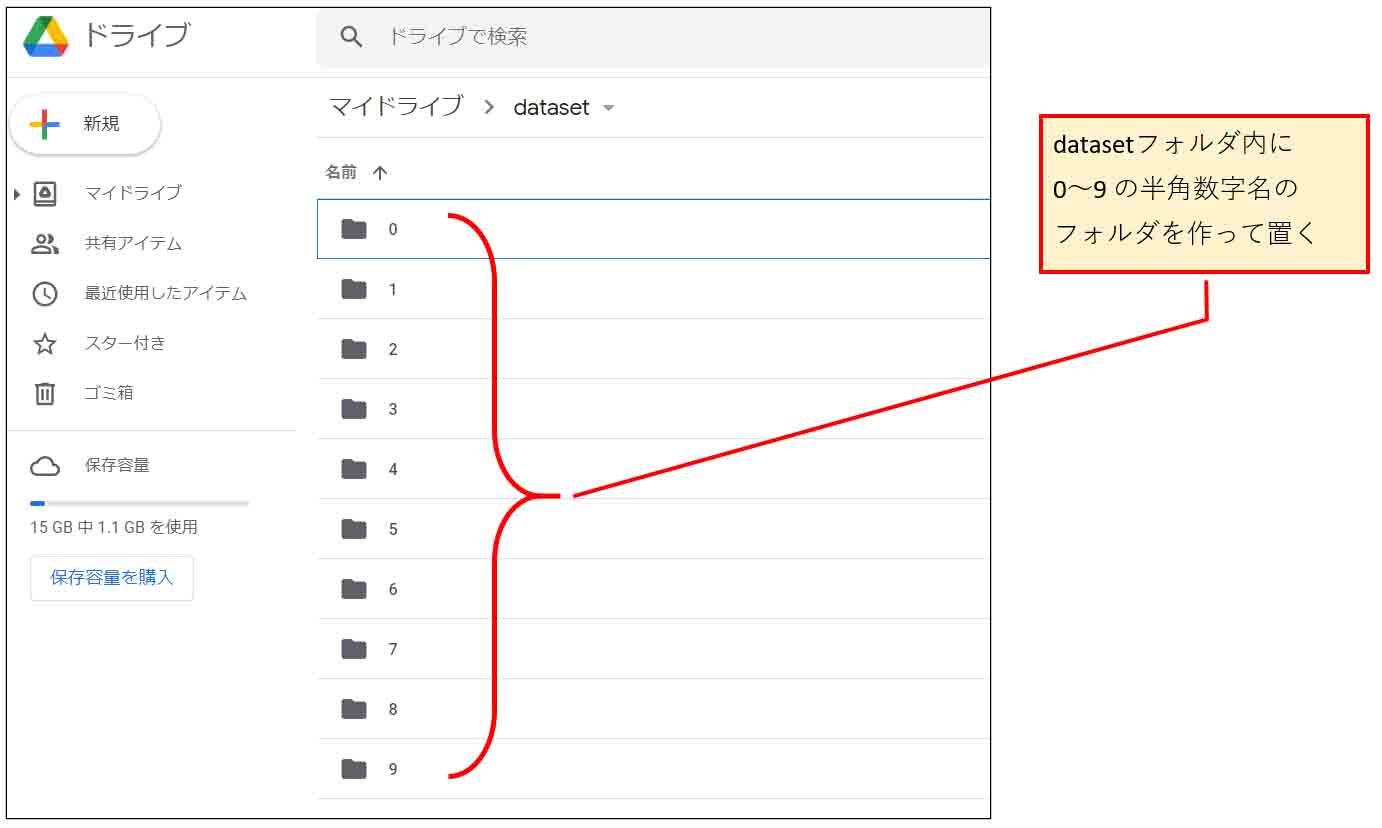
次に、そのフォルダの中に新たにフォルダを作成し、フォルダ名はそれぞれ正解ラベル名としておきます。
つまり、下図のように、手書き数字のデータセットならば、フォルダ名はそれぞれ0~9の半角数字とします。
(図01_02)
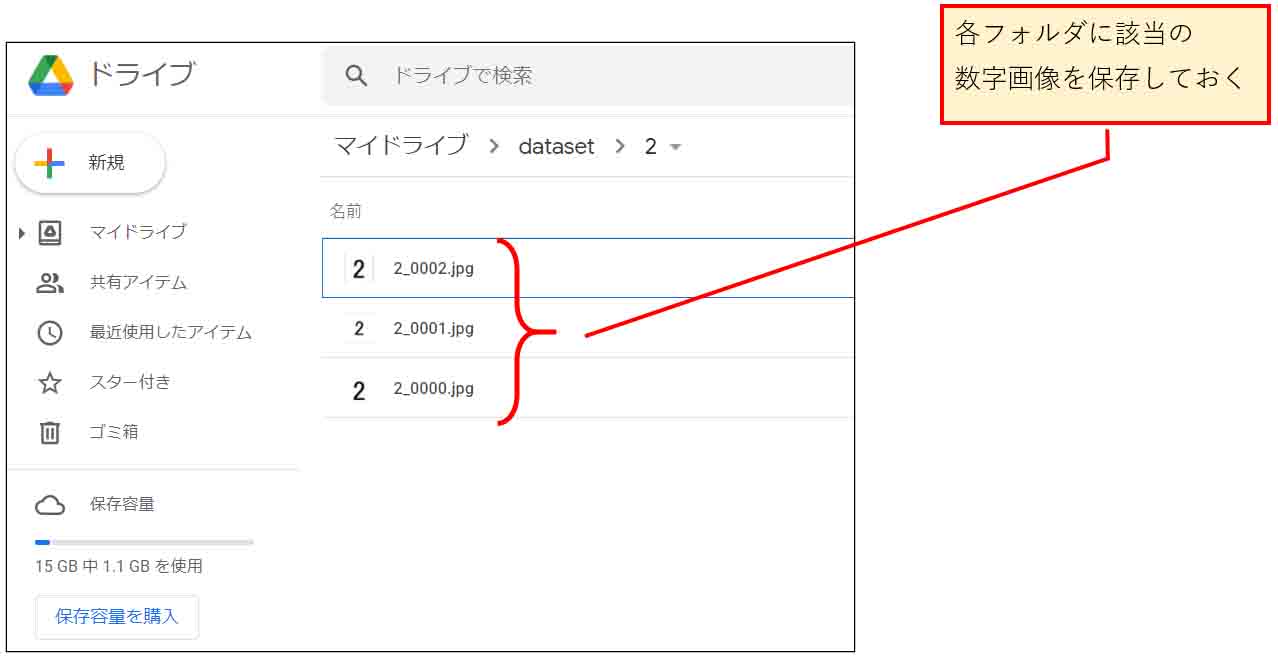
次に、そのそれぞれのフォルダ名に該当する画像を保存しておきます。
例えば、お試しとして、エクセルとかワード等で大き目のフォントのテキスト図形を作成し、そこに数字を入力して、スクリーンショットで画像を切り取ってJPEG形式で保存しても良いでしょう。
または、Webで表示された適当な数字の画像を切り取って保存しても良いでしょう。
画像サイズは適当で良いですが、28×28 pixel以上のできるだけ小さめが良いと思います。
そして、正解ラベルが2の画像、つまり、2の数字画像ファイルならば、下図のようにフォルダ名2のところに入れ込んでおきます。
ファイル名は自分自身が判別し易い名前で良いと思います。
ここでは、
2_0000.jpg
2_0001.jpg
などとネーミングしてみました。
(図01_03)
以上のようにして、全ての数字についてそれぞれ独自で作った画像データをそれぞれのフォルダに保存しておけば、データセット用の画像フォルダの出来上がりです。
2.画像ファイルを読み込んで配列に変換
では、前章で設定しておいた、Google Driveのフォルダから画像を読み込んで、学習可能な配列に変換していきます。
2-01. globでフォルダの中のファイル名を取得
まず、それぞれのフォルダの中にあるファイル名を自動で取得しなければなりません。
それにはGoogle ColaboratoryのPythonに備えられているglobモジュールを使えばOKです。
例えば、detaset/9/にあるファイル名を取得するコードは以下の感じです。
(※必ず事前にGoogle Driveをマウントしておいてください)
# ファイルの入出力用にglobをインポート import glob file_path = '/content/drive/MyDrive/dataset/9' files = glob.glob(file_path + '/*') print(files) print(files[0]) print(files[1])
【実行結果】
['/content/drive/MyDrive/dataset/9/9_0001.png', '/content/drive/MyDrive/dataset/9/9_0000.jpg'] /content/drive/MyDrive/dataset/9/9_0001.png /content/drive/MyDrive/dataset/9/9_0000.jpg
このように、glob.glob関数は、ワイルドカードを使うと、そのフォルダの中にあるファイル名全てを取得して、文字列のリスト型配列にして返って来ます。
文字配列なので、files[0]はそのゼロ番目のファイル名、files[1]はその次の1番目のファイル名として取り出せます。
2-02. load_img関数は自動で画像を整形して読み込んでくれて、とっても便利
では、次に、Google Driveに保存してある画像ファイルを読み込んで、配列に変換する方法を紹介します。
例として、1章で作ったGoogle Drive内の2というラベルのデータセットフォルダに以下の画像を保存してみます。
パスは、
/content/drive/MyDrive/dataset/2/
となります。
画像は以下の3種類のJPEG画像を保存しておきます。
画像サイズは全て異なります。
