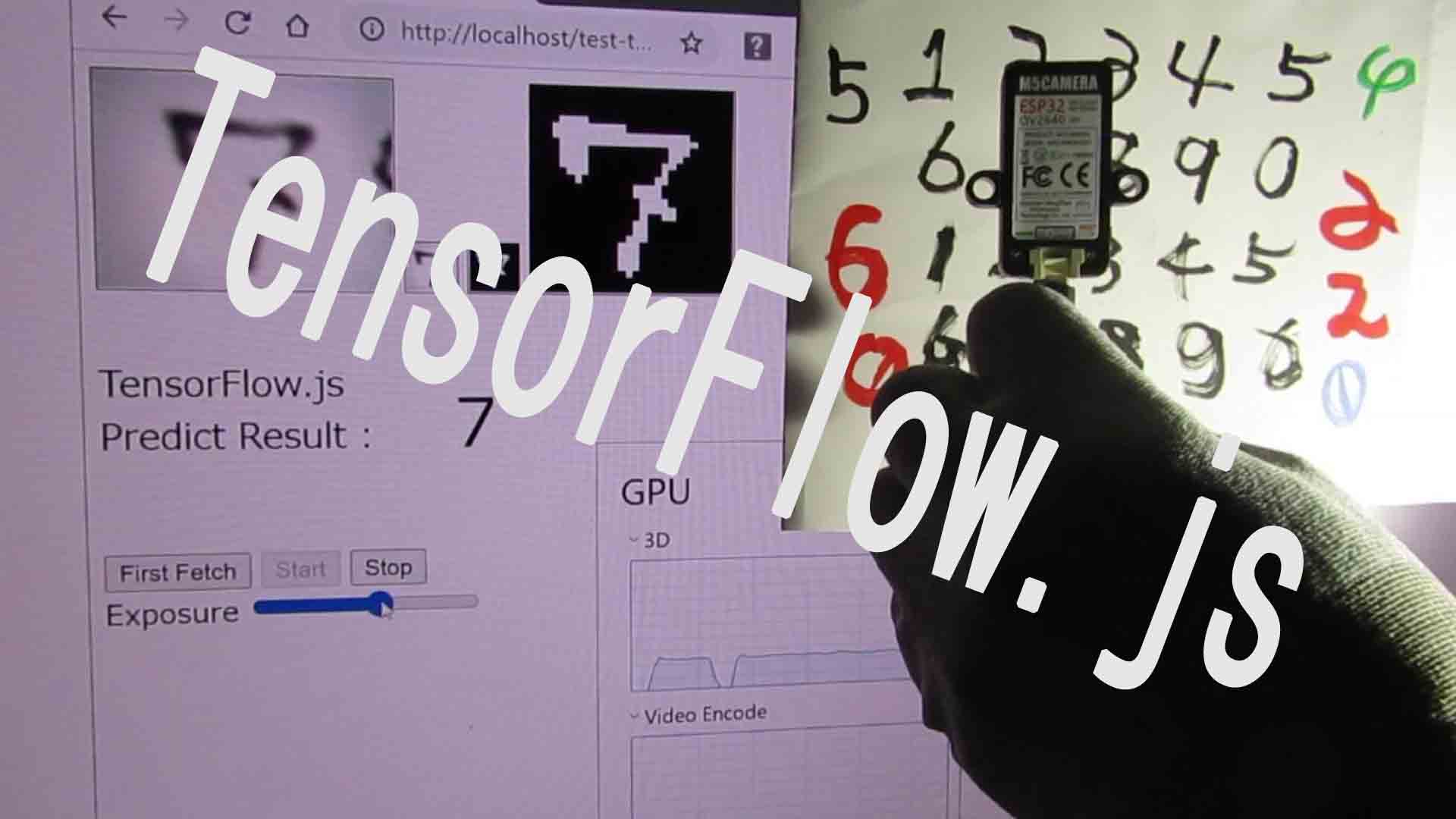
前回記事に引き続き、ディープラーニングのお勉強第13弾で、今回はブラウザ上でJavaScriptのTensorFlow.jsを使って、学習済みモデルのリアルタイム推論してみました。
手書き数字MNISTデータセットで学習させたモデルを使いました。
映像についてはいつもどおり、M5CameraサーバーのMotion JPEGを使いました。
前回記事ではGoogle Colaboratory上でリアルタイム推論させていましたが、コールバック関数でOpenCVを使っていた為か、推論結果が出るまでタイムラグがありました。
しかし、今回はGoogle Colaboratory上で推論することをやめて、ブラウザのJavaScriptで完結させてモデル推論させると、はるかに高速リアルタイムで推論することができました。
何はともあれ、以下の動画をご覧ください。
前回に比べて、かなりリアルタイムで追従して推論できていますね。
しかも、動画を見て分かる通り、パソコンにGPUが積んであれば、GPUを使って計算してくれます。
Canvas表示だけでもある程度GPU使いますが、TensorFlow.jsのpredictを使うと、倍以上GPUを使用してくれます。それについては最後の方で述べます。
TensorFlow.jsは簡単にできそうな気がしましたが、実際にプログラミングして動かしてみると、ちょっと特殊な使い方が必要でした。
何も意識せず、普通にJavaScriptを組んで実行すると、数分でパソコンのメモリを食い尽くし、ブラウザがブラックアウトしました。
その原因は、tidy関数を使わなかったことによるものだったのですが、なかなか特殊だなと思いました。
それに、テンソルオブジェクトというものを理解するまでに時間がかかり、値を抽出するのに、dataSyncやarraySyncを使わないとダメとか、ちょっと頭が混乱ました。
では、自分なりにやってみた方法を紹介して行きます。
Windows10の場合で説明します。
ちなみに、私はJavaScriptもTensorFlowも独学の素人です。
何か誤り等ありましたら、コメント投稿でご連絡いただけると助かります。
- 事前準備
- tensorflowjs_converter を使ってKerasモデルを変換出力
- HTMLおよびJavaScriptコード
- ブラウザ上で実行
- TensorFlow.jsのGPU使用状況について
- まとめ
【目次】
事前準備
ローカル仮想サーバー環境を構築しておく
XAMPPとか、Dockerとかで、パソコンにローカル仮想サーバー環境を構築しておきます。
Dockerはネットの情報では評判がよく、業界標準?らしいので、そちらの方が良いかと思われます。
ちなみに、私は未だにXAMPPですが、いずれDockerをインストールしたいと思っています。
Google Colaboratoryを使えるようにしておく
以下の記事を参照して、Google Colaboratoryを使えるようにしておきます。
ディープラーニングのお勉強~その8。Google ColaboratoryでPythonプログラミングして機械学習してみた~
手書き数字MNSTデータセットで学習させたモデルをHDF5(.h5)形式で出力しておく
以下の記事を参照して、事前にGoogle Colaboratoryで手書き数字MNISTデータセットを使って機械学習させたモデルをHDF5(.h5)形式で出力させておきます。
ディープラーニングのお勉強~その9。Google Colab Kerasのレイヤー設定を独自に解釈してみた~
M5Cameraにスケッチを書き込んでおく
以下の記事を参照して、ESP32-WROVER搭載のM5Cameraにスケッチを書き込んでおきます。
そして、M5CameraのWi-FiローカルネットワークのIPアドレスを確認しておきます。
ngrokによるBasic認証M5Cameraサーバーの映像をGoogle Colaboratoryに表示させてOpenCVで画像処理させてみた
Wi-Fiルータ環境を整えておく
M5CameraをWi-Fiでローカルエリアネットワークに接続できるように、Wi-Fiルータ環境を整えておきます。
M5CameraはSTAモードで動作させます。
tensorflowjs_converter を使ってKerasモデルを変換出力
以前のこちらの記事のように、Google Driveに保存しておいたHDF5(.h5)形式の学習済みKerasモデルを、tensorflowjs_converterを使って、TensorFlow.jsで使えるように変換します。
公式の以下のドキュメントを参考にして進めていきます。
Keras モデルを TensorFlow.js にインポートする
ここでは例として、予めGoogle Driveにaaaaaaaaという名前のフォルダを作って、そこに学習済みHDF5(.h5)ファイルを保存して置き、変換後に出力するフォルダをbbbbbbbbフォルダとして作成しておきます。
