
こんばんは。
今回は、懲りずに、C言語のポインタの、Arduino IDE ( ESP8266 ボード ) 上の動作を、私が個人的に疑問に思ったことを再考してみます。
ポインタが分かっている方々やプログラマーの方々にとっては当たり前のことかも知れませんので、読み飛ばしてください。
前回の記事で 、C言語のポインタについて誤った事や誤解を生む文言を載せてしまいました。(現在は削除済)
私はプログラミングや電子工作は独学で、C言語やコンパイラの構造などの基礎をスッ飛ばして Arduino プログラミングを始めたので、分かったようでいて、正確には分かってなかったのです。
Twitter やコメント等で、いろいろな方々からご指摘いただきました。
改めて調べ直すと、おかげでポインタの考えが、ガラッと変わってしまいました。
もし、指摘されなかったら、延々と勘違いのままプログラミングしていたかも知れません。
皆さま、貴重なお時間を割いてコメントいただき、ホントに感謝いたします。
ありがとうございました。
m(_ _)m
私の本意として、誤ったことは載せたくないのですが、なにぶん趣味独学の個人ブログですので、知らずに掲載してしまう可能性があります。
もし、お気づきの点がありましたら、是非コメント等をいただければ、可能な限り早急に修正していきたいと思っています。
ただ、正確性を求めるあまり、記事がアップできなくなるようなことは避けたいので、
「こうやれば動いたよ!」
的な事は、気軽にガンガンとアップしていきたいと思いますので、何卒ご容赦ください。
- Arduino IDE ポインタ使用で私が悩んだこと
- Arduino 言語 はC言語と異なるか?
- Arduino IDE スケッチ上のポインタの動的メモリ割り当て、および malloc 関数使用について
- ESP-WROOM-02 ( ESP8266 ) のSRAM メモリ容量再確認
- ポインタ初期化
- ダブルクォーテーション囲い文字列の書き換え
- ヌル文字(終端)’\0’ の挿入について
- まとめ
Arduino IDE ポインタ使用で私が悩んだこと
Arduino IDE は、プログラミングの正確な知識が無くても気軽に始められて、様々なジャンルの方々が組み込み開発に足を踏み入れる切っ掛けになった、とてもよく考えられたツールだと思います。
ソースコードを「スケッチ」というくらいですから、アーティストが気軽に絵を描くようにプログラミングできるよう作られているみたいです。
初めてこれを使い始めた時はこのコンセプトに感動しました。
「なんて簡単なんだ・・・」と・・・。
半面、どんどん使い込んでいって、本当に自分のやりたいことを実現しようとすると、多次元配列やポインタを使わざるを得なくなり、いろいろなエラーに直面します。
私も、過去に作ったライブラリでポインタを多用しています。
やはり、多々エラーに直面して、WEB検索しまくりましたが、結局理由が分からず、別の方法に置き換えたりしていました。
再び、別のプログラムで多量の文字列を扱うことになった時に同じエラーに直面し、
「何とかならんものか・・・」
とWEB検索しまくりました。
結果、Arduino IDE 上でのポインタ動作情報はあまり無く、標準C言語の情報がほとんどです。
そうなると、挙句の果てには、
「Arduino IDE のC言語は、一般のC言語仕様と異なるのでは?」
という疑問になってしまいます。
(実際には異なっていませんでした。次の項目参照)
私のような Arduino や ESP-WROOM-02 ( ESP8266 ) を使って気軽にサッと電子工作やIoTを実現したいと思っている方々は、まず完成させることに時間を割きたいので、C言語やコンパイラの知識を詳細に勉強する時間がもったいないのです。
Arduino IDE はそういう人の為のツールですから・・・。
そんなわけで、そこの知識をスッ飛ばしてしまうので、ポインタを使う複雑なプログラムになるとつまずきます。
こういうアマチュア電子工作家の方はとても多いと個人的に思っています。
そもそも、これを記事にする切っ掛けとなったのは、WEB記事から自動で文字列を抽出するプログラミングをする時に、SRAMメモリを節約したいというところから始まりました。
WEB記事をHTTP でGET すると、HOSTから送られてくる文字列が膨大になります。
いくら Arduino UNO の 20倍以上もある ESP-WROOM-02 ( ESP8266 ) でも、所詮、電子工作用途レベルのメモリしかないので、すぐにオーバーロードしていまいます。
そうすると、グローバル変数領域の配列宣言で最大文字数を想定してメモリを確保すると、すぐに限界になってしまうので、ポインタを使って動的にメモリを割り当てた方が良いだろうと思ってしまいます。
この、「動的にメモリを確保」というところが、Arduino IDE でプログラミングする場合に大きな壁なんです。
特に、IDE上で自作のローカル関数を作成して、その中でポインタに動的に文字列を代入し、そのポインタを他のローカル関数へ渡すときが難しいです。
malloc を使えば確保できそうな気がしましたが、それでも予めサイズを決めてしまわねばなりません。
でも、このmalloc 関数ですが、Arduino IDE のサンプルプログラムでは殆ど使われていません。
WEB で検索しても、滅多に Arduino IDE 上で使っている例を見かけません。
標準のC言語では普通に使う例が沢山あるのですが・・・。
それには実は理由があったんです。
これについては後述します。
というわけで、基礎知識を勉強しないまま、分かったつもりでいて、いろいろな方法を試してみてしまって、何かスッキリしないなぁという症状に陥っていたわけです。
Arduino 言語 はC言語と異なるか?
既に削除していますが、前回の記事で掲載した件です。
皆さんにとってはあまりに下らないことかも知れませんが、私が個人的に真剣に疑問に思った問題です。
これは、前回の記事のコメント投稿の匿名さんや、Twitter のまりすさんから教えていただきました。
答えは、いつも私がとてもお世話になっているArduino 日本語リファレンス のページの一番左上に書かれていました。
Arduino言語はC/C++をベースにしており、C言語のすべての構造と、いくつかのC++の機能をサポートしています。また、AVR Libcにリンクされていて、その関数を利用できます。
ほぼ毎日のようにこのサイトを参考にしていますが、ここの文章は全くスルーしていました。
これは、Arduino.cc FAQや arduino – BuildProcess.wiki も参照してみましたが、間違いないようです。
あまりに私が無知だったので、これを機会に、コンパイラやC言語の構造を少しずつでも勉強していこうと思っています。
これで、疑いなくArduino IDE の疑問点は C/C++ 言語として調べられます。
取るに足らない疑問だったかも知れませんが、匿名さん、まりすさん、ご指摘感謝いたします。
ありがとうございました。
m(_ _)m
Arduino IDE スケッチ上のポインタの動的メモリ割り当て、および malloc 関数使用について
私はもともとArduino IDE でしか開発をしたことがないので、メモリに関してヒープ領域だとかスタック領域だとかについて、お恥ずかしながら知りませんでした。
そんなことを知らなくても開発できるのが Arduino IDE の良さです。
ただ、先に述べたように、私がやりたかったことは、自作のローカル関数内で動的にポインタのメモリ領域を確保し、ローカル関数間でそのポインタの受け渡しをやりたかったのです。
しかし、その方法についてネットで調べても、C言語のmalloc 関数を使う例ばかりでした。
でも、なぜか、Arduino スケッチ例については malloc関数を使ったものをほとんど見かけませんでした。
なぜ???
これは実は、Twitter で、しなぷすさんから以下のような、とても有難いアドバイスを頂きました。
メモリの多いマイコンならいいのですが、ATmega328PみたいにRAMが2kBしかないマイコンでは、ヒープを使うとRAMの使用効率の悪さが目立つので嫌われます。
実際に使用するRAM以外に、空いている領域の管理にRAMを使用しますから。
・・・(略)・・・
固定サイズなら、フラグメント(断片化)の問題もありませんし。~Twitter しなぷすさん~
なーーるほど!!!