(file名:2_0000.jpg)

(file名:2_0001.jpg)

(file名:2_0002.jpg)

では、この画角の異なる3種類の画像を一気に読み込んで、plot表示させてみます。
以下の感じになります。
(※必ず事前にGoogle Driveをマウントしておいてください)
keras.preprocessing.image のような keras.preprocessing API はTensorflow 2.9.1 で非推奨になったみたいです。代わりに
keras.utils を使ってください。以下のコードも修正しました。
(2023/06/13時点)
# 画像ファイルを読み込み、
import keras
import glob #ファイルの入出力に必要
import numpy as np #numpyモジュール
# 画像をファイルから読み込み、配列に変換するために必要
from keras.utils import load_img, img_to_array
# 画像データを実行画面に描画するために必要
from matplotlib import pyplot
# ※予めGoogleドライブをマウントして、そこにフォルダを作成し、画像を保存しておく
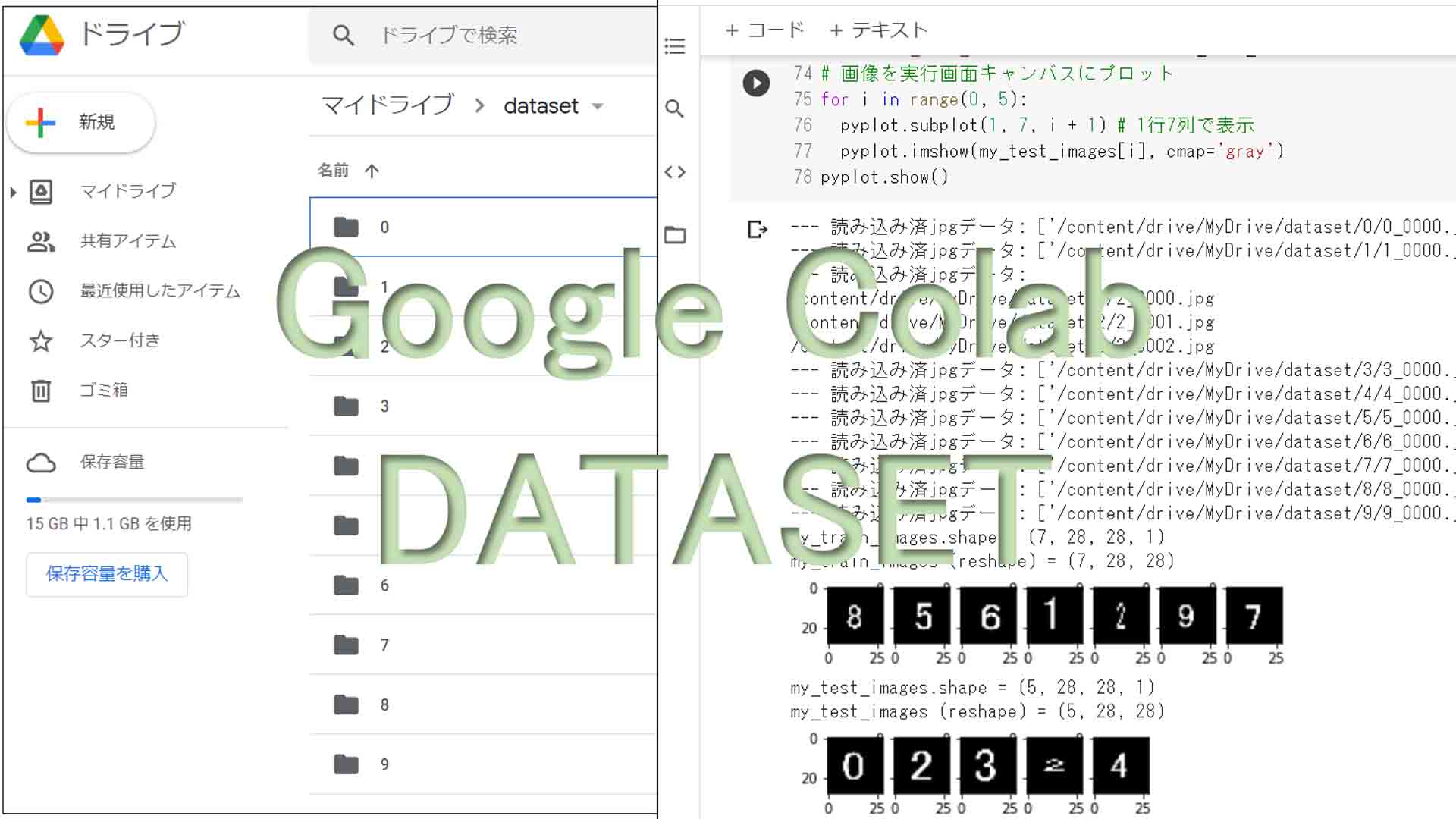
file_path = '/content/drive/MyDrive/dataset/2/*.jpg'
# globでファイル名を配列で取得
file_path_array = glob.glob(file_path)
#リスト型配列の要素を改行して表示
print('file_path_array:', *file_path_array, sep='\n')
print()
images_list = []
for i in range(0, 3):
# 画像ファイルを読み込み、自動的に28×28 pixに変換してPIL形式で出力
img = load_img(file_path_array[i], color_mode = 'grayscale', target_size=(28, 28))
print('読み込んだファイル:', file_path_array[i])
# PIL形式からリスト型配列に変換
img_list = img_to_array(img)
# images_listに読み込んだ画像list配列を追加
images_list.append(img_list)
# リスト型からNumPy配列に変換
images_np = np.array(images_list)
print('shape =', images_np.shape)
# (3, 28, 28, 1)を(3, 28, 28)にreshape(配列の要素数変換)
images_np = images_np.reshape(3, 28, 28)
# 画像を実行画面キャンバスにプロット
for i in range(0, 3):
pyplot.subplot(1, 3, i + 1) # 1行3列で表示
pyplot.imshow(images_np[i], cmap='gray')
pyplot.show()
【実行結果】
(図2_02_01)

どうでしょうか。
これ、面白いですよね。
縦長の画像も横長の画像でも、全て等サイズの28×28 pixelに整形してくれましたね。
ここでのポイントは、load_img関数です。
つまり、デジカメやイメージセンサで適当なサイズで取った写真や画像をデータセットフォルダに適当に放り込んでおくだけで、データセット用配列に変換OKというわけです。
それに、PNG形式画像でもJPEG画像でもOKなんです。