そして、Google Colaboratoryを起動し、新規にJupyter Notebookを作成して、以下のコードを入力すればOKです。
!pip install tensorflowjs
!tensorflowjs_converter --input_format keras \
/content/drive/MyDrive/aaaaaaaa/my_model.h5 \
/content/drive/MyDrive/bbbbbbbb
pipコマンドで、Google ColaboratoryにTensorFlow.jsをインストールします。
そして、tensorflowjs_converterコマンドでHDF5(.h5)形式モデルファイルをTensorFlow.js形式へ変換します。
Kerasで作成したモデルの場合は、オプションが --input_format keras となります。
上記の例では、Google Driveのマイドライブ中のaaaaaaaaフォルダにあるmy_model.h5というモデルを読み込み、TensorFlow.js形式に変換したモデルをbbbbbbbbフォルダへ出力します。
自分の場合のJupyter Notebookの実行結果は以下のように表示されました。
(図01)
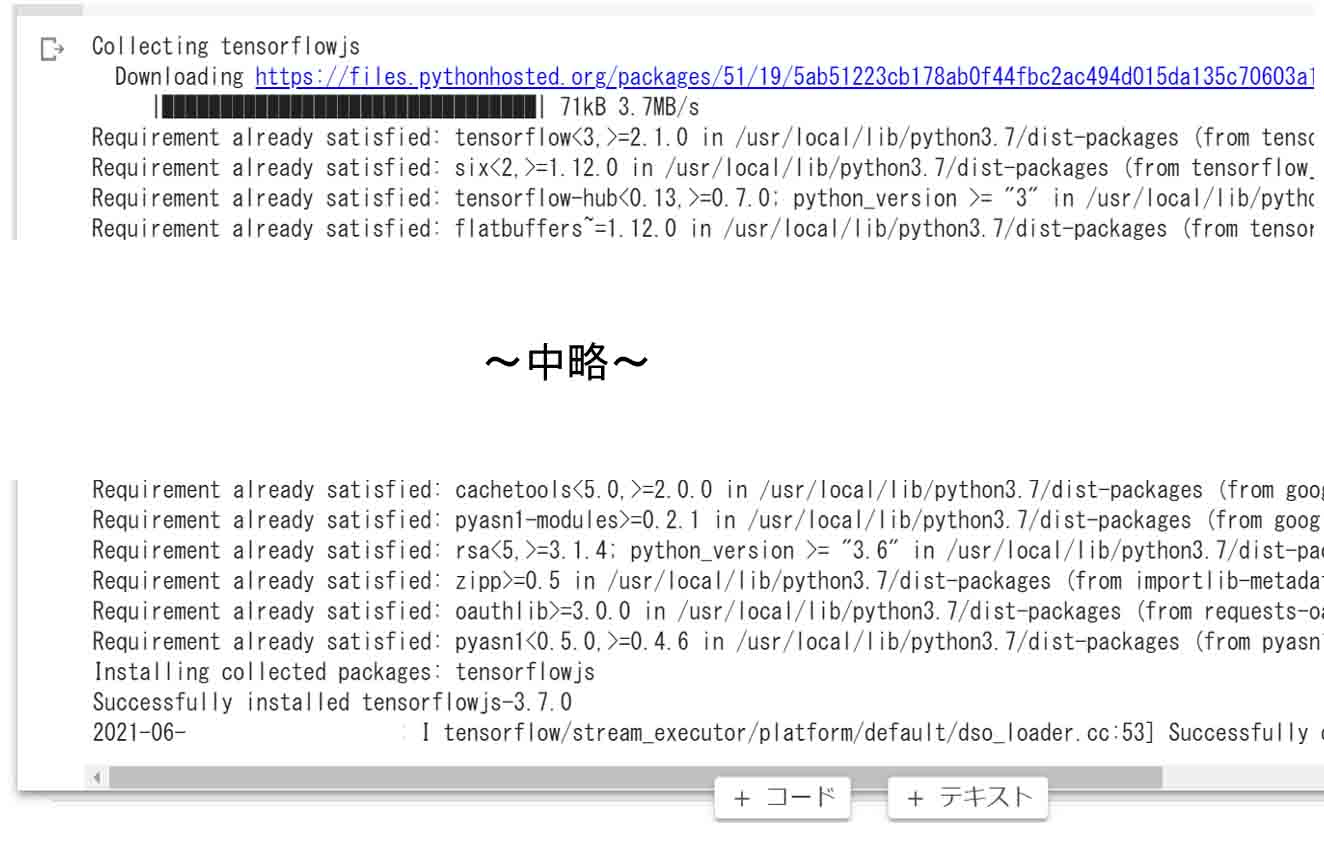
tensorflowjs_converterで推論モデルを変換した結果
この場合はTensorFlow.jsは既にインストールされていた模様です。
すると、bbbbbbbbフォルダには以下の2つのファイルが出力されていました。
model.json group1-shard1of1.bin
この2つのファイルをローカル仮想サーバーの任意のフォルダにコピーしておきます。
HTMLおよびJavaScriptコード
TensorFlow.jsでは、Node.jsでも使用できますが、今回はブラウザ側のコードを組んでいきます。
まずは実際に使ったHTMLおよびJavaScriptコード
では、まずは素人ながら自分なりに組んでみたHTMLおよびJavaScriptコードを紹介してみます。
以下のコードはテキストエディタで入力して、拡張子を.htmlにして保存すればよいです。
保存先は、XAMPPならば、例としてhtdocsフォルダにtest-tfjsのような任意の名前のフォルダを新規に作って、そこに保存しておきます。
先に紹介した、model.jsonファイル、および group1-shard1of1.bin ファイルもそこに保存しておきます。
すると、以下の様なURLになると思います。
http://localhost/test-tfjs/test.html
33行目で、M5CameraのローカルIPアドレスに書き換えておきます。
また、112行目の推論モデルのパスも書き換えておきます。
このコードの解説は後で説明します。
<!doctype html>
<html>
<head>
<meta name='viewport' content='width=device-width, initial-scale=1' charset='utf-8'>
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs/dist/tf.min.js"></script>
<style>
.box{border: 1px solid}
.result1 p{display: inline-block; text-align: left;}
</style>
</head>
<body>
<div>
<img id='id_mjpeg' class='box' crossOrigin='use-credentials'>
<canvas id='canvas_gray' class='box'></canvas>
<canvas id='canvas_bin' class='box'></canvas>
<canvas id='canvas_st' class='box'></canvas>
<div class='result1'>
<p style='font-size: 20px'>TensorFlow.js<br>
Predict Result :</p>
<p id='result_id' style='font-size: 250%; text-indent: 1em;' >-</p>
</div>
</div>
<div>
<button onclick='firstFetch()'>First Fetch</button>
<button id='btn_start' onclick='startStream()'>Start</button>
<button id='btn_stop' onclick='stopStream()'>Stop</button>