Arduinoスケッチ上でmalloc 関数をほとんど見かけない理由がやっとわかりました。
と、いうことは 当然、Arduino上でポインタの動的メモリ割り当てをやっている人をほとんど見かけないわけです。
ガッテン! 納得しました。
しなぷすさん、ありがとうございました。
m(_ _)m
ということで、メモリの少ないマイコンで、ローカル関数間の多量の文字列データ渡しは、固定長の配列を宣言して、ローカル関数間で渡した方が良いというわけです。
つまり、それでもメモリが足りなくなって、もっと大きな文字列を扱いたければ、前回の記事のように外付けSRAM を使えば良いということで一件落着です。
もちろん、例外もありますが、少なくとも私がやりたかったことについては、そういうことで落ち着きました。この結論に達するのに、長い長い道のりでした・・・。
フゥ~・・・。
ESP-WROOM-02 ( ESP8266 ) のSRAM メモリ容量再確認
改めて、ESPRESSIF社のESP-WROOM-02 ( ESP8266 ) データシートを見てみると、ステーションモードでWi-Fiルータに接続されている状態で、ユーザーのSRAM使用領域は、ヒープ、データ領域合わせて約50KB だそうです。
つまり、Arduino UNO の約25倍あるようです。
実はローカル関数内では更にその半分程度しかメモリを確保できないことが判明しました。 以下の記事を参照してください。(2017/1/23) Arduino / ESP8266 の使用できるRAM 領域を再考
ESP-WROOM-02 は、ESPRESSIF社製で、ESP8266を日本の電波法をクリアして技適認証取得した、2.4GHz帯 Wi-Fi マイコンボードです。
Arduino IDE で開発できます。
こんなにも長くESP8266ボードを使っている私ですが、コンパイル書き込みの構造はよくわかりません。
いつか、解明しようと思っていますが、ちょっと暇がありません。
それよりも、自分の作りたいプログラムを完成させることが先です。
ESP-WROOM-02 は単体ではとても使い辛いので、私はスイッチサイエンス製のESPr Developer を薦めています。
これは、ESP-WROOM-02 に USBシリアル変換、電源レギュレーター、ロジックレベル変換などをパッケージ化したもので、Arduino IDE との親和性バッチリです。
ESPr Developer の使い方については以下の記事を参照してください。
ESPr Developer ( ESP-WROOM-02 開発ボード )の使い方をザッと紹介
ポインタ初期化
ここからは、ポインタについてビギナーに立ち返って改めて再考してみます。
前回の記事でいろいろな方々から指摘されて調べ直したら、何と、今まで私がマスターしていたつもりのポインタの概念が覆されてしまいました。
改めて、C言語やC++言語の文法の複雑さをしみじみと感じました。
素人が簡単にC言語で組み込み開発ができない理由がよくわかりました。
では、私が勘違いしていたことを説明してみます。
(再度言わせていただきますが、私はアマチュアなので間違えているかもしれません。
もし、誤っていたらコメントください。)
まず、前回の記事のように、文字列やデータをSRAM に記憶させる場合には、メモリの先頭アドレスを決めて、データの長さ(バイト数)を決めてから、実際のデータを書き込んでいくというプロセスが必要ということは分かりました。
外付けSRAMと同じように、C言語の配列やポインタも同じプロセスで、ほとんど同じ動作だろうと思っていました。
以下はchar型のポインタを宣言して、文字列を代入して初期化し、シリアルモニターに表示するスケッチ例です。
【ソースコード】 (※無保証 ※PCの場合、ダブルクリックすればコード全体を選択できます)
void setup() {
delay(1000);
Serial.begin(115200);
while (!Serial) {
; // wait for serial port to connect. Needed for native USB port only
}
Serial.println();
char* c1 = "abcdefg";
char c2[] = "ABCDEFG";
Serial.println( c1 );
Serial.println( c2 );
}
void loop() {
}
シリアルモニターではこう表示されます。
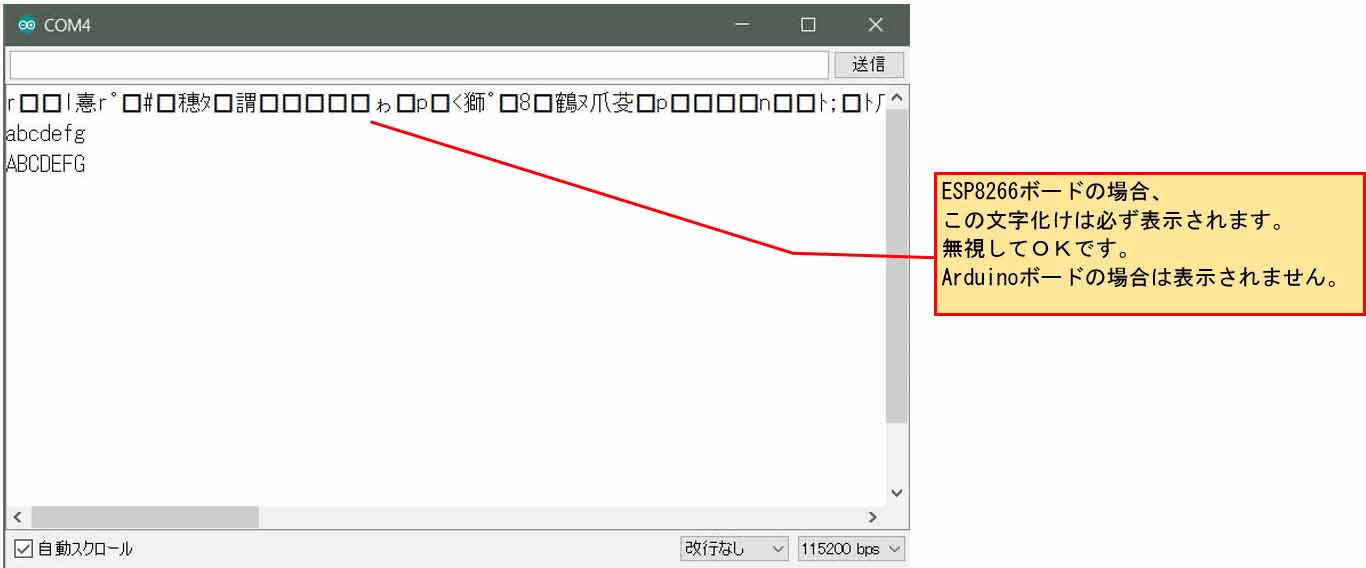
これはESP8266 ボード設定を使用し、シリアルモニターは115200bps 設定にしています。
最初の行の文字化けはESP8266特有のもので、起動時に76800bpsでメッセージが送られてくるそうです。その後、115200bps通信に自動で切り替わるので、起動時メッセージを見たければ、その時に74880bps にすれば読み取れるようになります。
ですからESP-WROOM-02 ( ESP8266 ) についてはこの文字化けは無視してOKです。
文字化け以外はArduino UNO ボードでも大体は同じように表示されると思います。
(後半では異なる表示になる場合を説明してます)
これは、配列はポインタと同じように扱えて、初期化も同じなので、このスケッチは簡単に理解したつもりでした。
初期化の段階で、Arduino IDE コンパイラが文字列格納の先頭アドレスと、文字列終端の’\0’を自動で処理してくれているということも分かりました。
これなら、配列だろうがポインタだろうが、変数としてはどちらでも同じだろうと思い込んでいました。
実は配列とポインタの初期化は、見た目は同じでも、似て非なる物だったのです。
しかも、「初期化」というものには私のようなアマチュアが勘違いする要素が満載だったんです。
その理由はまず、以下のポインタ初期化を見てください。
【ソースコード】 (※無保証 ※PCの場合、ダブルクリックすればコード全体を選択できます)
void setup() {
delay(1000);
Serial.begin(115200);
while (!Serial) {
; // wait for serial port to connect. Needed for native USB port only
}
Serial.println();
char* c1;
c1 = "abcdefg";
Serial.println( c1 );
}
void loop() {
}
これは、正常にコンパイル終了してシリアルモニターに正常に表示されます。
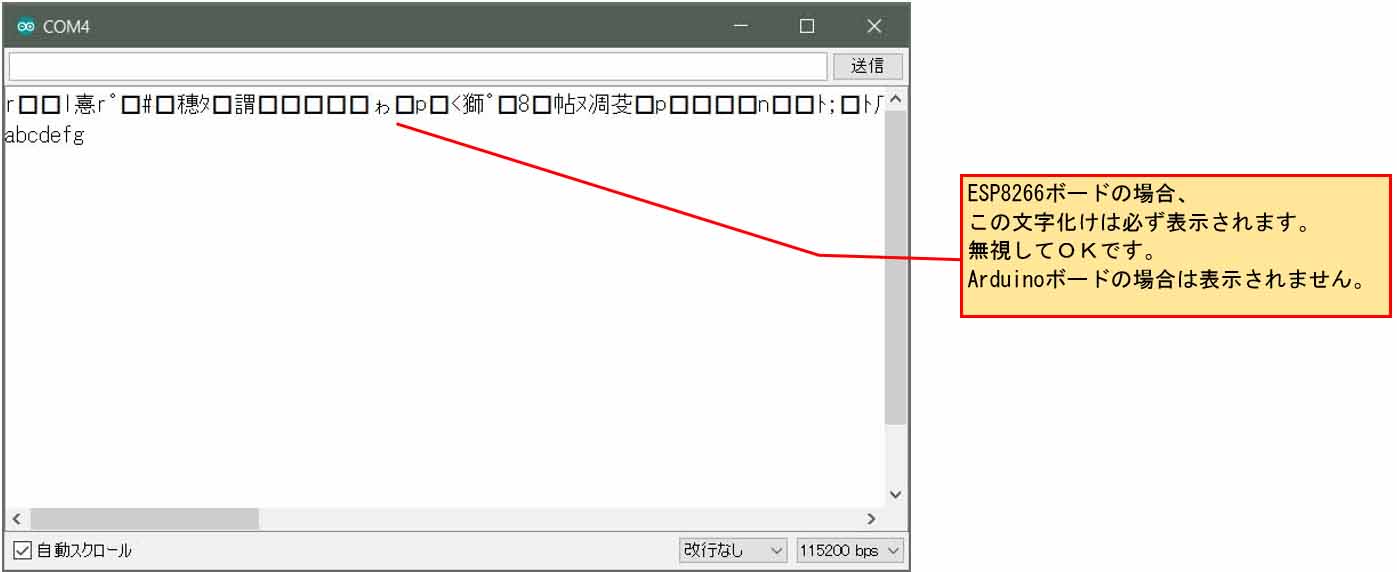
でもこれ、おかしいと思いませんか?