とっても便利なライブラリですね。
これは、ディープラーニング用ツールに最適です。
因みに、RGBカラー画像の場合は、
color_mode = ‘rgb’
とすれば良いのですが、これはいずれ試してみたいと思います。
ところで、load_img関数で返ってきたデータはPIL(Python Image Library)形式というものでちょっと特殊なデータ形式です。
それを、img_to_arrayでリスト型配列に変換し、それを更にNumPy配列に変換しています。
そして、変換後のshape(要素数)は(3, 28, 28, 1)なので、次元を一つ減らして、(3, 28, 28)とすると、plot表示しやすくなります。
ここまでできれば、独自データセットは出来たも同然です。
3.Google Driveの画像データフォルダから学習用と評価用データセットを作成
では、画像データフォルダの前準備が済んで、PythonやKerasのインポート関数の動作が理解出来たら、いよいよディープラーニングの学習用および評価用データセットを作成してみます。
以下のサイトをかなり参考にさせて頂きました。
そのサイトのコードを当方でアレンジすると、以下の感じになりました。
my_train_labels = keras.utils.to_categorical(my_train_labels, label_class_number)
しかし、最近、APIが変更になったようで、
AttributeError: module 'keras.utils' has no attribute 'to_categorical'というエラーになりました。よって、以下のように変更しました。
my_train_labels = keras.utils.np_utils.to_categorical(my_train_labels, label_class_number)(2022/09/18)
keras.preprocessing.image のような keras.preprocessing API はTensorflow 2.9.1 で非推奨になったみたいです。代わりに
keras.utils を使ってください。以下のコードも修正しました。
(2023/06/13時点)
#こちらのサイトを参照(子供プログラマー)child-programmer.com/ai/cnn-originaldataset-samplecode/
import keras
import glob #ファイルの入出力に必要
import numpy as np #numpyモジュール
# 画像をファイルから読み込み、配列に変換するために必要
from keras.utils import load_img, img_to_array
# 画像データを訓練用と評価用に分割するために便利なモジュール
from sklearn.model_selection import train_test_split
# 画像データを実行画面に描画するために必要
from matplotlib import pyplot
# ※予めGoogleドライブをマウントして、そこにデータセットフォルダを作成し、
# そこに画像を保存しておく
my_train_data_path = '/content/drive/MyDrive/dataset'
folder = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']
label_class_number = len(folder)
my_train_images = [] # 学習用画像データ
my_train_labels = [] # 学習用ラベルデータ
my_test_images = [] # 評価用画像データ