<div>Exposure
<input type='range' id='aec_val' max='255' onchange='aecVal()'>
</div>
</div>
<script>
const host_url = 'http://192.168.0.10', //自分のサーバーに書き換える
url_mjpeg = host_url + '/stream';
var requestAnimationFrame = window.requestAnimationFrame ||
window.mozRequestAnimationFrame ||
window.webkitRequestAnimationFrame ||
window.msRequestAnimationFrame,
cancelAnimationFrame = window.cancelAnimationFrame ||
window.mozCancelAnimationFrame;
var anime_req_id = 0;
const img_width = 160, img_height = 120,
mnist_pix = 28;
const mjpeg = document.getElementById('id_mjpeg');
mjpeg.width = img_width;
mjpeg.height = img_height;
const gray_canvas = document.getElementById('canvas_gray'),
gray_canvasCtx = gray_canvas.getContext('2d');
gray_canvas.width = 28;
gray_canvas.height = 28;
const bin_canvas = document.getElementById('canvas_bin'),
bin_canvasCtx = bin_canvas.getContext('2d');
bin_canvas.width = mnist_pix;
bin_canvas.height = mnist_pix;
const st_canvas = document.getElementById('canvas_st'),
st_canvasCtx = st_canvas.getContext('2d');
st_canvas.width = 120;
st_canvas.height = 120;
const result_elm = document.getElementById('result_id');
const btn_start = document.getElementById('btn_start'),
btn_stop = document.getElementById('btn_stop'),
range_aec = document.getElementById('aec_val');
btn_start.disabled = true;
btn_stop.disabled = true;
function firstFetch(){
btn_start.disabled = false;
btn_stop.disabled = false;
changeCtrlCam('first', 0);
}
function startStream(){
btn_start.disabled = true;
let d = new Date();
mjpeg.src = url_mjpeg + '?' + d.getTime();
mjpeg.onload = useTfjs();
}
function stopStream(){
btn_start.disabled = false;
cancelAnimationFrame(anime_req_id);
changeCtrlCam('stop_stream',0);
}
function aecVal(){
let aec_val = range_aec.value;
changeCtrlCam('aec_val',aec_val);
}
function changeCtrlCam(var_txt, value_txt){
let ctrl_url = host_url + '/control?var=';
ctrl_url += var_txt + '&';
ctrl_url += 'val=' + value_txt;
fetch(ctrl_url, {
method: 'GET',
credentials: 'include', //これ重要
mode: 'cors'
})
.then(response => response.text())
.then(data => console.log(data));
}
async function useTfjs() {
//サーバー環境でモデルをロードする。Promiseで返るので、awaitする。