ポインタでは、c1 はその文字列の先頭アドレスを示すのに、アドレスに文字列を代入したらエラーになるのでは??
つまり、アドレスを示すところに、実際のデータ値を代入しているようなもんです。
実は、ついこの間知ったばかりなのですが、ダブルクォーテーションで囲った文字列は文字列リテラルというものだそうです。
ネット検索で何度か目にした語句ですが、アマチュアの私にとっては小難しい説明ばかりだったし、大した説明ではないだろうと思って、ほとんど無視していました。
でも、そこが落とし穴だったんです。
実は、ダブルクォーテーションで囲んだ文字列は、コンパイラが文字列をメモリ上の書き換え不可の特別な記憶領域に定数として格納し、そのポインタの先頭アドレスを返しているらしいのです。
なんとビックリ!!
書き換え不可??
なんだとぉーーー?
ということは、文字列のポインタアドレスを ポインタ c1 に代入しているだけなので、上のスケッチは何の問題もないわけです。
なるほど・・・。
ならば、以下のスケッチはどうでしょうか?
【ソースコード】 (※無保証 ※PCの場合、ダブルクリックすればコード全体を選択できます)
void setup() {
delay(1000);
Serial.begin(115200);
while (!Serial) {
; // wait for serial port to connect. Needed for native USB port only
}
Serial.println();
char c2[8];
c2 = "abcdefg"; //これはエラーになる
Serial.println( c2 );
}
void loop() {
}
このスケッチはコンパイルエラーとなります。
10行目で invalid array assignment となり、「無効な配列の割り当て」だそうです。
この方法は今までやったことありません。
この記事を書いている最中に、
「これできるのかな?」
と思ってやってみました。
先にも言いましたが、私は配列とポインタは等しいと思い込んでいて、配列名の c2 はポインタの先頭アドレスを示すと思い込んでいました。
ですから、上で述べたように、文字列リテラルというものであれば、その文字列の先頭アドレスを返すので、それを配列名の c2 に代入しても問題ないだろうと思っていました。
でも、実は違ったのです!
ポインタの場合、先頭アドレスは変数で自由に書き換えができますが、配列名の示す先頭アドレスは書き換えができないそうです。
つまり、c2 は格納された先頭のデータのアドレスを返すだけで、書き込みはできないのです。
私は今日まで配列とポインタは全く同じと思い込んでいましたが、実は異なるものだったのです。
ならば、なぜ、
char c2[8] = “abcdefg”;
はOKなのでしょうか?
これは、ここでは詳細な説明は割愛しますが、初期化することと、型宣言の後の単なる代入とでは、コンパイラは全く異なった処理をしているそうです。
配列の初期化の場合は一文字ずつ読み書き可能なメモリ領域へ格納して、最後に ’\0’ を付加します。
それを踏まえて、以下のスケッチをご覧ください。
【ソースコード】 (※無保証 ※PCの場合、ダブルクリックすればコード全体を選択できます)
void setup() {
delay(1000);
Serial.begin(115200);
while (!Serial) {
; // wait for serial port to connect. Needed for native USB port only
}
Serial.println();
char* c1;
char c2[8] = "ABCDEFG";
c1 = c2;
Serial.println( c1 );
}
void loop() {
}
シリアルモニターでは正常に表示されます。
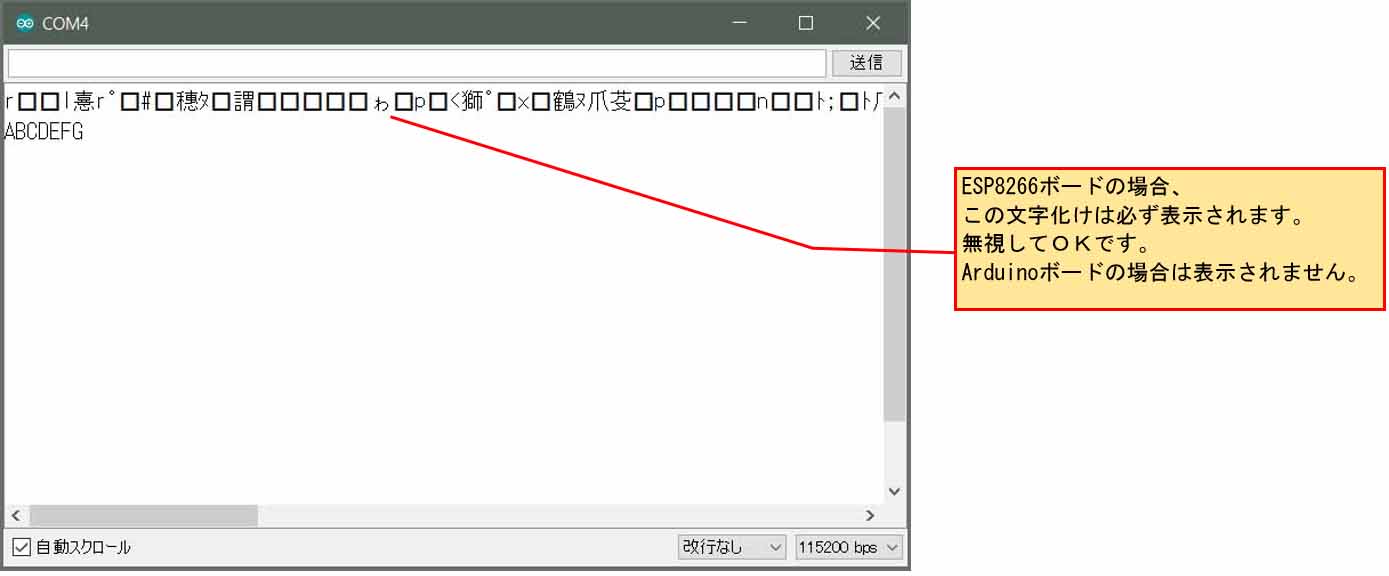
12行目のポインタ先頭アドレス c1 は変数で、代入可能です。
これならばOKですが、この逆はできません。
C言語のプログラマーならば当たり前のことかも知れませんが、私のようなArduino IDE しか動かしたことのないアマチュアにはとっても意外な事実でした。
これは絶対忘れないようにしたいですね。
●初期化と、型宣言後の代入は、プロセスが異なる。
●ダブルクォーテーション囲み文字列(文字列リテラル)は基本的に書き換えできない領域に記憶され、そのポインタ先頭アドレスを返す。
●配列名は先頭要素アドレスを返すだけで、ポインタのようにアドレス書き換えはできない。
以上から、私は初期化というものは、今までただ単に型宣言したついでに値を代入しているだけだと思い込んでいました。
しかし、ここにはC言語ポインタのとても重要な法則が詰まっていたということを改めて知った次第です。
ここを疎かにすると、後でポインタのエラーに悩まされることになると思います。
ダブルクォーテーション囲い文字列の書き換え
では、上記をしっかり頭に入れて、ダブルクォーテーションで囲った文字列でchar型ポインタを初期化した場合、文字列の書き換えはどうなるでしょうか?