my_test_labels = [] # 評価用ラベルデータ
# 画像ファイルを順番に読み込み、リスト型配列に変換する
for index, folder_name in enumerate(folder):
read_data = my_train_data_path + '/' + folder_name
# フォルダ毎のファイルパスを配列で取得
jpg_files = glob.glob(read_data + '/*.jpg')
if len(jpg_files) > 1:
# フォルダ内ファイルが複数ある場合、表示を改行
print('--- 読み込み済jpgデータ:', *jpg_files, sep='\n')
else:
print('--- 読み込み済jpgデータ:', jpg_files)
for i, jpg_file in enumerate(jpg_files):
# 画像ファイルを読み込み、自動的に28×28 pixに変換してPIL形式で出力
img = load_img(jpg_file, color_mode = 'grayscale' ,target_size=(28, 28))
# PIL形式から配列に変換
img_array = img_to_array(img)
my_train_images.append(img_array)
my_train_labels.append(index)
# リスト型からNumPy配列に変換
my_train_images = np.array(my_train_images)
my_train_labels = np.array(my_train_labels)
# 白黒反転
my_train_images = 255 - my_train_images
# 画像データ値を0.0~1.0の値に正規化
my_train_images = my_train_images.astype('float32') / 255.0
# ラベルデータをone-hotベクトルに変換
my_train_labels = keras.utils.np_utils.to_categorical(my_train_labels, label_class_number)
#データセットのうち6割(=0.6)を学習データ(train)にし、4割を評価用データ(test)にする
my_train_images, my_test_images, my_train_labels, my_test_labels = train_test_split(my_train_images, my_train_labels, train_size=0.6)
# 学習用データの次元を確認
print('my_train_images.shape =', my_train_images.shape)
#(7,28,28,1)の学習用ラベルデータshapeを(7,28,28)に次元をカットする
my_train_images = my_train_images.reshape(my_train_images.shape[0], 28, 28)
print('my_train_images (reshape) =', my_train_images.shape)
# 画像を実行画面キャンバスにプロット
for i in range(0, 7):
pyplot.subplot(1, 7, i + 1) # 1行7列で表示
pyplot.imshow(my_train_images[i], cmap='gray')
pyplot.show()
# 評価用データの次元確認
print('my_test_images.shape =', my_test_images.shape)