const model = await tf.loadLayersModel('http://localhost/test-tfjs/model.json');
const bin_threshold = 200; //画素2値化の閾値
_canvasUpdate();
function _canvasUpdate(){
//160×120画像をグレースケールに変換して、中央の120×120画像を切り取って、28×28pxに表示
gray_canvasCtx.filter = 'grayscale(100%)';
gray_canvasCtx.drawImage(mjpeg, 20, 0, 120, 120, 0, 0, 28, 28);
//画像を2値化して、白黒反転してcanvasに表示
let src1 = gray_canvasCtx.getImageData(0, 0, mnist_pix, mnist_pix);
let dst = bin_canvasCtx.createImageData(mnist_pix, mnist_pix);
for (let i = 0; i < src1.data.length; i += 4) {
if (src1.data[i + 1] < bin_threshold) {
dst.data[i] = 255; //Red
} else {
dst.data[i] = 0;
}
dst.data[i + 1] = dst.data[i]; //Green
dst.data[i + 2] = dst.data[i]; //Blue
dst.data[i + 3] = 255; //アルファチャンネル(不透明度)
}
bin_canvasCtx.putImageData(dst, 0, 0);
//2値化した28×28画像を確認しやすいように120×120 pixに引き伸ばし表示
bin_canvas.toBlob(function(blob) {
const img_url = URL.createObjectURL(blob);
let tmp_img = new Image();
tmp_img.src = img_url;
tmp_img.onload = function() {
//アンチエイリアシング解除。(デフォルトはON)
//bin_canvasCtx.mozImageSmoothingEnabled = false;
//bin_canvasCtx.webkitImageSmoothingEnabled = false;
//bin_canvasCtx.msImageSmoothingEnabled = false;
st_canvasCtx.imageSmoothingEnabled = false;
st_canvasCtx.drawImage(tmp_img, 0, 0, mnist_pix, mnist_pix, 0, 0, 120, 120);
URL.revokeObjectURL(img_url);
};
});
//2値化画像から配列の次元を変えて推論する。
//メモリリークを防ぐためにtidyでラップする。Promiseで返すのはNG
var result = tf.tidy(() => {
let bTensor = tf.browser.fromPixels(bin_canvas);
//(28, 28, 3) height, Width, Color のため、Color次元を分割。unstackはテンソルの配列を返す。
let tmp = tf.unstack(bTensor, 2);
bTensor = tmp[0]; //RGBカラーのRed成分だけ取り出す。(28, 28, 1)
//0.0~1.0の値に正規化
bTensor = tf.cast(bTensor, 'float32');
bTensor = tf.div(bTensor, tf.scalar(255));
//channel_firstのモデルへ入力するためにreshapeする。
bTensor = bTensor.reshape([1, 1, 28, 28]);
//同期で推論する。dataSync()は同期。data()は非同期。返り値はテンソルのJavaScritオブジェクト。
const predictions = model.predict(bTensor).dataSync();
//推論配列の最大値インデックス取得して返す。arraySync()は、テンソルではなく、単純配列を返す。
return tf.argMax(predictions).arraySync();
});
//推論結果をテキスト表示
result_elm.textContent = result;
//canvasアニメーションループ実行
anime_req_id = requestAnimationFrame(_canvasUpdate);
}
}
</script>
</body>