以下のスケッチをArduino IDEでコンパイル書き込みしてみてください。
【ソースコード】 (※無保証 ※PCの場合、ダブルクリックすればコード全体を選択できます)
void setup() {
delay(1000);
Serial.begin(115200);
while (!Serial) {
; // wait for serial port to connect. Needed for native USB port only
}
Serial.println();
char* c1 = "abcdef";
c1[0] = 'H';
c1[1] = 'e';
c1[2] = 'l';
c1[3] = 'l';
c1[4] = 'o';
c1[5] = '!';
Serial.println( c1 );
}
void loop() {
}
シリアルモニターの結果は正常終了しているように見えます。
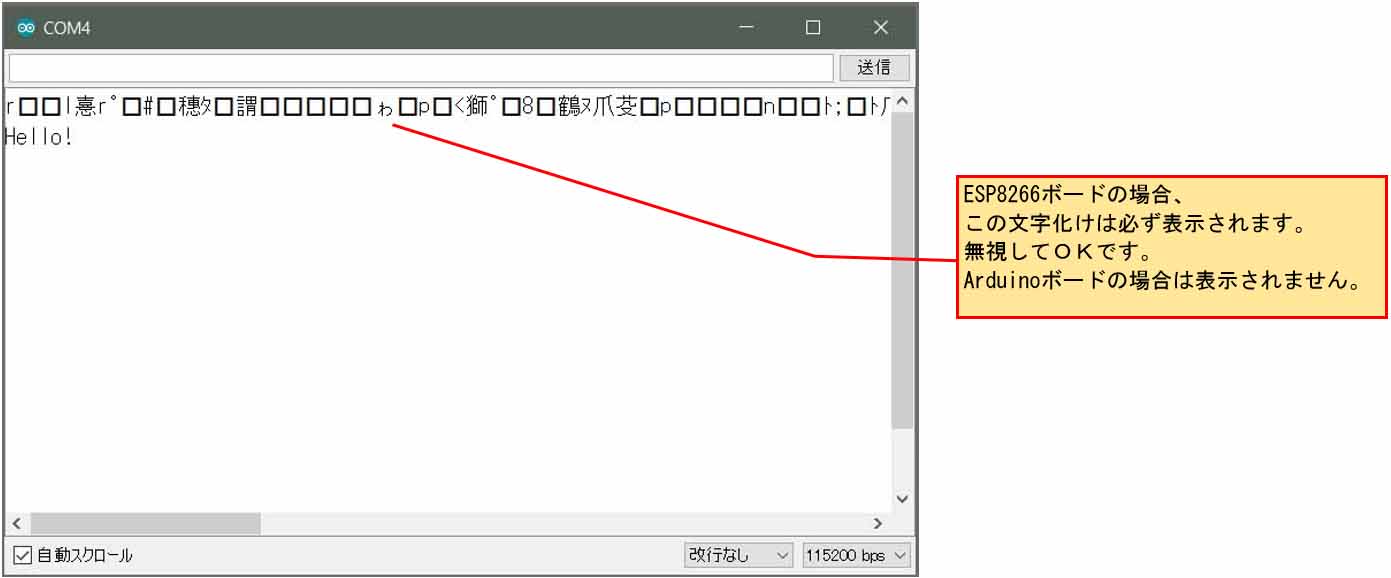
実は、これは基本的にやってはいけないことだそうです。
私が勘違いしていたのは、正にこれです。
ポインタは配列と同じとして扱えて、コンパイルエラーもなく、シリアルモニターに問題なく表示されているので、何の疑問も持ちませんでした。
ネットで検索すると、「これはやってはダメ」という記事が多かったのに、Arduino IDE では可能となれば、そりゃ、
「Arduino IDE はC言語とは異なるのかな?」
と疑問に持ってしまうわけですよ。
しかし、先にも述べたように、ダブルクォーテーションで囲った文字列は、文字列リテラルと言って、C言語ではメモリ内の、書き換え禁止の特別な領域に格納されるということらしいので、その文字列は const char と同じということです。
ですから、ポインタ c1 はその領域の先頭アドレスを示しているだけなので、これはエラーになるはずです。
しかし、なぜコンパイルが通ってしまったのでしょうか?
実は Twiiter で北二十四条低音組合さんから教えていただいたんですが、下図のように、コンパイラの警告を全て表示させると、これに対する警告メッセージを見ることができたんです。
Arduino UNO でも ESP8266ボード でも同じメッセージが出ていました。
warning: deprecated conversion from string constant to 'char*' [-Wwrite-strings]
要するに、
書き換え不可の const char 領域から、書き換え可能な char型ポインタ領域への非推奨変換
ということです。
非推奨ということは禁止ではないので、コンパイルが通ってしまうということです。
ネットでいろいろと調べていると、昔はこのような書き込みは可能だったらしく、現在は昔のコードと整合性を取るために一部のコンパイラで残された仕様らしいです。
コンパイラによっては、あるオプションを加えるとこういう書き込みが可能らしいです。
現在のC言語規格では、本来はエラーになるべきだそうです。
確かに、const 領域を自由に書き換えられたら、それはおかしいですよね。
因みに、もし書き換えた場合は不定、つまり、どうなるか分かりませんということで、予期しないエラーになる可能性があるということです。
ということは、ダブルクォーテーションで囲った文字列で初期化したポインタは書き換えない方が良い。
そして、プログラムする人が勘違いしないように const を付けた方が良い。
ということになるのではないかと思います。
Arduino IDE で可能だからと言って、それをやってしまうと、いつかすっかり忘れてしまって、正しいポインタの知識を習得できなくなってしまう気がします。
それを踏まえて、C言語として最も正しい初期化と書き換えは以下のようなスケッチになるのではないでしょうか。
【ソースコード】 (※無保証 ※PCの場合、ダブルクリックすればコード全体を選択できます)
void setup() {
delay(1000);
Serial.begin(115200);
while (!Serial) {
; // wait for serial port to connect. Needed for native USB port only
}
Serial.println();
const char* c1 = "abcdef"; //文字列書き換え不可
char c2[] = "ABCDEF"; //文字列の書き換え可
c2[0] = 'H';
c2[1] = 'e';
c2[2] = 'l';
c2[3] = 'l';
c2[4] = 'o';
c2[5] = '!';
Serial.println( c1 );
Serial.println( c2 );
}
void loop() {
}
ESP8266 ボードでWi-Fi通信プログラムを組む時、SSID や パスワードの文字列ポインタで、const がついているのは、ただ単に書き換え不可にしているだけではなかったということが、良く分かりました。