#(5,28,28,1)の評価用ラベルデータshapeを(5,28,28)に次元をカットする
my_test_images = my_test_images.reshape(my_test_images.shape[0], 28, 28)
print('my_test_images (reshape) =', my_test_images.shape)
# 画像を実行画面キャンバスにプロット
for i in range(0, 5):
pyplot.subplot(1, 7, i + 1) # 1行7列で表示
pyplot.imshow(my_test_images[i], cmap='gray')
pyplot.show()
【実行結果】
(図3_01)

ここでのポイントは、datasetフォルダを0~1までforループで順次検索して、indexにフォルダ名を代入し、それを正解ラベルデータとして順番に配列に取り込んでいるところです。
フォルダ名が半角の数字というところがミソですね。
このフォルダを増やせば、分類をいくらでも増やせるということになると思います。
for文と一体で使われるenumerate関数というのもインデックスを取得するのには便利な関数ですね。
データセットの正規化やラベルデータのone-hotベクトル変換については以前のこちらの記事で紹介したとおりです。
あと、もう一つのポイントは train_test_split です。
引数で、train_size=0.6 とすると、データセットの60%を学習用データセットに変換して、残り40%を評価(テスト)用データセットに自動振り分けしてくれるんです。しかもランダムにです。
ここでは、全12件の画像データの内、60%の7件が学習用(my_train_images)データに振り分けられ、残り5件が評価用(my_test_images)データに振り分けられました。
このように、いちいち手作業でデータを分けなくても、多量に画像データを放り込んでおけば良いのは有難いですね。
ただ、正解ラベルデータへの画像の振り分けは手作業で行わなければいけないのは仕方ありませんが、、、。
たったこれだけのコードを入力するだけで、様々なサイズの画像を整形して、データセットを自動的に振り分けてNumPy配列に変換してくれるのは良いですね。
Pythonがディープラーニングに使われる理由がよくわかりました。
これで、独自のデータセットを組むことが出来たので、MNISTデータセットでは足りない部分を自分で補ってディープラーニングを進めて行けそうです。
4.まとめ
以上で、Google Dirive作ったフォルダに画像ファイルを放り込めば独自のデータセットができるようになりました。
これで、MNISTだけでうまく評価されなかった画像を独自に取り込んで再学習させることができそうです。
それにしても、load_img関数や、train_test_split関数は便利ですね。
こういうのを知ってしまうと、Google Colaboratoryから離れられなくなりそうな気がします。
ということで、今回はここまでです。
ではまた・・・。
Amazon.co.jp 当ブログのおすすめ
コメント
my_train_imageの中身が空だというエラーが出るのですが、解決策はありますでしょうか。
主様の書いてあるコード通りに入力はしています。
もちさん
記事をご覧いただき、ありがとうございます。
ごめんなさい。
今は多忙で時間が無く、検証できない状態です。
しばらくお待ちくださ~い。
m(_ _)m
もちさん
検証遅くなり、ごめんなさいです。
当方で確認した結果、53行目で以下のようなエラーがありました。