</html>
画像の前処理
画像の前処理は、TensorFlow.jsでやるよりも、JavaScriptのCanvasでやった方が個人的には楽でした。
Canvasでグレースケールにし、ダウンスケーリングする
まず、カラー画像をグレースケールに変換します。
TensorFlow.jsでグレースケールに変換する方法もありますが、手軽なのは、Canvas のfilter関数を使ってグレースケールに変換する方法です。
そして、drawImage関数でCanvasにダウンスケールして描画します。
以下のような感じです。
ctx.filter = 'grayscale(100%)'; ctx.drawImage(mjpeg, 20, 0, 120, 120, 0, 0, 28, 28);
ここで、注意することは、<img>要素の160×120 pixel画像のうち、中央部分の120×120 pixel画像を切り取って、28×28 pixelにダウンスケーリングして<canvas>要素に出力していることです。
drawImageの引数で注意しなければいけないのは、 座標位置の他に高さと幅があることです。私は何度も間違えました…。
void ctx.drawImage(image, sx, sy, sWidth, sHeight, dx, dy, dWidth, dHeight);
MDNのこちらのドキュメントも参考にしてください。
画像の白黒反転と2値化
TensorFlow.jsには手軽に画像を2値化するような関数はありませんでした。
よって、HTML Canvas上で2値化と白黒反転をまとめてやることにしました。
こんな感じです。
const bin_threshold = 200; //画素2値化の閾値
let src1 = gray_canvasCtx.getImageData(0, 0, 28, 28);
let dst = bin_canvasCtx.createImageData(28, 28);
for (let i = 0; i < src1.data.length; i += 4) {
if (src1.data[i + 1] < bin_threshold) {
dst.data[i] = 255; //Red
} else {
dst.data[i] = 0;
}
dst.data[i + 1] = dst.data[i]; //Green
dst.data[i + 2] = dst.data[i]; //Blue
dst.data[i + 3] = 255; //アルファチャンネル(不透明度)
}
bin_canvasCtx.putImageData(dst, 0, 0);
getImageDataで、Canvasのグレースケール28×28画像のピクセルデータを取得します。
それには、1ピクセルに以下のように4種のデータが格納されています。
Red、Green、Blue、Alpha
Alphaは不透明度なので、255固定にします。
その他、RGBには、閾値200より下ならば255、それ以外は0として、白黒反転させて2値化します。
その後、bin_canvasに描画します。
2値化した画像を目視しやすいように120×120 pixelに引き伸ばす
先の2値化した画像は、28 x28 pixelでしたが、残念ながら小さすぎて目視が難しいです。
よって、120×120 pixelくらいの大きめの画像に引き延ばしてみました。
以下の感じです。
bin_canvas.toBlob(function(blob) {
const img_url = URL.createObjectURL(blob);
let tmp_img = new Image();
tmp_img.src = img_url;
tmp_img.onload = function() {
//アンチエイリアシング解除。(デフォルトはON)
//bin_canvasCtx.mozImageSmoothingEnabled = false;
//bin_canvasCtx.webkitImageSmoothingEnabled = false;
//bin_canvasCtx.msImageSmoothingEnabled = false;
st_canvasCtx.imageSmoothingEnabled = false;
st_canvasCtx.drawImage(tmp_img, 0, 0, 28, 28, 0, 0, 120, 120);
URL.revokeObjectURL(img_url);
};
});
drawImageで出力したCanvas画像は、デフォルトではアンチエイリアシング有効になっていますが、今回は文字をハッキリ判別したかったので、imageSmoothingEnabled関数でアンチエイリアシングを無効にしました。
コメントアウトしているところは、 Firefox ブラウザや Mac OS パソコンのための関数です。
以上、推論モデルへのデータの前処理でした。