ダブルクォーテーション囲み文字列(リテラル)は配列で初期化すると、書き換え可能な領域に格納されます。
ここもしっかり押さえておきたいところですね。
しかし、この単純そうに見えるスケッチですが、さまざまな規格の上に成り立っているとは、なかなか奥が深いと思った次第です。
ヌル文字(終端)’\0’ の挿入について
では、Arduino IDE ビギナーが陥りやすい文字列の表示について再考してみます。
先の項目で、char型の配列や文字列の初期化ではコンパイラが自動的にヌル文字終端、つまり、’\0’ が文字列の最後に挿入されると述べました。
( ※ ’\0 ‘ はフォントによって’¥0’ と表示されます)
‘\0’ の ASCII文字コードのバイナリ値は 0x00 です。
ASCIIコードで、実際にシリアルモニターで表記できる文字は 0x20 から始まります。
それより小さい数値は、文字ではない、制御用のコードが割り当てられています。
Serial.print で文字列を出力すると、‘\0’ までの文字列をシリアルモニターに表示します。
よって、
char* c1 = “abcdefg”;
とすれば、’g’ の後に ‘\0’ があるので、そこまでズラーッと表示してくれます。
先ほど、初期化と代入では異なると言いましたが、以下のスケッチではどうでしょうか。
【ソースコード】 (※無保証 ※PCの場合、ダブルクリックすればコード全体を選択できます)
void setup() {
delay(1000);
Serial.begin(115200);
while (!Serial) {
; // wait for serial port to connect. Needed for native USB port only
}
Serial.println();
char* c1;
c1 = "abcdefg";
Serial.println( c1 );
}
void loop() {
}
シリアルモニターの結果は先ほどと同じ結果で、こうなりますね。
‘g’ の後が文字化けせず、正常に表示されています。
でも、これが疑問なのは、初期化せずにポインタ宣言後に代入しているのに、正常に表示できているということです。
これはつまり、ダブルクォーテーションで囲った文字列定数は、ポインタの初期化ではなく、宣言の後の代入でも既に ‘\0’ が最後に追加されているということが分かります。
そういうわけで、ダブルクォーテーションで囲った文字列、つまり文字列リテラルというものは、私のようなアマチュアが考えているよりもかなり特殊だということです。
しっかりこのことは頭に入れて、忘れないようにしておきたいですね。
では、配列の場合を見てみます。
以下のスケッチをコンパイルしてみてください。
【ソースコード】 (※無保証 ※PCの場合、ダブルクリックすればコード全体を選択できます)
void setup() {
delay(1000);
Serial.begin(115200);
while (!Serial) {
; // wait for serial port to connect. Needed for native USB port only
}
Serial.println();
char c2[7] = "ABCDEFG";
Serial.println( c2 );
}
void loop() {
}
ESP8266 ボードでコンパイルしたらこんな感じでエラーが出ました。
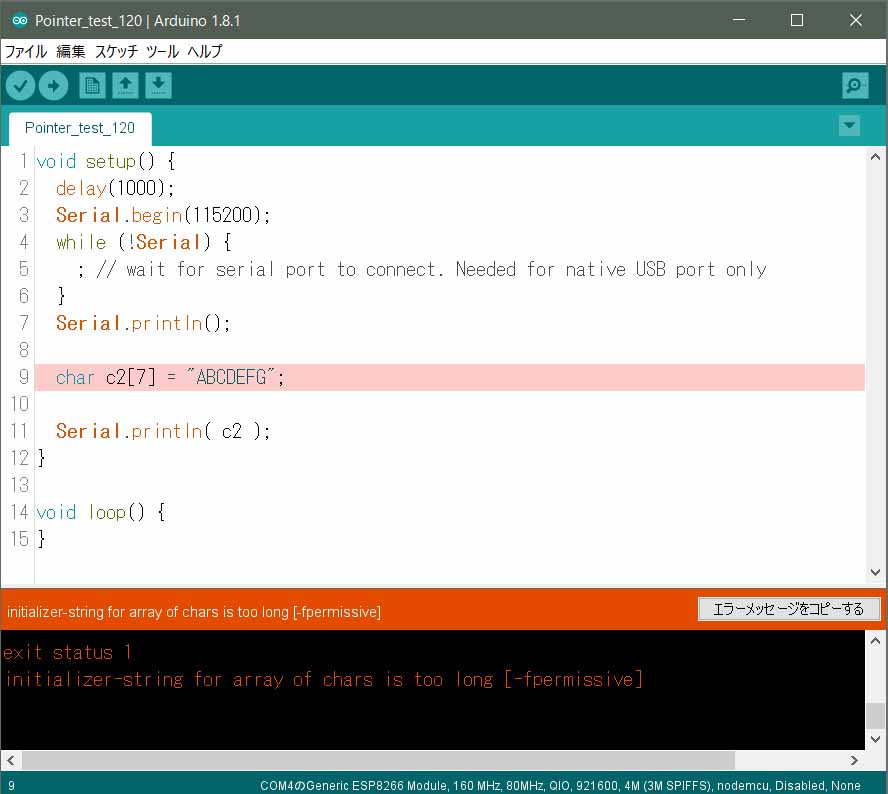
それは当然ですよね。
ダブルクォーテーションで囲った文字列は自動的にヌル終端文字が追加された文字数になるので、宣言した文字数を超えているわけです。
つまり、配列を初期化する場合は、必ず(実際の文字数+1文字)を意識して記述しなければならないわけです。
そうすれば、Serial.print で ‘\0’ まで文字を表示させて、その後は文字化けしないわけです。
これは、しばらく文字列を扱わないプログラミングをしていたり、しばらくコーディングをしなかったりすると忘れてしまうんですよね。
プログラマーみたいに常に仕事で使っていれば別ですが・・・。
あと、よくあるのが、便利なStringクラスを使っていると、この規則を忘れてしまうことが多々あります。
肝に銘じで気を付けていきたいところです。
ところで・・・!!
念のため、Arduino UNO でコンパイルしてみたら、不思議なことが起こりました。
Arduino IDE 1.8.1 の場合です。
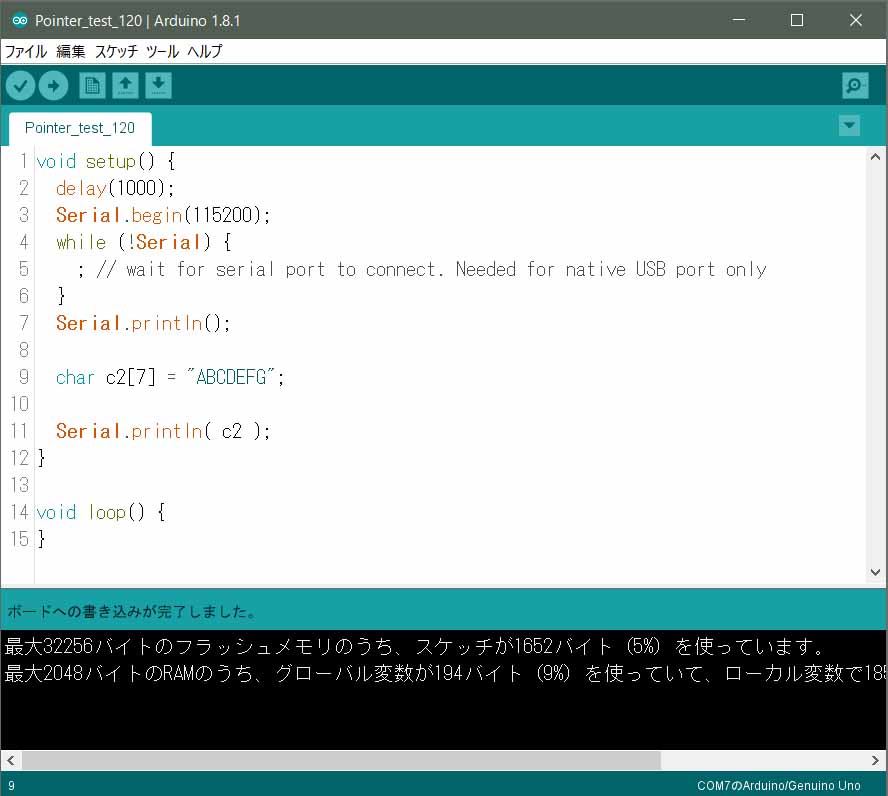
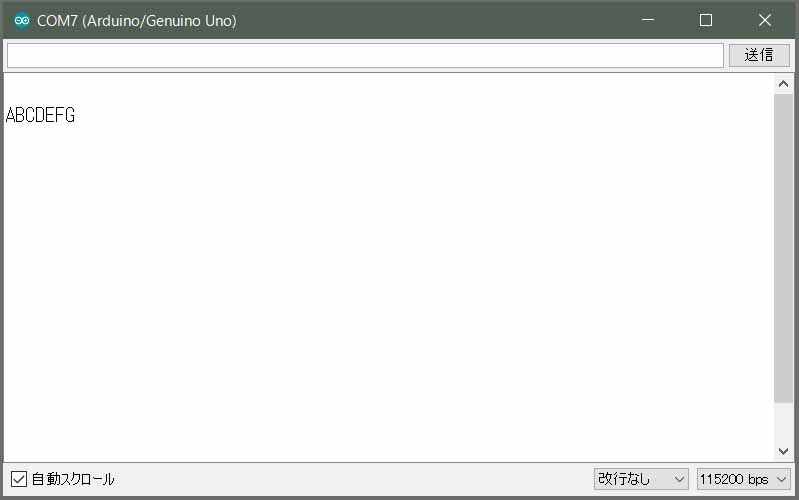
なんと、コンパイルも難なく通って、シリアルモニターにも以下のように表示されました。
これはどういうこっちゃ???