AttributeError: module 'keras.utils' has no attribute 'to_categorical'2021年3月時点では正常に動いていたのですが、APIが変更になってしまったようです。
よって、53行目を以下に変更しました。
my_train_labels = keras.utils.np_utils.to_categorical(my_train_labels, label_class_number)本記事のソースコードも変更しておきました。
これで試してみて下さい。
本記事のおかげでデータセットを作成することができました。ありがとうございます。
作成したデータセットをGoogle colab上でyoloを利用して学習させる方法はございますでしょうか
matsudaさん
記事をご覧いただき、ありがとうございます。
データセット作成できてよかったです。
ただ、私は現在諸事情で忙しく、しばらくGoogle Colabを使っておりません。
yoloというものも初めて知った次第で、今は全く知識がありません。
他のサイトを参照された方が早いと思います。
そんなわけで、お役に立てず、申し訳ございません。
二重でコメントしてしまっていたら申し訳ございません、先程コメント入力中に少し端末から離れてしまい、コメントできたか分からなかったのでこちらで質問させていただきたいです。
本記事で作成したデータセットをGooglecolab上で学習、物体検出する方法を教えて頂けますと幸いです。
2重コメント投稿だったのですね。
物体検出に関しても、このサイトで行った実験以上のことは何もやっておりません。
お役に立てず、申し訳ございません。
m(_ _)m
お忙しい中ご返信ありがとうございます。
学校の卒業研究で初めて機械学習に触れ全くの無知だったので、助かりました。
投稿者様の他の記事はまだ見たことがなかったので、参考にさせていただきます。
お役に立てなのなら嬉しい限りです~。
(^^)
本記事を参考にさせていただき、機械学習について学んでいた際、エラーがでてしまい、自身で解決することができないためコメントさせていただきます。
データの分割を行う際に以下のエラーがでました。
With n_samples=0, test_size=None and train_size=0.6, the resulting train set will be empty. Adjust any of the aforementioned parameters.
記事通りにコードを記述しているのですが、画像の読み込みが正しく行われておらず、私自身もドライブへのマウントとパスの確認は行ったのですがうまくいかないため、お忙しいと思いますがご返答お待ちしております。
るいさん
記事をご覧いただき、ありがとうございます。
しばらくGoogle Colabを使っておらず、今はすっかり忘れてしまいましたが、久々に使ってみたらエラーが出ていました。
keras.preprocessing.imageというところで、というエラーメッセージでした。
ネットでいろいろ調べると、どうやら keras.preprocessing API は Tensorflow 2.9.1 で非推奨になったみたいです。
Tensorflow や keras はよくAPIが変更になるようで、また数年後には変わっているかも知れませんね。
KerasのAPIについては、公式の以下のサイトで関数が存在しているか検索することができるので、そこも参照してみてください。
https://keras.io/api/
ということで、この記事内のコードの
keras.preprocessing.image部分をkeras.utilsに変更しました。それで私の場合はエラーが無くなり、正常に動作しました。
これで試してみて下さい。