実際に推論モデルに入力する画素データは28×28 pixel の2値化した画像データとなります。
TensorFlow.jsを使ったモデルの推論の進め方
では、TensorFlow.jsを使って前処理した画像データを学習済みモデルに入力して、推論する方法です。
JavaScriptによる TensorFlow.js インポート方法
ブラウザで動作するTensorFlow.jsライブラリのインポート方法は、公式チュートリアルのこちらに書かれています。
そこには、2021/6/28時点では、以下のソースURLでインポートするように書かれていました。
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@1.0.0/dist/tf.min.js"></script>
ただ、今回、私が組んだコードではこれでは正常に動きませんでした。
この場合、バージョンが1.0.0をロードしてしまっていることが原因のようでした。
今回、公式のこちらのAPI Referenceを参考にしてプログラミングしていて、2021/6/28時点でバージョンが3.7.0と記述されていたので変だなと思いました。
実際には、
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@3.7.0/dist/tf.min.js"></script>
とすると正常に動きました。
しかし、GitHubのこちらのページのREADMEには、以下のように書かれていました。
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs/dist/tf.min.js"></script>
ということで、バージョンを指定しないでロードした方が自動的に最新版をロードするのではないかと思われます。(たぶん…)
あとは、API Reference を参考にしてJavaScriptコードを組んでいけばよいだけです。
TensorFlow.js 関数について
今回使ったTensorFlow.jsのそれぞれの関数について簡単に説明してみます。
公式のこちらのAPI Referenceも合わせて参照してください。
tf.loadLayersModel
先ほど紹介した、tensorflowjs_converterで出力した学習済みモデルを読み込みます。
model.jsonファイルをロードします。
これは、async関数(非同期関数)内で、awaitを付加して、モデルがロードし終わるまで待つようにさせるところがポイントです。
tf.tidy
これが重要です。
普通にTensorFlow.jsを使ってJavaScriptプログラミングしたら、実はとんでもないことになります。
数分でパソコンのメモリを喰い尽くし、ブラウザ画面がブラックアウトしてしまいます。Windows10でタスクマネージャを開いて、メモリのグラフを観察していると、急激にメモリ使用量が上がって、数分後にはブラウザがブラックアウトします。私のパソコンのメモリは8GBしかなかったので、5分くらいでブラックアウトしました。
これを防ぐ方法は、公式のこちらのページのドキュメントの「メモリ」の所に記述されていました。
テンソルを早めにdisposeして解放するか、tidyを使えと書いてあります。
disposeを使ってみましたが、メモリリークは解消されなかったので、今回はtidyを使いました。
これでバッチリでした。
これは特殊な使い方ですね。
tf.browser.fromPixels
HTMLのcanvas要素に表示された画像データを読み込んでtf.TensorというTensor(テンソル)形式に変換して返します。
テンソルとは、以前、こちらの記事で少し取り上げましたが、正直、私はよくわかりません。
テンソルは単なる配列データではなく、dtypeやshape情報を含んだ複合データです。
C言語で言えば構造体、C++で言えばクラスみたいなオブジェクトです。
TensorFlow.jsの関数は殆どがこのテンソルオブジェクトで返って来ると思っておいた方が良いかと思います。
ですから、テンソルの中の値を取り出そうとして、普通の配列のように扱ってもダメなのです。
これについては、後々読み進めていくと分かって来ると思います。
28×28 pixelのCanvas要素画像を読み込み、返り値のテンソルのshape(配列要素数)は、
(28, 28, 3)
となります。
この次元の並びは、(height, width, color) です。
個人的な感覚では、width, heightという順序なのですが、これは逆ですね。
tf.unstack
先のfromPixelsから取得したデータの配列、shapeは
(28, 28, 3)
でしたが、今回使った学習モデルは白黒画像なので、単色分のデータだけあれば良いのです。
つまり、shape = (28, 28, 1) で良いのです。