これはエラーとなってくれないと困りますね。
今まで、そういう話しの流れで ‘\0’ までコンパイラが自動で初期化してくれて、シリアルモニターでは ‘\0’ まで読み込むということだったはずですから・・・。
試しに、
char c2[3] = "ABCDEFG";
とやっても、コンパイル正常終了し、シリアルモニターには
ABC
と表示されます。
そして、
Serial.println( c2[3], HEX);
としてみたら、シリアルモニターにはゼロが表示されます。
つまり、配列の4番目の’D’をヌル終端 ‘\0’ に置き換えてメモリに格納したということです。
普通のC言語では有り得ないですよね。
これはC言語をある程度勉強してしまうと、逆に意味不明ですよ。
これも、先に述べたように、実はArduino IDE で詳細なコンパイラエラーを見ることができました。
Twiiter で北二十四条低音組合さんから教えていただきました。
すると以下のような警告メッセージが出ていました。
warning: initializer-string for array of chars is too long [-fpermissive]
やはり、配列宣言の文字数よりも、ダブルクォーテーション囲み文字列が長すぎるという警告です。
これが出て安心しました。
でも、デフォルト設定でコンパイル不可として欲しいですねぇ・・・。
因みに、Twitter で、もあさんや北二十四条低音組合さんから情報を頂いたんですが、ESP8266 と Arduino では呼ばれるコンパイラが異なったり、バージョンが異なったり、更にオプション設定が異なったりしているそうです。
ということは、あくまで想像ですが、Arduino に関しては、仕様としてコンパイラをそのように設定しているのかもしれません。
残念ながら、私はコンパイラについてはまだサッパリ分かりませんので、今回はこの検証は先送りにします。
でも、Arduino のコンセプトを考えてみると、敷居を低くして、誰でも参入しやすい開発環境を構築していると考えると、納得します。
これはビギナーにとっては、もっとも分かりやすい結果だからです。
見えない ‘\0’ を一切考えなくていいのですから・・・。
調べたことないのですが、BASIC言語もこんな感じなのかもしれませんね。
これについては、下のコメント投稿欄で、「匿名」さんが検証してくださいました。 是非参照してみてください。 このようなArduino UNO の誤った配列初期化は他の引数初期化に悪影響を及ぼします。シリアルモニターで予想できない表示になってしまうので要注意です。
と、いうことは、Arduino IDE で複雑なプログラムを組もうとすると、同じArduino IDEでもボードを変えるとコンパイル構成が変わるということのようです。
これをよく念頭に置いて作らなければなりません。
さて、話を戻しまして、今度は1文字ずつ配列に文字を代入していく場合を考えます。
以下のスケッチをコンパイルしてみてください。
【ソースコード】 (※無保証 ※PCの場合、ダブルクリックすればコード全体を選択できます)
void setup() {
delay(1000);
Serial.begin(115200);
while (!Serial) {
; // wait for serial port to connect. Needed for native USB port only
}
Serial.println();
char c2[7];
c2[0] = 'H';
c2[1] = 'e';
c2[2] = 'l';
c2[3] = 'l';
c2[4] = 'o';
c2[5] = '!';
Serial.println( c2 );
}
void loop() {
}
Arduino IDE ESP8266ボードでコンパイルした結果です。
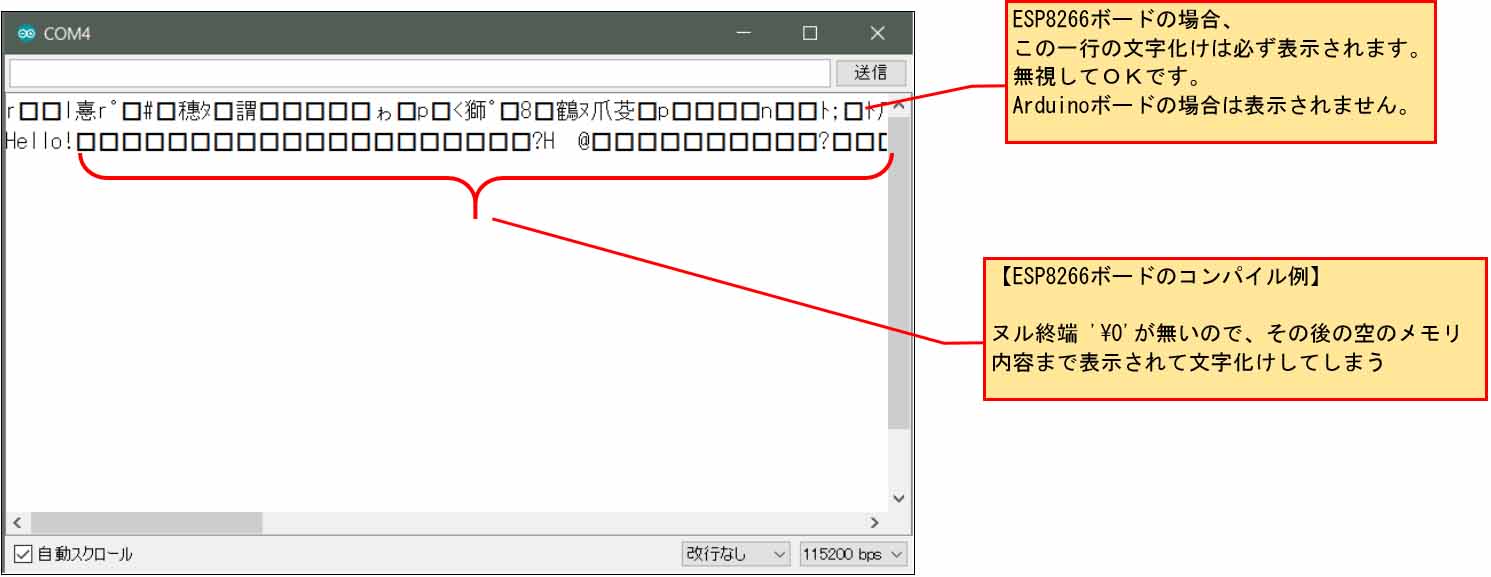
期待通り、ヌル終端は自動で入らないので、その後の空きのメモリまで参照して、文字化けしていますね。
では、Arduino UNO ボードでコンパイルすると、こんな風に表示されます。
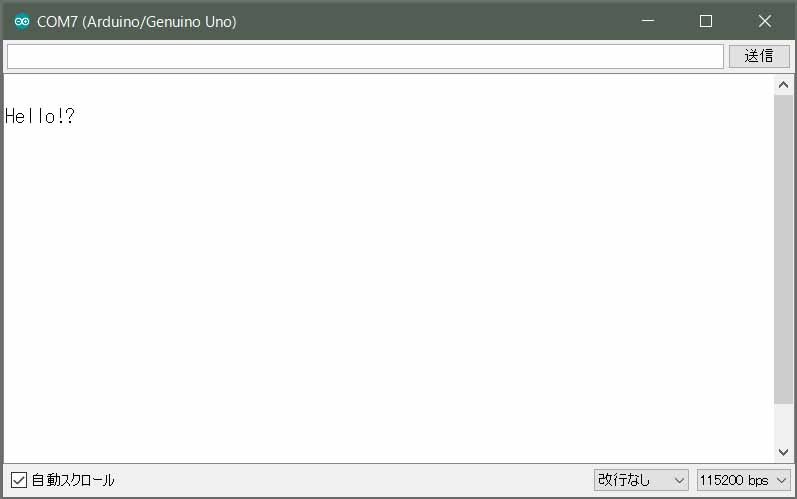
これはポインタをある程度勉強した人にとっては、理解し難いかもしれません。
‘?’ という文字を入れたっけ?