よって、RGBの各成分には、先に紹介した画像の2値化で既に同じ値が代入されているので、RGBのどれか1色分を抽出すればよいのです。
ただ、それはテンソルオブジェクトなので、赤色成分を取り出そうとして、配列と同じような感覚で、bTensor[0]とするとエラーになるので要注意です。
そこで、unstackを使って各色成分を分割するわけです。
先に紹介したコードの157行目では、
let tmp = tf.unstack(bTensor, 2);
となっていて、第2引数の’2’という数値は、2番の軸、つまりshapeの3つめのカラーデータを分割するということです。
そして、大事なのは、返り値がテンソルオブジェクトの配列で返って来るというところです。これは、他の関数と違うところです。
公式のドキュメントにも、Returnのところで以下のように記載されています。
Returns: tf.Tensor[]
この括弧”[]” が見落としがちですが、単なるテンソルオブジェクトではなく、テンソルオブジェクトの配列で返って来るという意味です。
テンソルオブジェクトは値だけでなく、いろいろなデータの複合です。そのオブジェクトの配列ということは、C言語で言うと構造体の配列です。
ですから、この場合は配列の感覚で扱って、
bTensor = tmp[0];
という記述が許され、Red成分のテンソルオブジェクトを抽出できるということです。
これはちょっとややこしいですね。
tf.cast
これは整数型のテンソルデータを float 型に変換するためのものです。
tf.div
これはテンソルデータの全要素を、255で除算して、0.0~1.0までの値に正規化します。
tf.reshape
これは、学習モデルの入力の型に合わせるために、shape=(28, 28, 1)を、(1, 1, 28, 28)へ変換します。
最初の要素はバッチサイズです。
今回は1パターンのみを推論すれば良いので、バッチサイズは1です。
2番目の軸の1は、色要素です。
つまり今回の推論モデルはchannel_firstなので要注意です。
model.predict
ここで学習済みモデルを推論させます。
返り値は、要素10個の確率値配列のテンソルオブジェクトです。
確率が最大となるところの配列のインデックス値が予測値となります。
ここでの注意点は、model.predictだけを使った返り値はテンソルオブジェクトなので、ブラウザのデベロッパーツールでconsole.logを使って確率データ値を見ることが出来ません。
こんな感じです。
(図10)
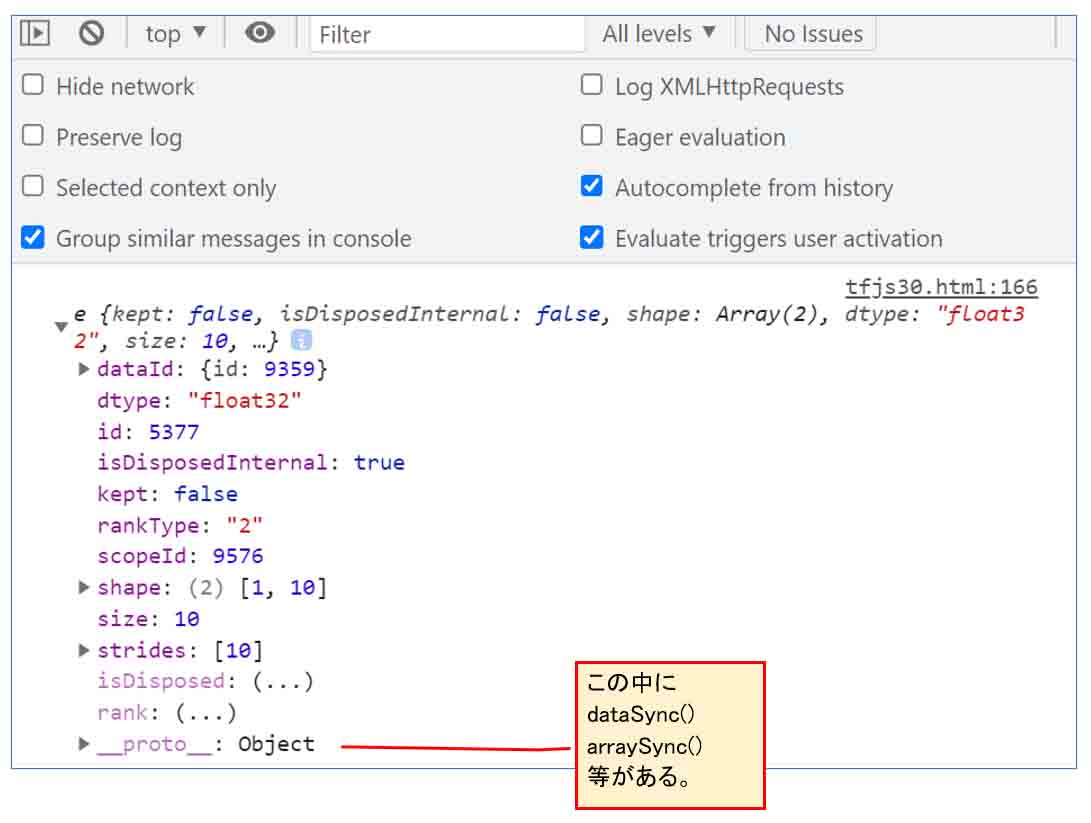
テンソルオブジェクトをデベロッパーツールで見てみた。
そこから推論結果データを抽出するためには、.dataSync() を使います。
先に紹介したコードでは、165行目にあるように、
const predictions = model.predict(bTensor).dataSync();
とすれば良いわけです。
これは、上図のように、テンソルオブジェクト内の__proto__に隠れていました。
そういえば、C言語の構造体も、値だけでなくて、関数も定義できるので、テンソルオブジェクトもそういうものなのだろうと思います。(たぶん)
そして、.dataSync()は同期関数です。
同期関数というのは、返り値が返って来るまでプログラムがそこで止まっているということです。
返り値が返って来るまで待たずに、先へ進めたいならば、.data()を使います。これは非同期関数です。
しかし、先に紹介したtidy関数で囲われている場合は、tidy関数の返り値に非同期値が使えないので、tidy関数内では同期関数を使った方が無難に思います。
この辺は素人なので間違えていたらゴメンナサイ。
因みに、.dataSync()で返ってきた値を、console.logで見てみると、こんな感じです。
(図11)
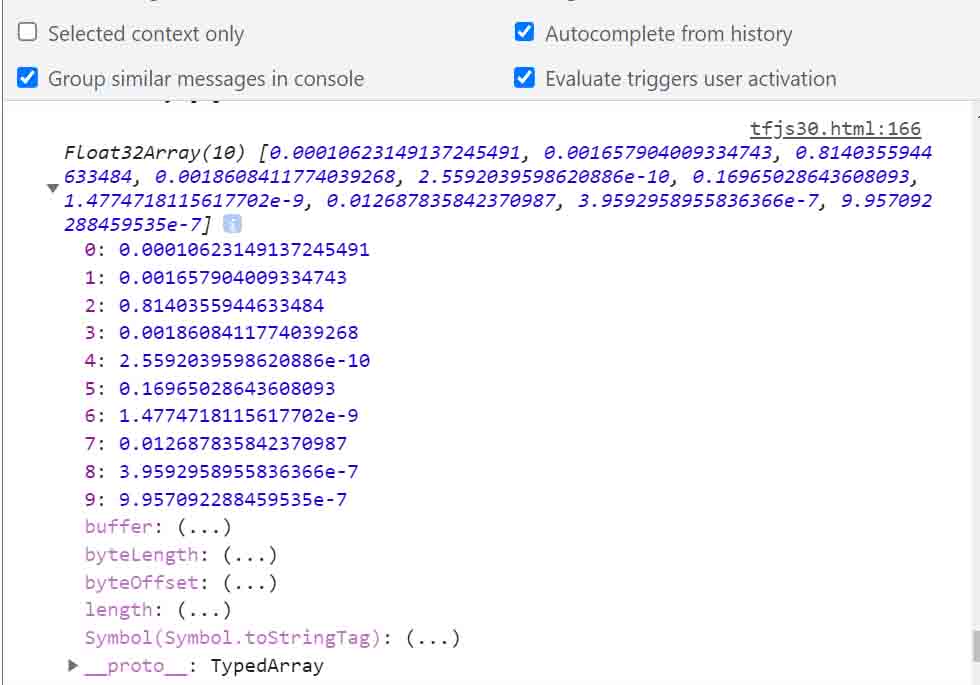
model.predict.dataSyncの返り値をデベロッパーツールで見てみた。
ちゃんと目に見える形で10個の確率値になっていますね。
ただし、これもテンソルオブジェクトだということが要注意です。
これをJavaScript上で配列の値として取得したい場合は、.arraySync()を使います。
tf.argMax
テンソルの最大値インデックス(配列要素番号)を取得する関数です。
model.predictで得た確率値配列のうち、最大値のインデックスを取得すれば、予測値となるわけです。
この関数の返り値もテンソルオブジェクトです。
.dataSync()で取得した値をconsole.logで見てみると、こんな感じです。
(図12)
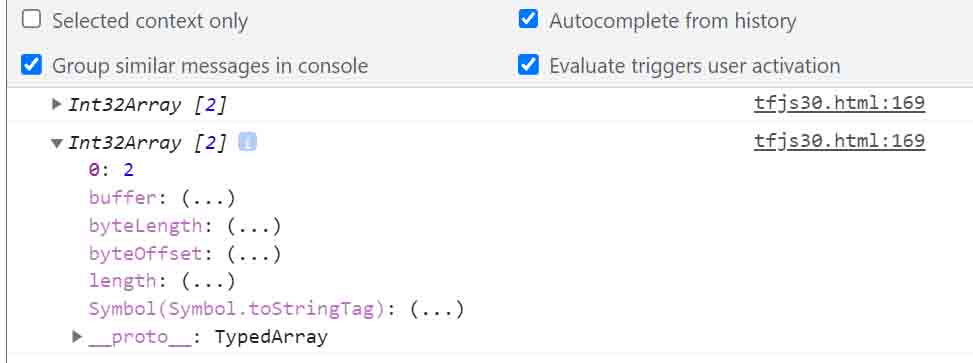
tf.argMax.dataSyncの返り値をデベロッパーツールで見てみた。
値は1つしかない配列ですが、まだテンソルオブジェクトです。