と思ってしまいます。
プログラム初心者からすれば、意味不明の文字化けが出るよりも、こっちの方が安心するからなのでしょうか?。
まぁ、Arduino の 「スケッチ」というコンセプトに合っていると思います。
ただ、これは逆にポインタの理解を妨げる要因にも成り得るような気がします。
Arduino はやはり、ポインタを使わない前提のコンセプトが垣間見えてきます。
以上から、char型文字列の場合、初期化する時と、代入する時とでヌル終端 ‘\0’ を入れるか入れないかを常に意識しておかないと、複雑なプログラムの場合、予期せぬエラーになってしまいます。
そして、使うボードのコンパイラの特性をある程度把握していなければ、シリアルモニターで勘違いしてしまうことを念頭に置いておかねばなりません。
特にIoT を実現したいとなれば、WEB から多量の文字列を処理するプログラムを作ることになると思います。
電子工作用途マイコンだと、少ないメモリの中で、如何に節約するかがカギになってきます。
そうすると、メモリを消費するStringクラスを使うことを避けて、char型ポインタを使おう考えてしまいます。
そこでいろいろな落とし穴が先に待ち構えているわけです。
こういうことは、私のようなアマチュアの電子工作家にとっては、なかなか分からないことだと思います。
まとめ
私が今までマスターしていたと思い込んでいたものが、今回は完全に覆されてしまいました。
いろいろ情報は収集していたのですが、ダブルクォーテーションで囲った文字列なんて、そりゃぁ、読み飛ばしてしまいますよ・・・
(言い訳です)
今回の件は、自分なりにいろいろ調べてみて、腹に落ちたのですが、もし間違いがあったら是非教えていただけると助かります。
このブログはあくまで趣味程度の個人ブログなので、この記事を読まれた方はあまり信用せずに、ご自分で確かめください。
しかし、C言語の文法は本当にややこしいですね。
「スケッチ」するようにプログラミングなんてなかなか出来ないですよ・・・。
Arduino というのは、こういう勉強をしないでも、アマチュアが気軽に組み込みプログラミングできるようにしたことはとてもスバラシイものがあります。
String クラスは、ダブルクォーテーション囲み文字列の規則など考えずに、自由に文字の書き換え操作ができますよね。
ですが、Stringクラスはメモリをかなり消費するために、あまり使いたくないと考えてしまうと、char型ポインタに手を出してしまうことになります。
すると、こういう複雑な構造が隠れているのは私のようなアマチュアではなかなか分からないものだと思います。
ですから、Arduino のコンセプトとして、アマチュアが参入しやすいように敷居を下げて、ポインタを極力使わないようにした意図がよく分かりました。
今回の新たな発見は、しなぷすさん、まりすさん、匿名さんのご指摘が無かったら絶対に分からなかったことです。
改めて、感謝いたします。
ありがとうございました。
m(_ _)m
というわけで、今回はここまでにします。
次回はポインタのローカル関数間の受け渡しについて再考してみようと思っています。
ではまた・・・。
Amazon.co.jp 当ブログのおすすめ
コメント
mgo-tecさん、こんにちわ。記事ご苦労様でした。おかげさまで大変勉強になりました。そしてハイレベルの人のアドバイスも助かりますね。本の題名ではないですが「今更聞けないESP8266」とか「サルでも解るESP8266入門」的なものは「聞く事が出来ないので」良いですね。私は基礎無くArduinoを初め文法など解らずにやっています。そしてある程度出来て「文字や数値の通信を」始めると必ず「String」や「Char」で振り出しに戻ります。そうすると「Arduinoをはじめよう」の本を開いたりネット検索し Stringでは「Arduino 日本語リファレンス」「文字列(配列)」に行き着きます。
http://www.musashinodenpa.com/arduino/ref/index.php?f=0&pos=1259
mgo-tecさんが言われる様に「Arduino のコンセプトを考えてみると、敷居を低くして、誰でも参入しやすい開発環境」や「アマチュアが参入しやすいように敷居を下げて、ポインタを極力使わないようにした意図」を大切に思っています。そうする事によって自分や多くの人が楽しむ事ができると思っています。
今回のポイントは「Arduino Preferences」で「詳細な表示をオン」にする事により「検証」や「マイコンボードに書き込む」時のエラーが表示できて解り易くなる。エラーがでても書込みができる場面が多いですが、1つの方法はエラーをヒントに調べたり記述を変えて見る方法があると言う事。私はポインターとか専門用語を使用せず「解り易い文法で公開」を心がけています。
又、私の2つ目のコンセプトは「価格」です。最安値で購入し易いボードや部品を紹介をしています。例えば ESP8266では電波を出さなければ「400円以内で出来るボード」があります。国内のある価格と比較するとボードが5つも購入できる訳です。安いからこそ自分も皆も楽しめる。
尚、今回のテーマではありませんが「ESP8266の起動時にシリアルモニターに文字化け」が出ます。これはシリアルモニターのボーレートを「74880bps」にすると見る事が出来ます。この表示を見ると これまた ハマりそうになります。
次回の基礎編の記事を楽しみにしています。
macsbugさん
ご無沙汰しております。
いぁ~、ありがたいコメントでございます。
しかし、かなりコアなブログ記事を書いてらっしゃる macsbug さんでも、私と同じような所で悩んでいらっしゃったとはビックリです。
かなり、心強く思ってしまいました。
さすがに今回は不勉強でへこみましたが、この分野には、どエライ数のプロのエンジニアがいるということを肌で感じましたね。
こりゃ、かなわないなぁ、と思いました。
>「解り易い文法で公開」を心がけています。
これはスバラシイです。
私は難しいものも平気で公開しちゃってます。
でも、より多くの方に門を開いてもらうためには、そうするべきですね。
安価な ESP8266 については、私の場合はスマホと連携するために、必ず電波を使用する前提でプログラムを組んでいるので、残念ながら、なかなか当ブログではお勧めできないところです。
確かに、確実に電波を出さないのであれば、かなり安価にArduino プログラミングできますね。
シリアルモニターの74880bbsで文字化け解消は、私も存じておりました。
以下の記事で紹介しております。
ESP8266, ESP-WROOM-02, ESPr Developer トラブルシューティングまとめ
情報ありがとうございます。
ということで、macsbug さんのコメントでかなり元気づけられました。
改めて感謝いたします。
ありがとうございました。
m(_ _)m
お互い、負けずにこれからもガンガン投稿していきましょう!!!