では、.arraySync()で取得した値をconsole.logで見てみると、こんな感じでした。
(図13)
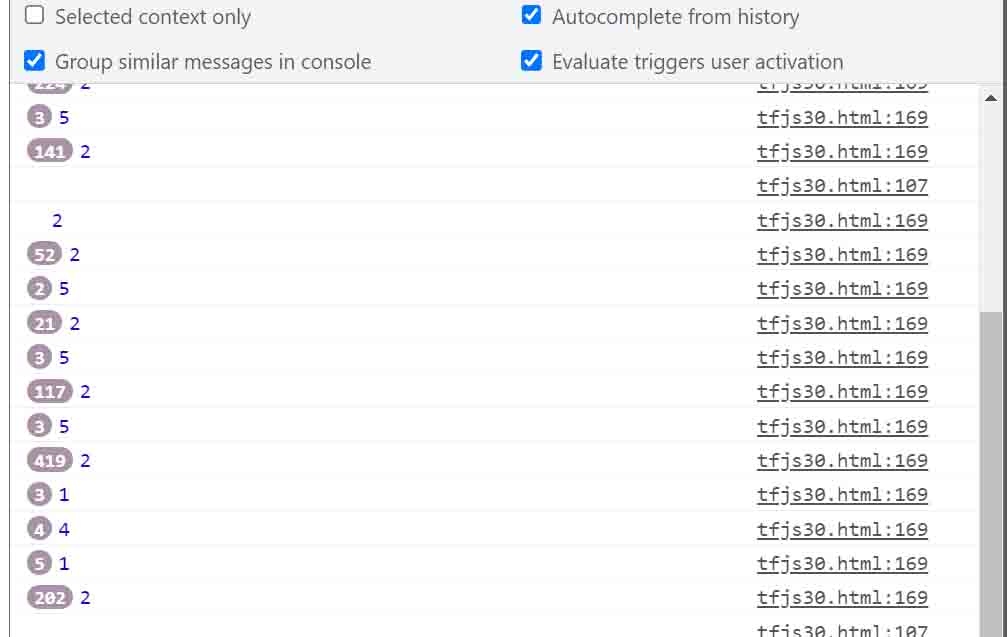
tf.argMax.arraySyncの返り値をデベロッパーツールで見てみた。
やったね!
テンソルオブジェクトから脱却して、正解データの値だけ取得できました。
.arraySync()だから、配列が表示されるのかと思いきや、配列の要素が1つしかないので、一つの値が表示されたということです。
要するに、.arraySync()を使うと、JavaScriptプログラミングでやり取りできる普通の配列データとして返って来るのです。
ここが特殊ですね。
因みにこれも非同期で取得したければ.array()で良いわけです。
あとは、これで取得した値をJavaScriptで普通にHTML表示させればよいわけです。
Canvasアニメーションについて
動画を表示させるためのCanvasアニメーションについては、以下の記事を参照してください。
M5CameraのMotion JPEG動画からJavaScriptでスナップショット静止画を取得してみた
ブラウザ上で実行
では、ブラウザ上でコードを実行してみます。
事前にM5Cameraを起動し、Wi-FiネットワークにM5Cameraを接続しておきます。
シリアルモニタに表示されているM5CameraのIPアドレスをコピーして、先に紹介したHTMLおよびJavaScriptコードに入力しておきます。
そして、ブラウザを起動し、URL入力欄に
(例)http://localhost/test-tfjs /test.html
のように入力すれば、下図の様な感じで表示されると思います。
(図20)
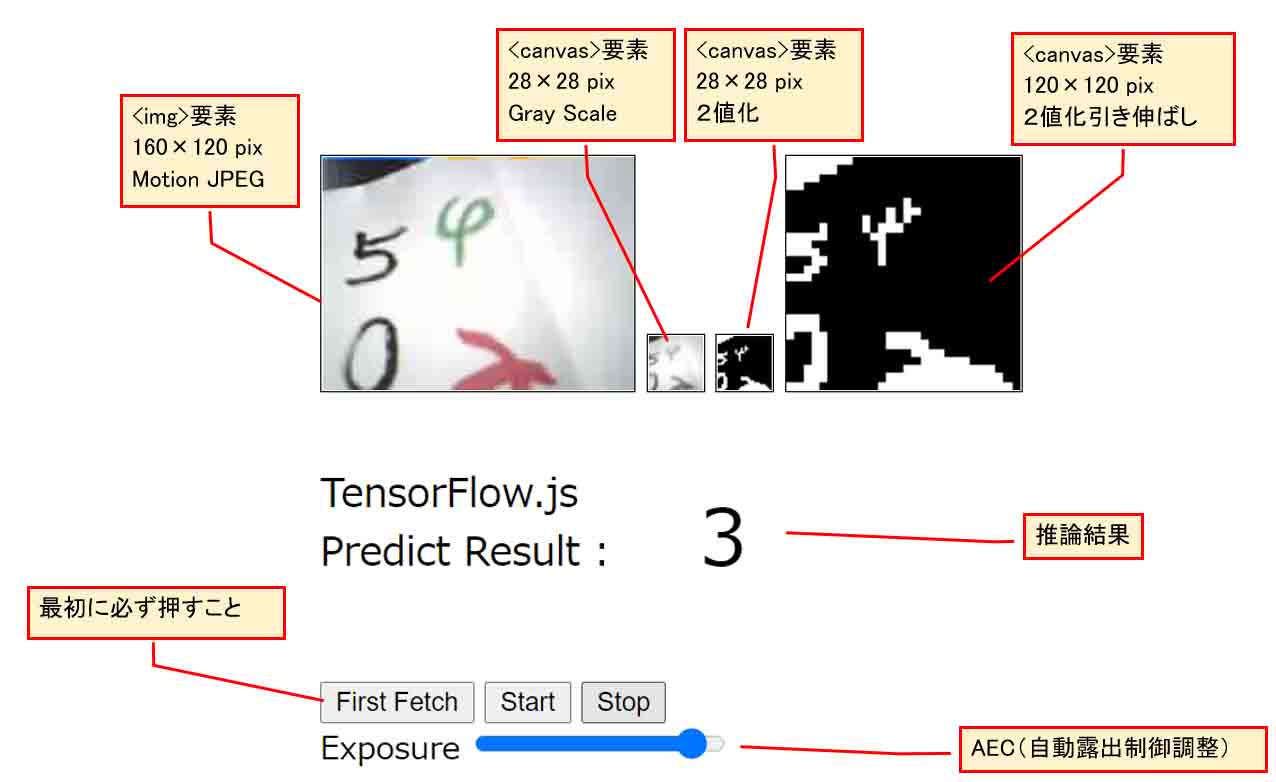
ブラウザで実行させてみた図。
左上端の<img>要素は、160×120 pixelのMotion JPEG動画ストリーミングです。
その右横は<canvas>要素で、<img>要素画像の中央の正四角形部分を切り取り、28×28 pixel にダウンスケーリングして、グレースケール(白黒)画像にしています。
その隣も<canvas>要素で、28×28 pixelの2値化画像で、白黒反転させています。
その隣の<canvas>要素は、28×28 pixelの2値化画像を拡大して、120×120 pixelにしています。見やすくするためです。
28×28 pixelの2値化画像を学習済みモデルに入力して、推論しています。
最初に紹介した動画のように、被写体の明るさによって、Exposure(露出)スライダーを操作して、M5CameraのイメージセンサOV2640の自動露出値を調整します。
あとは、最初に紹介した動画のように表示されればOKです。
TensorFlow.jsのGPU使用状況について
最初に紹介した動画にもあるように、TensorFlow.jsを使った計算では自動的にGPUを使ってくれるようです。
Windows10でGPUを積んでいるパソコンならば、タスクマネージャを起動してGPUの欄を見てみると、スタートボタンを押したときにはGPUが使われていることが分かると思います。
ただ、HTMLのCanvasだけでもGPUは使われるので、Canvas描画だけのGPU使用率と、TensorFlow.jsを使った場合のGPU使用率も比べてみました。
以下の感じです。
(図30)
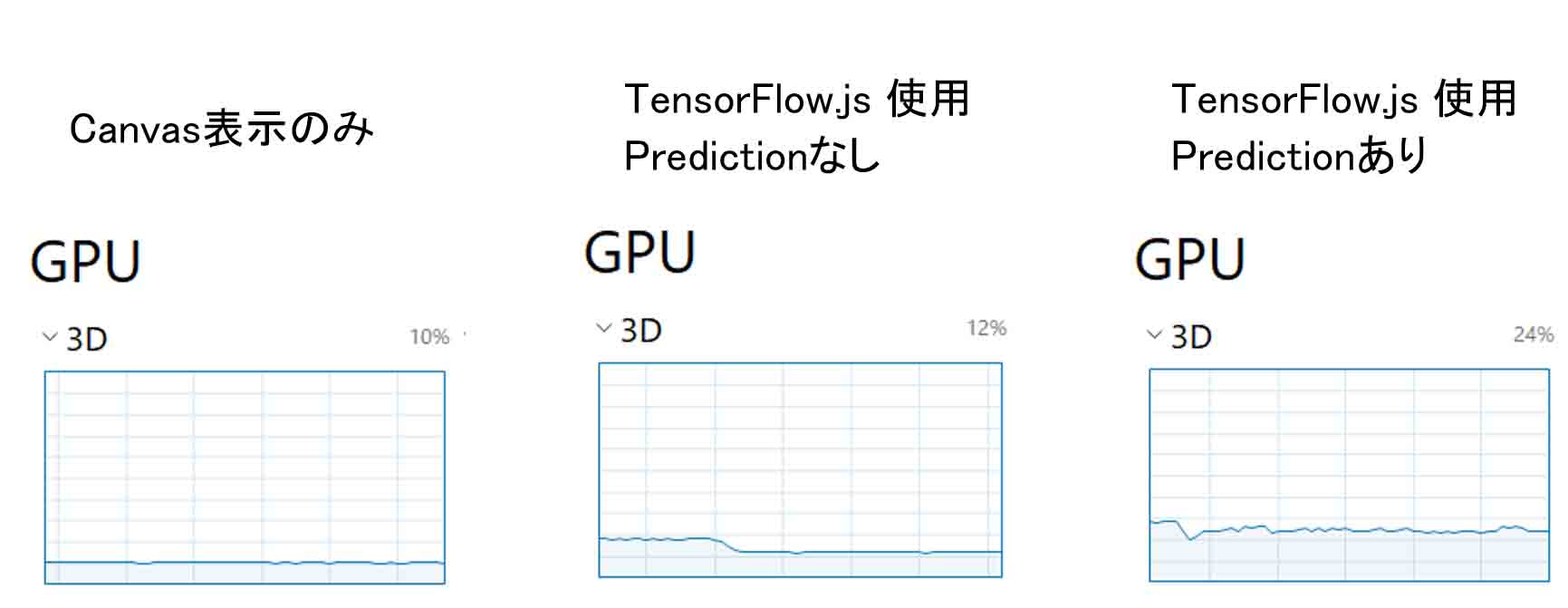
TensorFlow.js使用時のGPU使用率
このように、今回のプログラミングでは、私のパソコンのGPUでは3Dの方が消費していました。
Canvas表示だけでは10%ほどの使用率でした。
それにmodel.predict関数だけをコメントアウトして、TensorFlow.jsを使用してみると、中央にある図のように、最初の10秒程度は20%近く跳ね上がりますが、その後は12%の使用率でした。
そして、model.predict関数も使って推論してみると、常時24%ほどの使用率でした。
このことから、TensorFlow.jsによる推論はGPUを使用してくれることが分かると思います。
まとめ
以上、TensorFlow.jsを使ったリアルタイム推論の実験でした。
やはり、推論計算はブラウザに任せてしまう方が断然高速ですね。
それに、自動でGPUも使ってくれます。
私的には、TensorFlow.jsはちょっと特殊な使い方ですが、神APIだと思いました。
ただ、HTMLのCanvasである程度画像の前処理を施していた方が、認識率は高いです。
それに関しては、TensorFlow.jsを使うよりも、Canvasで処理した方が簡単でした。
これができれば、ネットワークカメラを用いたAI予測というものが自分自身で出来そうな気がします。
いずれは動体検知みたいなこともやってみたいと思っています。
というわけで、今回はここまでです。
ではまた…。
コメント