先日いろいろ文句を言ったものです。
とても興味深い記事ですね。
ここまでくると記憶だけでは怪しいので、
仕様書などを確認したり、検証したりしてみました。
CとC++とが入り乱れているので注意してください。
参照した仕様は以下の通りです。
C: http://www.jisc.go.jp/app/pager?%23jps.JPSH0090D:JPSO0020:/JPS/JPSO0090.jsp=&RKKNP_vJISJISNO=X3010
C++: http://www.jisc.go.jp/app/pager?%23jps.JPSH0090D:JPSO0020:/JPS/JPSO0090.jsp=&RKKNP_vJISJISNO=X3014
コピーができないので、引用の際、typoの可能性があります。
文句を言った割には一部怪しいところもあるので、語尾に気を付けてください。すみません…
また、arduino unoを前提としています。
まず、.ino ファイルは、avr-g++ によってコンパイルされます。
つまり、C言語ではなくC++言語です。でないと、Serial.print()とかがそのままは使えません。
(追加で作成した .cファイルは avr-gcc で、.cpp ファイルは avr-g++ でコンパイルされます)
(1) ダブルクォーテーション囲い文字列の書き換えについて
[C]6.7.8 初期化 の例8に以下の記載があります。
char *p = “abc”; は、pを”charへのポインタ”型として定義し、要素が単純文字列リテラルで初期化され、
長さが4の”charの配列”型オブジェクトを指すように初期化する。pを用いてその配列の内容を変更しようと
した場合、その動作は未定義である。
つまり、文字列リテラルの書き換えは、仕様では決まっておらず、処理系依存です。
arduinoを壊すという動作をしてもC言語としては問題ありません^^
[C++]2.13.4 文字列リテラル に以下の記載があります。
通所の文字列リテラルは、”n個のconst charの配列”型を持ち
ということで、Cではできるかもしれない、C++ではできない、が正しいと思います。
ただし、記載されている通り、char * への変換も認められてはいます。
実際の動作については、linuxなどでは、文字列リテラルは .text セクションという
書き換え不可領域に配置されるので、実行時にエラー(おそらくsegmentation fault)になると思います。
一方で、arduino unoでは、.text セクションは、flashメモリのことで、
これはスケッチが配置される領域です。PROGMEM指定されたデータも配置されます。
通常の文字列リテラルは、.data という領域に配置されるはずで、この領域は書き換え可能です。
なので、arduino unoでは書き換え可能なのだと思います。
参照: http://www.nongnu.org/avr-libc/user-manual/mem_sections.html
文字列リテラルを参照するポインタの参照先の内容を書き換えない方がいいのはおっしゃる通りと思います。
(2) ヌル文字(終端)’\0’ の挿入について
[C]6.7.8 初期化に以下の記載があります。
文字型の配列は、単純文字列リテラルで初期化してもよい。それを波括弧で囲んでもよい。
単純文字列リテラルの文字(空きがある場合又は配列の大きさがわからない場合、
終端ナル文字も含めて。)がその配列の要素を前から順に初期化する。
前から順に初期化するので、配列の大きさより多い初期値を与えても、配列の大きさまでを初期化します。
この場合、’\0’は入りません。
[C++]8.5.1 集成体に以下の記載があります。
配列要素の個数より多い《初期化子》があってはならない。
ということで、C++ではエラーです。
では、なぜ、arduino uno でエラーとならないかですが、avr-g++のコンパイル
オプションに、 -fpermissive というのがついているからだと思います。
これは一部の非適合コードをエラーではなく、警告にとどめるものです。
参照: https://gcc.gnu.org/onlinedocs/gcc/C_002b_002b-Dialect-Options.html#C_002b_002b-Dialect-Options
試しに、このオプションを外してみると、エラーとなりました。
オプションは、\Arduino\hardware\arduino\avr\platform.txt というファイルの、
compiler.cpp.flags という箇所に記載されています。
私のwindows 10 PCでは、上記は C:\Program Files (x86)に配置されています。
char c2[3] = “ABCDEFG”; については、C++ではエラーですが、上記オプションにより
ABCで初期化されたということだと思います。文字Cの後は、たまたま、’\0’だったのだと思います。
(3)おまけ
お時間があるようでしたら、以下のプログラムを, arduino uno で実行してみてください。
Serial.begin()の引数は適切に変更してください。
——————————————————-
void setup() {
// put your setup code here, to run once:
char *c1 = “abcd”;
char *c2 = “abcd”;
char c3[] = “world”;
char c4[6] = “Hello “;
Serial.begin(9600);
c1[0] = ‘X’;
Serial.println(c1);
Serial.println(c2);
Serial.println(c3);
Serial.println(c4);
}
void loop() {
// put your main code here, to run repeatedly:
}
—————————————
匿名さん
詳細な検証していただき、涙がチョチョ切れるくらい、有難く、感謝の言葉もありません。
貴重なお時間を割いて投稿していただき、そして、当記事をお読みいただき、本当にありがとうございます。
m(_ _)m
なるほど、JISの資料を参照するんですね。
どこをどう見たら答えが出るのか、情報が沢山で迷ってしまいました。
調べる時間もそんなに無いので、こういうことを教えて下さるのは、とても有難いことです。
そういえば、ライブラリは全て.cpp ですので、C++ でコンパイルしているんだろうとは思っていました。
でも、Arduino 日本語訳にあるように、一部の機能しかサポートしていないとなると、またややこしいですね。
(1) 文字列リテラルの書き換えについては、
「Cではできるかもしれない、C++ではできない」
ということを覚えておきますが、要するに書き換えないということにすべきですね。
なるほど、コンパイラによって、出力結果が変わることはよくわかりました。
(2)ヌル文字終端については、-fpermissive が何か関係しているんだろうとは思っていましたが、やっぱりオプション指定でしたか・・・。
これで納得しました。
そもそも、platform.txt を見れば、どういうオプション指定しているのかが分かるというのは、初めて知りました。
こんなコアなところ、アマチュアではまず見ないですから・・・。
なるほど、やはりその道の熟練者からのアドバイスは適格ですね。
いやはや、参りました・・・。
(3)おまけについて、
これはメチャクチャ驚きました!!
こんな予想外の結果になるとは・・・。
表示されたのは、
ですよ。
なんじゃこりゃ!
1つ目2つ目の結果は文字列リテラルを書き換えたことによる「未定義」の成せる業でしょうか?
Hello world はヌル終端の無い初期化の為に、たまたま次のアドレスにworld があったというだけということでしょうか。
これ、メチャメチャ面白い結果ですね。
ビギナーがこれを合っていると思い込んでプログラミングしたとしたら、この結果で悩みまくるでしょうね。
私も、複雑なプログラムを組んで、ついウッカリこういう初期化をやってしまって、出力結果がこんなんだったら、ハマリにハマるでしょうね。
いやぁ~、とても勉強になりました。
それにしても、やはりある程度正確な知識を持ってプログラミングしないと、期待通りの結果にならないことがよ~くわかりました。
この匿名さんのコメントは、Arduino プログラミングに悩んでいる方の助けになると思います。
今回はとても有意義な情報、ありがとうございました。
また何かありましたら、ご意見いただけると助かります。
でも、何分、他の仕事の傍らのブログ制作なので、すぐには修正できないかもしれませんのでご容赦ください。
おまけについてです。
最初の結果は、 c1 と c2は、実は同じアドレスを指しているからです。
仕様上認められた動作です(異なるアドレスに配置しても問題ありません)。
書き換えは未定義ですが。
2つ目はおっしゃる通りです。
大変失礼しました。
そういえば、文字列リテラルは先頭アドレスを返しているのでした。
どうも、文字列リテラルは配列っていうイメージが抜け切れていません。
当たり前ですが、ダブルクォーテーションで囲った文字列は同じアドレスに格納されているわけで、初期化したポインタ名が異なっても、それにアドレスを代入しているだけなので、c1==c2 ということですね。
これはArduino だけしかプログラミングしたことの無い人達は知らない人が多いと思います。
ポインタを勉強し始めたら、まずこれでつまづきますね。
それと配列の初期化については、以下のようにすると、結果が分かりやすくなりました。
結果
このことから、’\0’は、たまたま c4 の”st” の後にあったと言えます。
試しに、c5 の配列長をいろいろ変えてみました。
char c5[] = “STUVWXYZ”;
とした場合、結果は
次に、
char c5[7] = “STUVWXYZ”;
とした場合の結果は
これは面白いですね。先頭アドレスの配置順序はASCIIコード順かと思いきや、初期化の仕方によってアドレスが変わってしまうようです。
いずれにしても、配列の初期化は「文字列+1文字」にしないと、予期せぬエラーになるということがハッキリしました。
今回もとても勉強になりました。
これでようやく先へ進めそうです。
ありがとうございました。
m(_ _)m
お悩み、よくわかります。私がポインタを明確にイメージできたのは、
「ポインタはアドレスを格納する『変数』、すなわちアドレス変数であり、アドレス自体はポインタではない。」
ということに気づいたときでした。私はそれまで、「”ポインタ”という用語は、”アドレス”の別の呼び方」だと思っていたのです。しかし、これが混乱の原因でした。
例えば、こういうコードがあったとして、
char a[10];
char b;
char *c;
c=a;
c=&b;
c=”文字列”;
以前の私は、この「c=a」を「ポインタcにポインタaを代入している」と考えていたのですが、これは間違いでした。aはポインタではなく、コンパイル時に静的に決まるアドレス(定数)なんですよね。同じく、「”文字列”」と「&b」も、ポインタではなくただの定数でした。
でも、ひとたび「ポインタはアドレス変数である」と考えると、
「c=a」は「アドレス変数cに、配列aの先頭アドレスを代入している」
「c=&b」は「アドレス変数cに、変数bのアドレスを代入している」
「c=”文字列”」は「メモリのどこかに置かれた”abc\0″という領域の先頭アドレスを代入している」
といことが明確に理解でき、混乱することがなくなりました。
みなつさん
記事をご覧いただき、ありがとうございます。
なるほど。
定数っていうところがミソですね。
ポインタはサラッと流して勉強してしまうと、とんでもない勘違いをしてしまいますね。
何でこんなややこしい言語作ったんだろうと恨みましたが、C言語は長~い歴史があって、止むを得ずこうなっているということも最近知りました。
この分野は先駆者や熟練者が沢山おりますので、一人でネットで調べるよりも、その方々からアドバイスを頂いた方が確実に勉強になりますね。
私もこれでほぼ混乱しないと思います。
ご意見ありがとうございました。